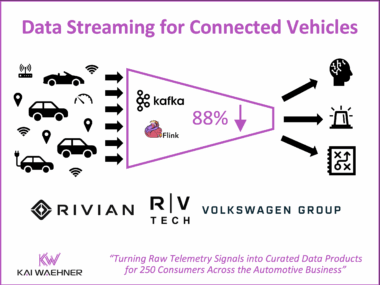
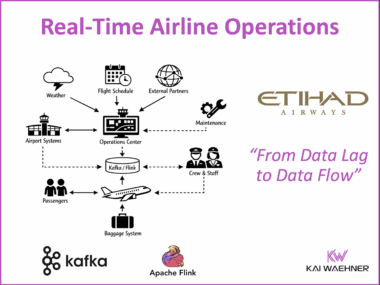
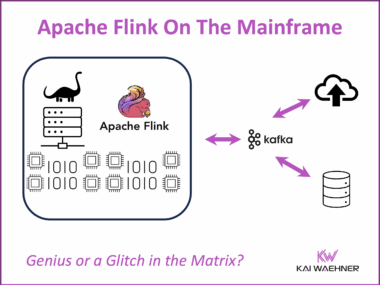
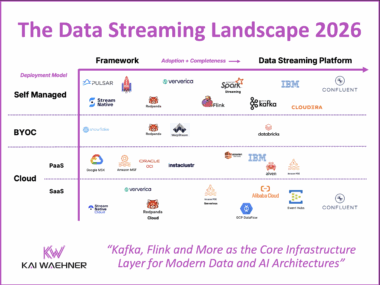
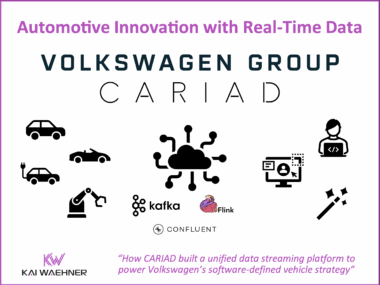
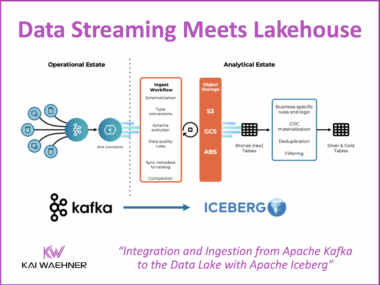
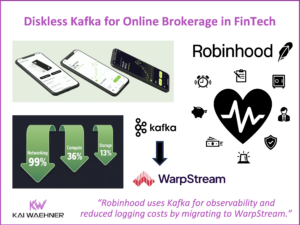
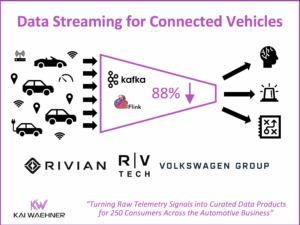
Diskless Kafka at FinTech Robinhood for Cost-Efficient Log Analytics and Observability
Diskless Kafka is transforming how fintech and financial services organizations handle observability and log analytics. By using the Kafka protocol with cloud-native object storage, companies like Robinhood reduce infrastructure costs and gain elastic scalability. This article explores how Robinhood leverages Kafka, Flink, and WarpStream to build a real-time platform that supports trading, monitoring, and compliance at scale.