Business process automation with a workflow engine or BPM suite has existed for decades. However, using the data streaming platform Apache Kafka as the backbone of a workflow engine provides better scalability, higher availability, and simplified architecture. This blog post explores the concepts behind using Kafka for persistence with stateful data processing and when to use it instead or with other tools. Case studies across industries show how enterprises like Salesforce or Swisscom implement stateful workflow automation and orchestration with Kafka.
What is a Workflow Engine for Process Orchestration?
A workflow engine is a software application that orchestrates human and automated activities. It creates, manages, and monitors the state of activities in a business process, such as the processing and approval of a claim in an insurance case, and determines the extra activity it should transition to according to defined business processes. Sometimes, such software is called an orchestration engine instead.
Workflow engines have distinct faces. Some people mainly focus on BPM suites. Others see visual coding integration tools like Dell Boomi as a workflow and orchestration engine. For data streaming with Apache Kafka, the Confluent Stream Designer enables building pipelines with a low code/no code approach.
And Business Process Management (BPM)?
A workflow engine is a core business process management (BPM) component. BPM is a broad topic with many definitions. From a technical perspective, when people talk about workflow engines or orchestration and automation of human and automated tasks, they usually mean BPM tools.
The Association of Business Process Management Professionals defines BPM as:
“Business process management (BPM) is a disciplined approach to identify, design, execute, document, measure, monitor, and control both automated and non-automated business processes to achieve consistent, targeted results aligned with an organization’s strategic goals. BPM involves the deliberate, collaborative and increasingly technology-aided definition, improvement, innovation, and management of end-to-end business processes that drive business results, create value, and enable an organization to meet its business objectives with more agility. BPM enables an enterprise to align its business processes to its business strategy, leading to effective overall company performance through improvements of specific work activities either within a specific department, across the enterprise, or between organizations.“
Tools for Workflow Automation: BPMS, ETL and iPaaS
A BPM suite (BPMS) is a technological suite of tools designed to help BPM professionals accomplish their goals. I had a talk ~10 years ago at ECSA 2014 in Vienna: “The Next-Generation BPM for a Big Data World: Intelligent Business Process Management Suites (iBPMS)“. Hence, you see how long this discussion has existed already.
I worked for TIBCO and used products like ActiveMatrix BPM and TIBCO BusinessWorks. Today, most people use open-source engines like Camunda or SaaS from cloud service providers. Most proprietary legacy BPMS I saw ten years ago do not have much presence in the enterprises anymore. And many relevant vendors today don’t use the term BPM anymore for tactical reasons 🙂
Some BPM vendors like Camunda also moved forward with fully managed cloud services or new (more cloud-native and scalable) engines like Zeebe. As a side note: I wish Camunda had built Zeebe on top of Kafka instead of building its own engine with similar characteristics. They must invest so much into scalability and reliability instead of focusing on a great workflow automation tool. Not sure if this pays off.
Traditional ETL and data integration tools fit into this category, too. Their core function is to automate processes (from a different angle). Cloud-native platforms like MuleSoft or Dell Boomi are called Integration Platform as a Service (iPaaS). I explored the differences between Kafka and iPaaS in a separate article.
This is NOT Robotic Process Automation (RPA)!
Before I look at the relationship between data streaming with Kafka and BPM workflow engines, it is essential to separate another group of automation tools: Robotic process automation (RPA).
RPA is another form of business process automation that relies on software robots. This automation technology is often seen as artificial intelligence (AI), even though it is usually a more uncomplicated automation of human tasks.
In traditional workflow automation tools, a software developer produces a list of actions to automate a task and interface to the backend system using internal APIs or dedicated scripting language.
In contrast, RPA systems develop the action list by watching the user perform that task in the application’s graphical user interface (GUI) and then perform the automation by repeating those tasks directly in the GUI. This can lower the barrier to using automation in products that might not otherwise feature APIs for this purpose.
RPA is excellent for legacy workflow automation that requires repeating human actions with a GUI. This is a different business problem. Of course, overlaps exist. For instance, Gartner’s Magic Quadrant for RPA does not just include RPA vendors like UiPath but also traditional BPM or integration vendors like Pegasystems or MuleSoft (Salesforce) that move into this business. RPA tools integrate well with Kafka. Besides that, they are out of the scope of this article as they solve a different problem than Kafka or BPM workflow engines.
Data Streaming with Kafka and BPM Workflow Engines: Friends or Enemies?
A workflow engine, respectively a BPM suite, has different goals and sweet spots compared to data streaming technologies like Apache Kafka. Hence, these technologies are complementary. No surprise that most BPM tools added support for Apache Kafka (the de facto standard for data streaming) instead of just supporting request-response integration with web service interfaces like HTTP and SOAP/WSDL, similar to any ETL tool and Enterprise Service Bus (ESB) has Kafka connectors today.
This article explores specific case studies that leverage Kafka for stateful business process orchestration. I no longer see BPM and workflow engines kicking off many new projects. Many automation tasks are done with data streaming instead of adding another engine to the stack “just for business process automation”. Still, while the techniques overlap, they are complementary. Hence, I would call it frenemies.
When to use Apache Kafka instead of BPM Suites/Workflow Engines?
To be very clear initially: Apache Kafka cannot and does not replace BPM engines! Many nuances must be evaluated to choose the right tool or combination. And I still see customers using BPM tools and integrating them with Kafka.
Camunda did a great job similar to Confluent, bringing the open source core into an enterprise solution and, finally, a fully managed cloud service. Hence, this is the number one BPM engine I see in the field; but it is not like I see it every week in customer meetings.
Kafka as the stateful data hub and BPM for human interaction
So, from my 10+ years of experience with integration and BPM engines, here is my guide for choosing the right tool for the job:
- Data streaming with Kafka became the scalable real-time data hub in most enterprises to process data and decouple applications. So, this is often the starting point for looking at a new business process’s automation, whether it is a small or high volume of data, no matter if transactional or analytical data.
- If your business process is complex and cannot easily be defined or modeled without BPMN, go for it. BPM engines provide visual coding and deployment/monitoring of the automated process. But don’t model every single business process in the enterprise. In a very agile world, time-to-market and changing business strategies all the time is not easier if too much time is spent on (outdated) diagrams. That’s not the goal of BPM, of course. But I have seen too many old, inaccurate BPMN or UML visualizations in customer meetings.
- If you don’t have Kafka yet and need just some automation of a few processes, you might start with a BPM workflow engine. However, both data streaming and BPM are strategic platforms. A simple tool like IFTTT (“If This Then That”) might do the job well for automating a few workflows with human interaction in a single domain.
- The sweet spot of a process orchestration tool is a business process that requires automated and manual tasks. The BPM workflow engine orchestrates complex human interaction in conjunction with automated processes (whether streaming/messaging interfaces, API calls, or file processing). Process orchestration tools support developers with pleasant features for generating UIs for human forms in mobile apps or web browsers.
Data Streaming as the stateful workflow engine or with another BPM tool?
TL;DR: Via Kafka as the data hub, you already access all the data on other platforms. Evaluate per use case and project if tools like Kafka Streams can implement and automate the business process or if a dedicated workflow engine is better. Both integrate very well. Often, a combination of both is the right choice.
Saying Kafka is too complex does not count anymore (in the cloud), as it is just one click away via fully managed and supported pay-as-you-go with SaaS offerings like Confluent Cloud.
In this blog, I want to share a few stories where the stateful workflows were automated natively with data streaming using Kafka and its ecosystem, like Kafka Connect and Kafka Streams.
To learn more about BPM case studies, look at Camunda and similar vendors. They provide excellent success case studies, and some use cases combine the workflow engine with Kafka.
Apache Kafka as Workflow and Orchestration Engine
Apache Kafka focuses on data streaming, i.e., real-time data integration and stream processing. However, the core functionality of Kafka includes database characteristics like persistence, high availability, guaranteed ordering, transaction APIs, and (limited) query capabilities. Kafka is some kind of database but does not try to replace others like Oracle, MongoDB, Elasticsearch, et al.
Apache Kafka as stateful and reliable persistence layer
Some of Kafka’s functionalities enable implementing the automation of workflows. This includes stateful processing:
- The distributed commit log provides persistence, reliability, and guaranteed ordering. Tiered Storage (only available via some vendors or cloud services today) makes long-term storage of big data cost-efficient and scalable.
- The replayability of historical data is crucial to rewind events in case of a failure or other issues within the business process. Timestamps of events, in combination with a clever design of the Kafka Topics and related Partitions, allow the separation of concerns.
- While a Kafka topic is the source of truth for the entire history with guaranteed ordering, a compacted topic can be used for quick lookups of the current, updated state. This combination enables the storage of information forever and updates to existing information with the updated state. Plus, querying the data via key/value request.
- Stream processing with Kafka Streams or KSQL allows keeping the current state of a business process in the application, even long-term, over months or years. Interactive queries on top of the streaming applications allow API queries against the current state in microservices (as an application-centric alternative to using compacted topics).
- Kafka Connect with connectors to cloud-native SaaS and legacy systems, clients for many programming languages (including Java, Python, C++, or Go), and other API interfaces like the REST Proxy integrate with any data source or data sink required for business process automation.
- The Schema Registry ensures the enforcement of API contracts (= schemas) in all event producers and consumers.
- Some Kafka distributions and cloud services add data governance, policy enforcement, and advanced security features to control data flow and privacy/compliance concerns.
The Saga Design Pattern for Stateful Orchestration with Kafka
Apache Kafka supports exactly-once semantics and transactions in Kafka. Transactions are often required for automating business processes. However, a scalable cloud-native infrastructure like Kafka does not use XA transactions with the two-phase commit protocol (like you might know from Oracle and IBM MQ) if separate transactions in different databases need to be executed. This does not scale well. Therefore, this is no option.
Learn more about transactions in Kafka (including the trade-offs) in a dedicated blog post: “Apache Kafka for Big Data Analytics AND Transactions“.
Sometimes, another alternative is needed for workflow automation with transaction requirements. Welcome to a merging design pattern that originated with microservice architectures: The SAGA design pattern is a crucial concept for implementing stateful orchestration if one transaction in the business process spans multiple applications or service calls. SAGA pattern enables an application to maintain data consistency across multiple services without using distributed transactions.
Instead, the SAGA pattern uses a controller that starts one or more “transactions” (= regular service calls without transaction guarantee) and only continues after all expected service calls return the expected response:
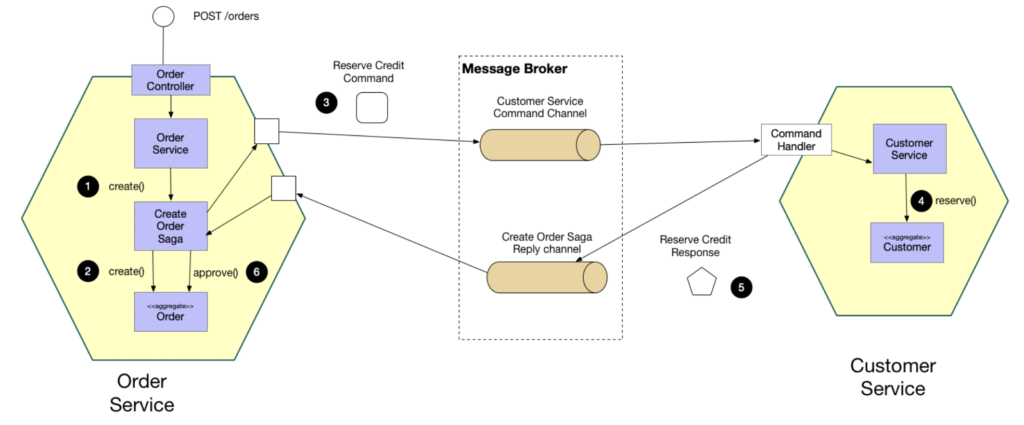
- The
Order Servicereceives thePOST /ordersrequest and creates theCreate Ordersaga orchestrator - The saga orchestrator creates an
Orderin thePENDINGstate - It then sends a
Reserve Creditcommand to theCustomer Service - The
Customer Serviceattempts to reserve credit - It then sends back a reply message indicating the outcome
- The saga orchestrator either approves or rejects the
Order
Find more details from the above example at microservices.io’s detailed explanation of the SAGA pattern.
Case studies for workflow automation and process orchestration with Apache Kafka
Reading the above sections, you should better understand Kafka’s persistence capabilities and the SAGA design pattern. Many business processes can be automated at scale in real-time with the Kafka ecosystem. There is no need for another workflow engine or BPM suite.
Learn from interesting real-world examples of different industries:
- Digital Native: Salesforce
- Financial Services: Swisscom
- Insurance: Mobiliar
- Open Source Tool: Kestra
Salesforce: Web-scale Kafka Workflow Engine
Salesforce built a scalable real-time workflow engine powered by Kafka.
Why? The company recommends to “use Kafka to make workflow engines more reliable”.
At Current 2022, Salesforce presented their project for workflow and process automation with a stateful Kafka engine. I highly recommend checking out the entire talk, or at least the slide deck.
Salesforce introduced a workflow engine concept that only uses Kafka to persist state transitions and execution results. The system banks on Kafka’s high reliability, transactionality, and high scale to keep setup and operating costs low. The first target use case was the Continuous Integration (CI) systems.
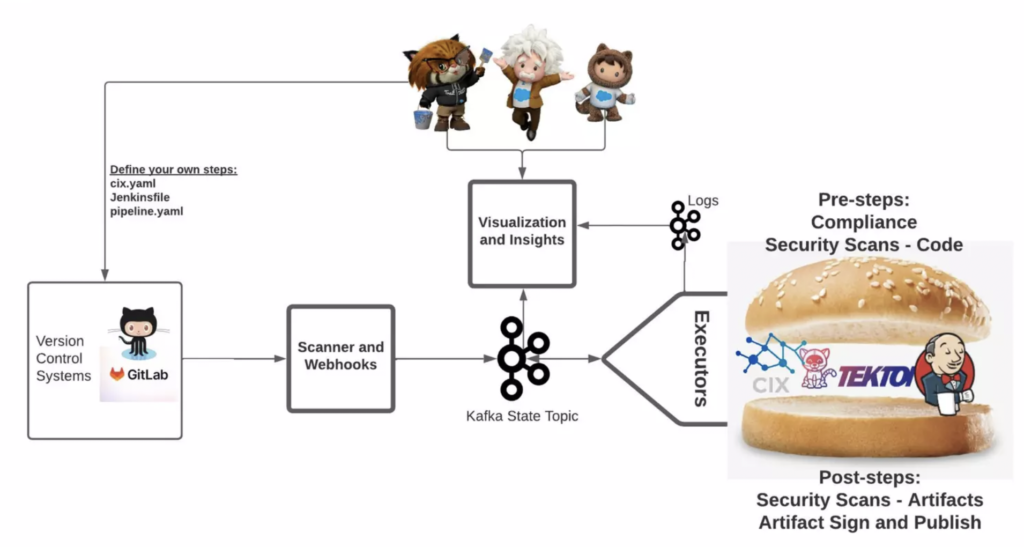
A demo of the system presented:
- Parallel and nested CI workflow definitions of varying declaration formats
- Real-time visualization of progress with the help of Kafka.
- Chaos and load generation to showcase how retries and scale-ups work.
- Extension points
- Contrasting the implementation to other popular workflow engines
Here is an example of the workflow architecture:
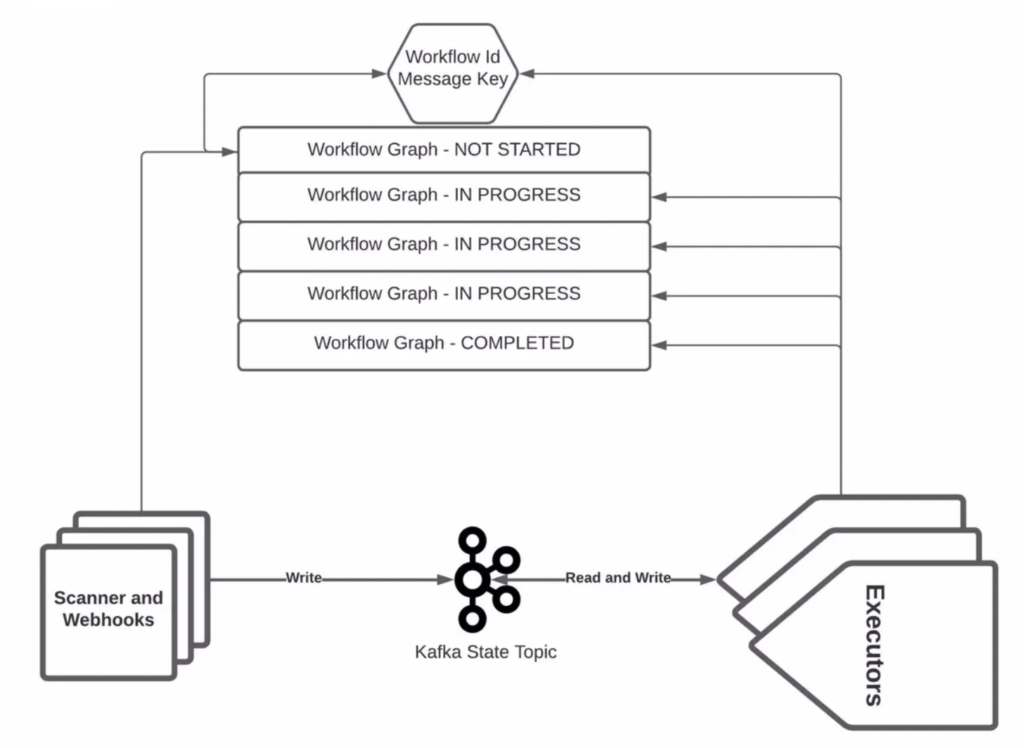
Compacted topics as the backbone of the stateful workflow engine
TL;DR of Salesforce’s presentation: Kafka is a viable choice as the persistence layer for problems where you have to do state machine processing.
A few notes on the advantages Salesforce pointed out for using Kafka instead of other databases or CI/CD tools:
- The only stateful component is Kafka -> Dominating reliability setup
- Kafka was chosen as the persistence layer -> SLAs / reliability better than with a database/sharded Jenkings/NoSQL -> Four nines (+ horizontal scaling) instead of three nines (see slide “reliability contrast”)
- Restart K8S clusters and CI workflows again easily
- Kafka State Topic -> Store the full workflow graph in each message (workflow Protobuf with defined schemas)
- Compacted Topic updates states: not started, running, complete -> Track, manage, and count state machine transitions
The Salesforce implementation is open source and available on Github: “Junction Workflow is an upcoming workflow engine that uses compacted Kafka topics to manage state transitions of workflows that users pass into it. It is designed to take multiple workflow definition formats.”
Swisscom Custodigit: Secure crypto investments with stateful data streaming and orchestration
Custodigit is a modern banking platform for digital assets and cryptocurrencies. It provides crucial features and guarantees for seriously regulated crypto investments:
- Secure storage of wallets
- Sending and receiving on the blockchain
- Trading via brokers and exchanges
- Regulated environment (a key aspect and no surprise as this product is coming from the Swiss; a very regulated market)
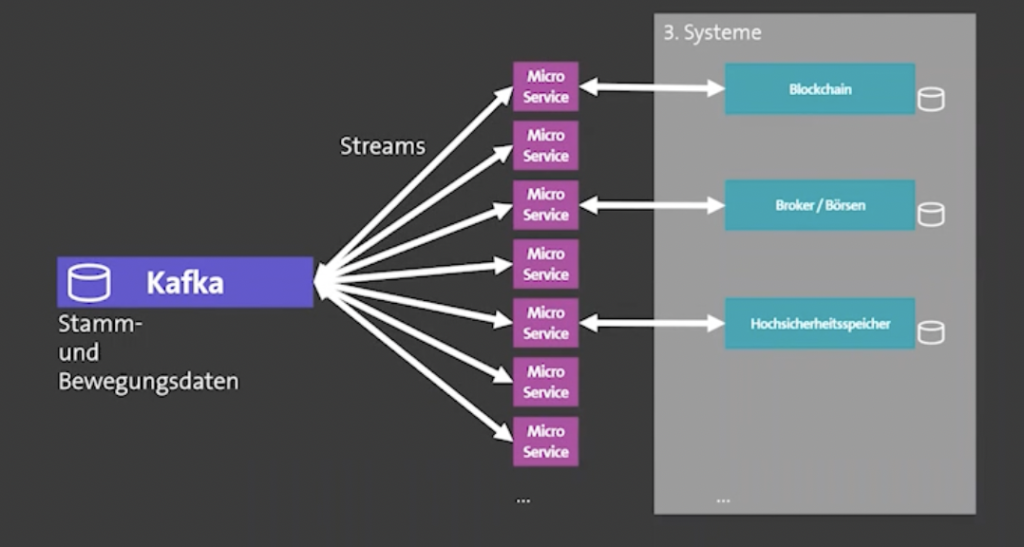
The following architecture diagrams are only available in Germany, unfortunately. But I think you get the points. With the SAGA pattern, Custodigit leverages Kafka Streams for stateful orchestration.
The Custodigit microservice architecture uses microservices to integrate with financial brokers, stock markets, cryptocurrency blockchains like Bitcoin, and crypto exchanges:
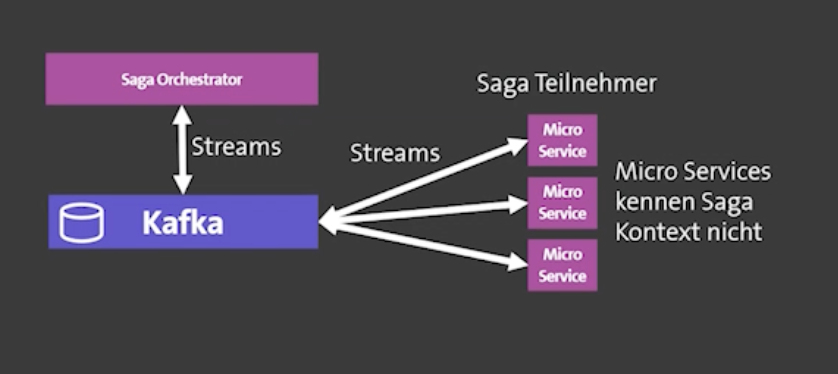
Custodigit implements the SAGA pattern for stateful orchestration. Stateless business logic is truly decoupled, while the saga orchestrator keeps the state for choreography between the other services:
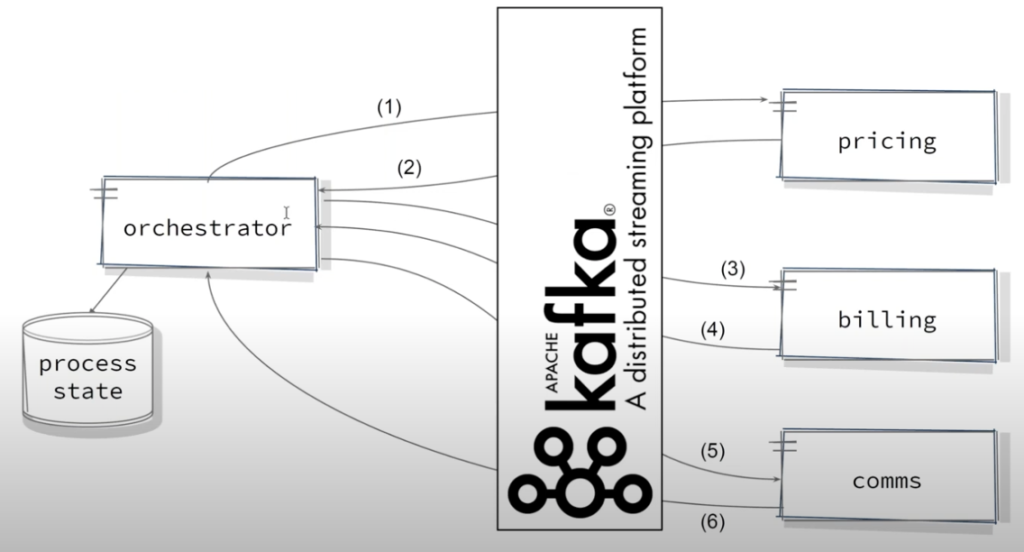
Swiss Mobiliar: Decoupling and workflow orchestration
Swiss Mobiliar (Schweizerische Mobiliar, aka Die Mobiliar) is the oldest private insurer in Switzerland. Event Streaming powered by Apache Kafka with Kafka supports various use cases at Swiss Mobiliar:
- Orchestrator application to track the state of a billing process
- Kafka as database and Kafka Streams for data processing
- Complex stateful aggregations across contracts and re-calculations
- Continuous monitoring in real-time
Mobiliar’s architecture shows the decoupling of applications and orchestration of events:
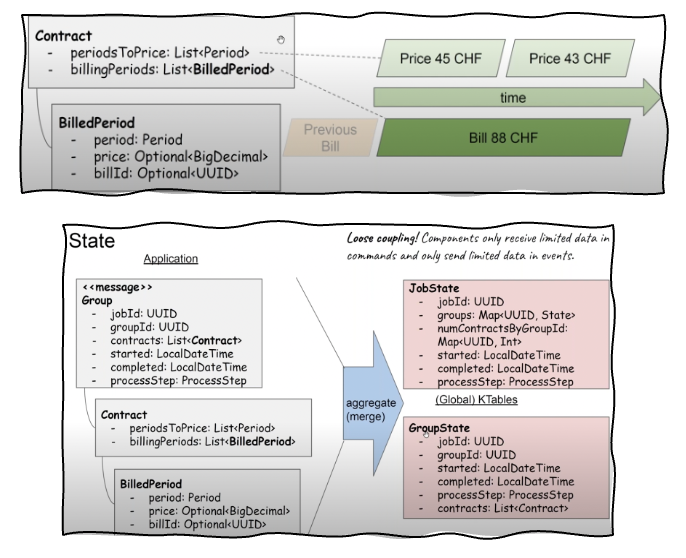
Here you can see the data structures and states defined in API contracts and enforced via the Schema Registry:
Also, check out the on-demand webinar with Mobiliar and Spoud to learn more about their Kafka usage.
Kestra: Open-source Kafka workflow engine and scheduling platform
Kestra is an infinitely scalable orchestration and scheduling platform, creating, running, scheduling, and monitoring millions of complex pipelines. The project is open-source and available on GitHub:
- 🔀 Any kind of workflow: Workflows can start simple and progress to more complex systems with branching, parallel, dynamic tasks, flow dependencies
- 🎓 Easy to learn: Flows are in simple, descriptive language defined in YAML—you don’t need to be a developer to create a new flow.
- 🔣 Easy to extend: Plugins are everywhere in Kestra, many are available from the Kestra core team, but you can create one easily.
- 🆙 Any triggers: Kestra is event-based at heart—you can trigger an execution from API, schedule, detection, events
- 💻 A rich user interface: The built-in web interface allows you to create, run, and monitor all your flows—no need to deploy your flows, just edit them.
- ⏩ Enjoy infinite scalability: Kestra is built around top cloud native technologies—scale to millions of executions stress-free.
This is an excellent project with a cool drag & drop UI:
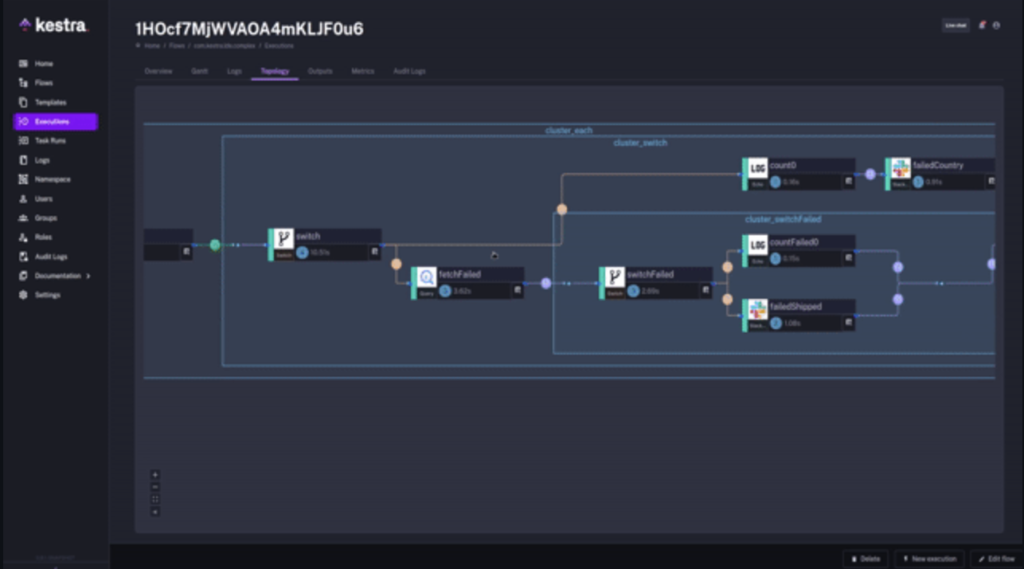
I copied the description from the project. Please check out the open-source project for more details.
What about Apache Flink for streaming workflow orchestration and BPM?
This post covered various case studies for the Kafka ecosystem as a stateful workflow orchestration engine for business process automation. Apache Flink is a stream processing framework that complements Kafka and sees significant adoption.
The above case studies used Kafka Streams as the stateful stream processing engine. It is a brilliant choice if you want to embed the workflow logic into its own application/microservice/container.
Apache Flink has other sweet spots: Powerful stateful analytics, unified batch and real-time processing, ANSI SQL support, and more. In a detailed blog post, I explored the differences between Kafka Streams and Apache Flink for stream processing.
Apache Flink for Complex Event Processing (CEP) and cross-cluster queries
The following differentiating features make Flink an excellent choice for some workflows:
- Complex Event Processing (CEP): CEP generates new events to trigger action based on situations it detects across multiple event streams with events of different types (situations that build up over time and space). Event Stream Processing (ESP) detects patterns over event streams with homogenous events (i.e., patterns over time). The powerful pattern API of FlinkCEP allows you to define complex pattern sequences you want to extract from your input stream to detect potential matches.
- “Read once, write many”: Flink allows different analytics without readying the Kafka topic several times. For instance, two queries on the same Kafka Topic like “CTAS .. * FROM mytopic WHERE eventType=1” and “CTAS .. * FROM mytopic WHERE eventType=2” can be grouped together. The query plan will only do one read. This fundamentally differs from Kafka-native stream processing engines like Kafka Streams or KQL.
- Cross-cluster queries: Data processing across different Kafka topics of independent Kafka clusters of different business units is a new kind of opportunity to optimize and automate an existing end-to-end business process. Be careful when using this feature wisely, though. It can become an anti-pattern in the enterprise architecture and create complex and unmanageable “spaghetti integrations”.
Should you use Flink as a workflow automation engine? It depends. Flink is great for stateful calculations and queries. The domain-driven design enabled by data streaming enables choosing the right technology for each business problem. Evaluate Kafka Streams, Flink, BPMS, and RPA. Combine them as it makes the most sense from a business perspective, cost, time to market, and enterprise architecture. A modern data mesh abstracts the technology behind each data product. Kafka as the heart decouples the microservices and provides data sharing in real-time.
Kafka as Workflow Engine or with other Orchestration Tools
BPMN or similar flowcharts are great for modeling business processes. Business and technical teams easily understand the visualization. It documents the business process for later changes and refactoring. Various workflow engines solve the automation: BPMS, RPA tools, ETL and iPaaS data integration platforms, or data streaming.
The blog post explored several case studies where Kafka is used as a scalable and reliable workflow engine to automate business processes. This is not always the best option. Human interaction, long-running processes, or complex workflow logic are signs to choose a dedicated tool may be better. Ensure understanding of the underlying design pattern like SAGA, evaluate dedicated orchestration and BPM engines like Camunda, and choose the right tool for the job.
Combining data streaming and a separate workflow engine is sometimes best. However, the impressive example of Salesforce proved Kafka could and should be used as a scalable, reliable workflow and stateful orchestration engine for the proper use cases. Fortunately, modern enterprise architecture concepts like microservices, data mesh, and domain-driven design allow you to choose the right tool for each problem. For instance, in some projects, Apache Flink might be a terrific add-on for challenges that require Complex Event Processing to automate the stateful workflow.
How do you implement business process automation? What tools do you use with or without Kafka? Let’s connect on LinkedIn and discuss it! Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter.