Artificial Intelligence (AI) and Machine Learning (ML) are transforming business operations by enabling systems to learn from data and make intelligent decisions for predictive and generative AI use cases. Two essential components of AI/ML are model training and inference. Models are developed and refined using historical data. Model inference is the process of using a trained machine learning models to make predictions or generate outputs based on new, unseen data. This blog post covers the basics of model inference, comparing different approaches like remote and embedded inference. It also explores how data streaming with Apache Kafka and Flink enhances the performance and reliability of these predictions. Whether for real-time fraud detection, smart customer service applications, or predictive maintenance, understanding the value of data streaming for model inference is crucial for leveraging AI/ML effectively.

Artificial Intelligence (AI) and Machine Learning (ML)
Artificial Intelligence (AI) and Machine Learning (ML) are pivotal in transforming how businesses operate by enabling systems to learn from data and make informed decisions. AI is a broad field that includes various technologies aimed at mimicking human intelligence, while ML is a subset focused on developing algorithms that allow systems to learn from data and improve over time without being explicitly programmed. The major use cases are predictive AI and generative AI.
AI/ML = Model Training, Model Deployment and Model Inference
In AI/ML workflows, model training, model deployment and model inference are distinct yet interconnected processes:
- Model Training: Using historical data or credible synthetic to build a model that can recognize patterns and make predictions. It involves selecting the right algorithm, tuning parameters, and validating the model’s performance. Model training is typically resource intensive and performed in a long-running batch process, but can be via online learning or incremental learning, too.
- Model Deployment: The trained model is deployed to the production environment, which could be cloud (e.g., AWS, Google Cloud, Azure or purpose-built SaaS offerings), edge devices (local devices or IoT for embedded inference), or on-premises servers (local servers for sensitive data or compliance reasons). If the demand is high, load balancers distribute requests across multiple instances to ensure smooth operation.
- Model Inference: Once a model is trained, it is deployed to make predictions on new, unseen data. Model inference, often just called making a prediction, refers to this process. During inference, the model applies the patterns and knowledge it learned during model training to provide results.
For the terminology, keep in mind that model inference is generating predictions using a trained model, while model scoring (which is sometimes wrongly used as a synonym) involves evaluating the accuracy or performance of those predictions.
Batch vs. Real-Time Model Inference
Model inference can be done in real-time or batch mode, depending on the application’s requirements. When making predictions in production environments, the requirements often differ from model training because timely, accurate, and robust predictions are needed. The inference process involves feeding input data into the model and getting an output, which could be a classification, regression value, or other prediction types.
There are two primary delivery approaches to model inference: Remote Model Inference and Embedded Model Inference. Each deployment option has its trade-offs. The right choice depends on requirements like latency (real-time vs. batch) but also on other characteristics like robustness, scalability, cost, etc.
Remote Model Inference
Remote Model Inference involves making a request-response call to a model server via RPC, API, or HTTP. While this approach allows for centralized model management and easier updates, it can introduce latency because of network communication. It is suitable for scenarios where model updates are frequent, and the overhead of network calls is acceptable.
The service creation exposes the model through an API, so applications or other systems can interact with it for predictions. It can be a technical interface with all the details about the model or a function that hides the AI/ML capabilities under the hood of a business service.
Pros:
- Centralized Model Management: Models are deployed and managed on a central server, making it easier to update, A/B test, monitor, and version them with no need to change the application.
- Scalability: Remote inference can leverage the scalability of cloud infrastructure. This allows services to handle large volumes of requests by distributing the load across multiple servers.
- Resource Efficiency: The client or edge devices do not need to have the computational resources to run the model, which is beneficial for devices with limited processing power.
- Security: Sensitive models and data remain on the server, which can be more secure than distributing them to potentially insecure or compromised edge devices.
- Ease of Integration: Remote models can be accessed via APIs, making it easier to integrate with different applications or services
Cons:
- Latency: Remote inference typically involves network communication, which can introduce latency, especially if the client and server are geographically distant.
- Dependency on Network Availability: The inference depends on the availability and reliability of the network. Any disruption can cause failed predictions or delays.
- Higher Operational Costs: Running and maintaining a remote server or cloud service can be expensive, particularly for high-traffic applications.
- Data Privacy Concerns: Sending data to the server for inference may raise privacy concerns, especially in regulated industries or when dealing with sensitive information.
Embedded Model Inference
In this approach, the model is embedded within the stream processing application. This reduces latency as predictions are made locally within the application, but it may require more resources on the processing nodes. Embedded inference is ideal for applications where low latency is critical, and model updates are less frequent.
Pros:
- Low Latency: Since the model runs directly on the device, there is a minimal delay in processing, leading to near real-time predictions.
- Offline Availability: Embedded models do not rely on a network connection, making them ideal for scenarios where connectivity is intermittent or unavailable.
- Cost Efficiency: Once deployed, there are no ongoing costs related to server maintenance or cloud usage, making it more cost-effective.
- Privacy: Data stays local to the device, which can help in adhering to privacy regulations and minimizing the risk of data breaches.
- Independence from Central Infrastructure: Embedded models are not reliant on a central server, reducing the risk of a single point of failure.
Cons:
- Resource Intensive: Embedded scoring requires sufficient computational resources. While hosting and running the model on servers or containers is the expensive part, models also need to be adjusted and optimized for a more lightwight deployment on devices with limited processing power, memory, or battery life.
- Complex Deployment: Updating models across many devices can be complex and require robust version management strategies.
- Model Size Limitations: There may be constraints on model complexity and size because of the limited resources on the edge device, potentially leading to the need for model compression or simplification.
- Security Risks: Deploying models on devices can expose them to reverse engineering, tampering, or unauthorized access, potentially compromising the model’s intellectual property or functionality.
Hidden Technical Debt in AI/ML Systems
The Google paper “Hidden Technical Debt in Machine Learning Systems” sheds light on the complexities involved in maintaining AI/ML systems. It argues that, while the focus is often on the model itself, the surrounding infrastructure, data dependencies, and system integration can introduce significant technical debt. This debt manifests as increased maintenance costs, reduced system reliability, and challenges in scaling and adapting the system.
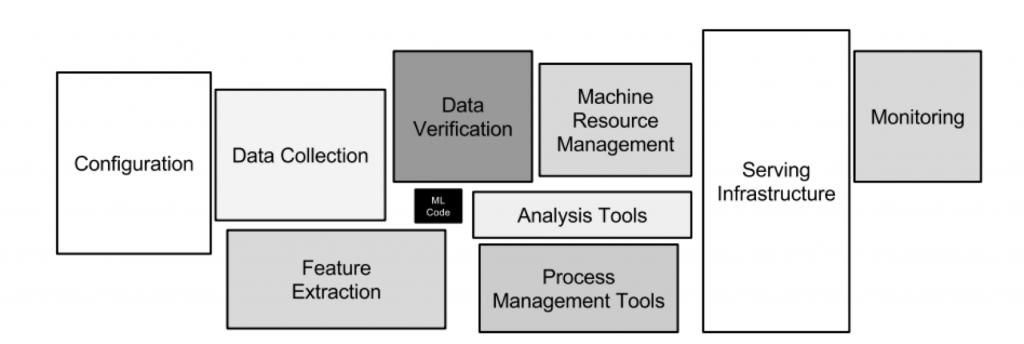
Important points from the paper include:
- Complexity in Data Dependencies: AI/ML systems often rely on multiple data sources, each with its own schema and update frequency. Managing these dependencies can be challenging and error-prone.
- Systems Integration Challenges: Integrating ML models into existing systems requires careful consideration of interfaces, data formats, and communication protocols.
- Monitoring and Maintenance: Continuous monitoring and maintenance are essential to ensure model performance does not degrade over time because of changes in data distribution or system behavior.
The Impedance Mismatch within AI/ML between Analytics and Operations
The impedance mismatch between the operational estate (production engineers) and the analytical estate (data scientists/data engineers) primarily stems from their differing toolsets, workflows and SLA requirements regarding uptime, latency and scalability.
Production engineers often use Java or other JVM-based languages to build robust, scalable applications, focusing on performance and reliability. They work in environments that emphasize code stability, using tools like IntelliJ IDEA and frameworks that support CI/CD and containerization.
In contrast, data scientists and data engineers typically use Python because of its simplicity and the rich ecosystem of data science libraries. They often work in interactive environments like Jupyter Notebooks, which are geared towards experimentation and rapid prototyping rather than production-level code quality.
This mismatch can create challenges in integrating machine learning models into production environments. Production engineers prioritize performance optimization and scalability, while data scientists focus on model accuracy and experimentation. To bridge this gap, organizations can form cross-functional teams, adopt a data streaming platform like Apache Kafka, develop standardized APIs for model deployment, and provide training to align the skills and priorities of both groups. By doing so, they can streamline the deployment of machine learning models, ensuring they deliver business value effectively.
AI/ML in Practice: Use Cases across Industries for Model Inference
Many use cases for model inference are critical and require real-time processing and high reliability to ensure timely and accurate decision-making in various industries. A few examples of critical predictive AI and generative AI use cases are:
Use Cases for Predictive AI
Many predictive AI use cases are already in production across industries. For instance:
- Fraud Detection: Real-time model inference can identify fraudulent transactions as they occur, allowing for immediate intervention. By analyzing transaction data in real-time, businesses can detect anomalies and flag suspicious activities before they result in financial loss.
- Predictive Maintenance: By analyzing sensor data in real-time, organizations can predict equipment failures and schedule maintenance proactively. This approach reduces downtime and maintenance costs by addressing issues before they lead to equipment failure.
- Customer Promotions: Retailers can offer personalized promotions to customers while they are still in the store or using a mobile app, enhancing the shopping experience. Real-time inference allows businesses to analyze customer behavior and preferences on the fly, delivering targeted offers that increase engagement and sales.
Use Cases for Generative AI
Early adoption use cases with user-facing value:
- Semantic Search: Generative AI enhances semantic search by understanding the context and intent behind user queries, enabling more accurate and relevant search results. It leverages advanced language models to interpret nuanced language patterns, improving the search experience by delivering content that closely aligns with user needs.
- Content Generation: GenAI, exemplified by tools like Microsoft Co-pilot, assists users by automatically creating text, code, or other content based on user prompts, significantly boosting productivity. It utilizes machine learning models to generate human-like content, streamlining tasks such as writing, coding, and creative projects, thereby reducing the time and effort required for content creation.
More advanced use cases with transactional implications that take a bit longer to adopt because of its business impact and technical complexity:
- Ticket Rebooking: In the airline industry, generative AI can assist customer service agents in rebooking tickets by providing real-time, context-specific recommendations based on flight availability, customer preferences, and loyalty status. This transactional use case ensures that agents can offer personalized and efficient solutions, enhancing customer satisfaction and operational efficiency.
- Customer Support: For a SaaS product, generative AI can analyze customer support interactions to identify common issues and generate insightful reports that highlight trends and potential areas for improvement. This analysis assists companies in resolving common issues, refining their support procedures, and enhancing the overall user satisfaction.
So, after all the discussions about AI/ML, what is the relation to data streaming specifically for model inference?
Data Streaming with Apache Kafka and Flink for Model Inference
A data streaming platform helps to enhance model inference capabilities. Apache Kafka and Flink provide a robust infrastructure for processing data in motion, enabling real-time predictions with low latency.
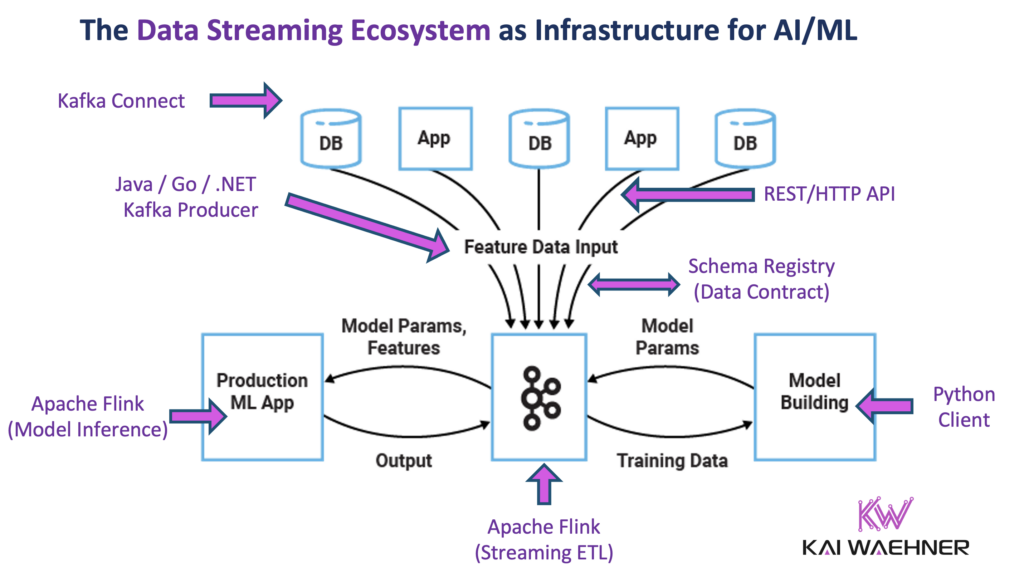
The benefits of using data streaming for model inference include:
- Low Latency: Real-time stream processing ensures that predictions are made quickly, which is crucial for time-sensitive applications. Kafka and Flink handle high-throughput, low-latency data streams. This makes them ideal for real-time inference.
- Scalability: Kafka and Flink can handle large volumes of data, making them suitable for applications with high throughput requirements. They can scale horizontally by adding more nodes to the cluster to ensure that the system can handle increasing data loads. A serverless data streaming cloud service like Confluent Cloud even provides complete elasticity and takes over the (complex) operations burden.
- Robustness: These platforms are fault-tolerant, ensuring continuous operation even in the face of failures. They provide mechanisms for data replication, failover, and recovery, which are essential for maintaining system reliability. This can even span multiple regions or different public clouds like AWS, Azure, GCP, and Alibaba.
- Critical SLAs: Kafka and Flink support stringent service level agreements (SLAs) for uptime and performance, which are essential for critical applications. They offer features like exactly-once processing semantics with a Transaction API and stateful stream processing. These capabilities are crucial for maintaining data integrity and consistency.
Remote vs. Embedded Model Inference with Kafka and Flink
Let’s explore concrete examples for model inference with the embedded and remote call approaches.
Remote Model Inference with Kafka, Flink and OpenAI
Here is an example with Kafka, Flink and OpenAI using the ChatGPT large language model (LLM) for generative AI. The process involves using Apache Kafka and Flink for stream processing to correlate real-time and historical data, which is then fed into the OpenAI API via a Flink SQL User Defined Function (UDF) to generate context-specific responses using the ChatGPT large language model. The generated responses are sent to another Kafka topic for downstream applications, such as ticket rebooking or updating loyalty platforms, ensuring seamless integration and real-time data processing.
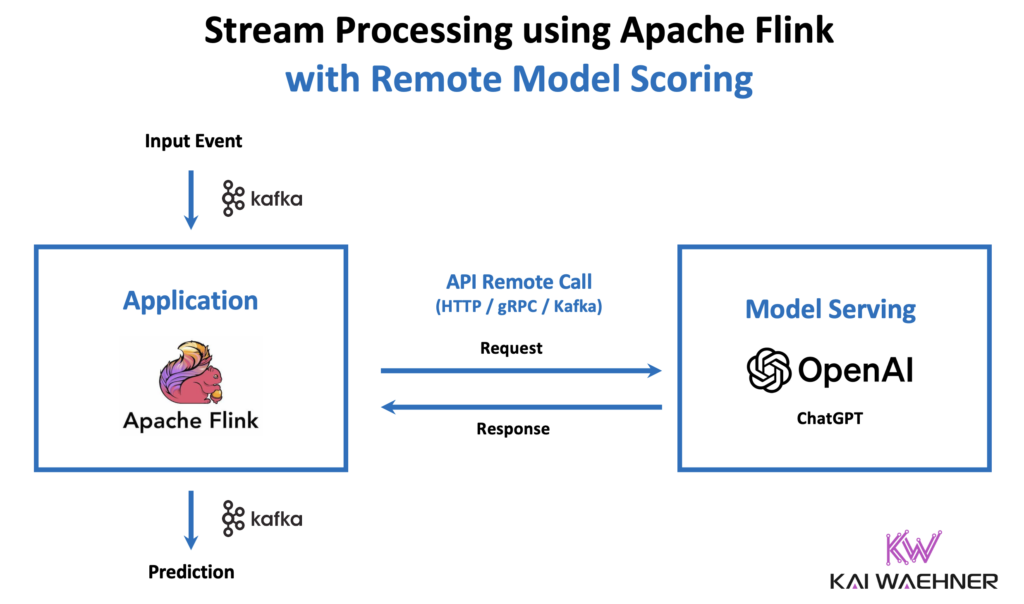
Trade-offs using Kafka with an RPC-based model server and HTTP/gRPC:
- Simple integration with existing technologies and organizational processes
- Easiest to understand if you come from a non-streaming world
- Tight coupling of the availability, scalability, and latency/throughput between application and model server
- Separation of concerns (e.g. Python model + Java streaming app)
- Limited scalability and robustness
- Later migration to real streaming is also possible
- Model management built-in for different models, versioning, and A/B testing
- Model monitoring built-in (include real-time tracking of model performance metrics (e.g., accuracy, latency), resource utilization, data drift detection, and logging of predictions for auditing and troubleshooting)
In the meantime, some model servers like Seldon or Dataiku also provide remote model inference natively via the Kafka API. A Kafka-native streaming model server enables the separation of concerns by providing a model server with all the expected features. But the model server does not use RPC communication via HTTP/gRPC and all the drawbacks this creates for a streaming architecture. Instead, the model server communicates via the native Kafka protocol and Kafka topics with the client application. Therefore, the stream processing application built with Flink has an option to do event-driven integration for model inference.
Embedded Model Inference with Kafka, Flink and TensorFlow
Here is an example with Kafka, Flink and TensorFlow where the model is embedded into the stream processing application. Apache Kafka is used to ingest and stream data, while Apache Flink processes the data in real-time, embedding a TensorFlow model directly within the Flink application for immediate model inference. This integration allows for low-latency predictions and actions on streaming data, leveraging the model’s capabilities with no external service calls, thus enhancing efficiency and scalability.

Trade-offs of embedding analytic models into a Flink application:
- Best latency as local inference instead of remote call
- No coupling of the availability, scalability, and latency/throughput of your Kafka Streams application
- Offline inference (devices, edge processing, etc.)
- No side-effects (e.g., in case of failure), all covered by Kafka processing (e.g., exactly once)
- No built-in model management and monitoring
I showed examples and use cases for embedding TensorFlow and H2O.ai models into Kafka Streams and KSQL many years ago already. With Apache Flink becoming the de facto standard for many stream processing scenarios, it is just natural that we see more adoption of Flink for AI/ML use cases.
The Impact of Kafka and Flink for Model Inference – Predictive AI vs. Generative AI (GenAI)
Predictive AI and Generative AI (GenAI) represent two distinct paradigms within the field of artificial intelligence, each with unique capabilities and architectural requirements. Understanding these differences is crucial for leveraging their potential in data streaming applications.
Predictive AI and Data Streaming
Predictive AI focuses on forecasting future events or outcomes based on historical data. It employs machine learning models that are trained to recognize patterns and correlations within datasets. These models are typically used for tasks like predicting customer behavior, detecting fraud, or forecasting demand.
- Architecture: The architecture for predictive AI often involves a batch processing approach. Data is collected, pre-processed, and then fed into a machine learning model to generate predictions. The model is usually trained offline and then deployed to make predictions on new data. This process can be integrated into applications via APIs or embedded directly into systems for real-time inference.
- Impact on Data Streaming: In predictive AI, data streaming can enhance the timeliness and relevance of predictions by providing real-time data inputs. Technologies like Apache Kafka and Flink can ingest and process data streams, enabling continuous model inference and updating predictions as new data arrives. This real-time capability is valuable in scenarios where immediate insights are critical, such as fraud detection or dynamic pricing.
- Concrete Examples:
Generative AI (GenAI) and Data Streaming
Generative AI creates new content, such as text, images, or music, that mimics human behaviour or creativity. It uses advanced models such as large language models (LLMs) to generate outputs based on input prompts. Just keep in mind that GenAI is still predictive based on historical data; it just makes a lot of small predictions to generate something. For instance, with text, it predicts a word at a time, etc.
- Architecture: The architecture for GenAI is more complex and requires real-time, contextualized data to produce accurate and relevant outputs. This is where Retrieval Augmented Generation (RAG) comes into play. RAG combines LLMs with vector databases and semantic search to provide the context for generation tasks. The architecture involves two major steps: data augmentation and retrieval. Data is first processed to create embeddings, which are stored in a vector database. When a prompt is received, the system retrieves relevant context from the database to inform the generation process.
- Impact on Data Streaming: Data streaming is integral to GenAI architectures, particularly those employing RAG. Real-time data streaming platforms like Apache Kafka and Flink facilitate the ingestion and processing of data streams, ensuring that the LLMs have access to the most current and relevant information. This capability is crucial for preventing hallucinations (i.e., generating false or misleading information) and ensuring the reliability of GenAI outputs. By integrating data streaming with GenAI, organizations can create dynamic, context-aware applications that respond to real-time data inputs.
- Concrete Examples:
Data Streaming as Data Pipeline for Model Training in Lakehouses AND for Robust Low-Latency Model Inference
Data streaming technologies play a pivotal role in both predictive AI and generative AI. Kafka and Flink improve the data quality and latency for data ingestion into data warehouses, data lakes, lakehouses for model training. And data streaming enhances model inference by improving the timeliness and accuracy of predictions in predictive AI and providing the context for content generation in GenAI.
By leveraging data streaming with Kafka and Flink, organizations can achieve real-time predictions with low latency, scalability, and robustness, meeting critical SLAs for various use cases. The choice between remote and embedded model inference depends on the specific requirements and constraints of the application, such as latency tolerance, model update frequency, and resource availability. Overall, data streaming provides a powerful foundation for deploying AI/ML solutions that deliver timely and actionable insights.
How do you leverage data streaming with Kafka and Flink in your AI/ML projects? Only as data ingestion layer into the lakehouse? Or also for more robust and performant model inference? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.





