The evolution of data streaming has transformed modern business infrastructure, establishing real-time data processing as a critical asset across industries. At the forefront of this transformation, Apache Kafka and Apache Flink stand out as leading open-source frameworks that serve as the foundation for cloud services, enabling organizations to unlock the potential of real-time data. Over recent years, trends have shifted from batch-based data processing to real-time analytics, scalable cloud-native architectures, and improved data governance powered by these technologies. Looking ahead to 2025, the data streaming ecosystem is set to undergo even greater changes. Here are the top trends shaping the future of data streaming for businesses.

Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch.
The Top Data Streaming Trends
Some followers might notice that this became a series with articles about the top 5 data streaming trends for 2021, the top 5 for 2022, the top 5 for 2023, and the top 5 for 2024. Trends change over time, but the huge value of having a scalable real-time infrastructure as the central data hub stays. Data streaming with Apache Kafka is a journey and evolution to set data in motion.
I recently explored the past, present, and future of data streaming tools and strategies from the past decades. Data streaming is becoming more and more mature and standardized, but also innovative.
Let’s now look at the top trends coming up more regularly in conversations with customers, prospects, and the broader data streaming community across the globe:
- The Democratization of Kafka: Apache Kafka has transitioned from a specialized tool to a key pillar in modern data infrastructure.
- Kafka Protocol as the Standard: Vendors adopt the Kafka wire protocol, enabling flexibility with compatibility and performance trade-offs.
- BYOC Deployment Model: Bring Your Own Cloud gains traction for balancing security, compliance, and managed services.
- Flink Becomes the Standard for Stream Processing: Apache Flink rises as the premier framework for stream processing, building integration pipelines and business applications.
- Data Streaming for Real-Time Predictive AI and GenAI: Real-time model inference drives predictive and generative AI applications.
- Data Streaming Organizations: Companies unify real-time data strategies to standardize processes, tools, governance, and collaboration.
The following sections describe each trend in more detail. The trends are relevant for many scenarios; no matter if you use open-source frameworks like Apache Kafka and Flink, a commercial platform, or a fully managed cloud service like Confluent Cloud.
Trend 1: The Democratization of Kafka
In the last decade, Apache Kafka has become the standard for data streaming, evolving from a specialized tool to an essential utility in the modern tech stack. With over 150,000 organizations using Kafka today, it has become the de facto choice for stream processing. Yet, with a market crowded by offerings from AWS, Microsoft Azure, Google GCP, IBM, Oracle, Confluent, and various startups, companies can no longer rely solely on Kafka for differentiation. The vast array of Kafka-compatible solutions means that businesses face more choices than ever, but also new challenges in selecting the solution that balances cost, performance, and features.
The Challenge: Finding the Right Fit in a Crowded Kafka Market
For end users, choosing the right Kafka solution is becoming increasingly complex. Basic Kafka offerings cover standard streaming needs but may lack advanced features, such as enhanced security, data governance, or integration and processing capabilities, that are essential for specific industries. In such a diverse market, businesses must navigate trade-offs, considering whether a low-cost option meets their needs or whether investing in a premium solution with added capabilities provides better long-term value.
The Solution: Prioritizing Features for Your Strategic Needs
As Kafka solutions evolve, users must look beyond price and consider features that offer real strategic value. For example, companies handling sensitive customer data might benefit from Kafka products with top-tier security features. Those focused on analytics may look for solutions with strong integrations into data platforms and low cost for high throughput. By carefully selecting a Kafka product that aligns with industry-specific requirements, businesses can leverage the full potential of Kafka while optimizing for cost and capabilities.
For instance, look at Confluent’s various cluster types for different requirements and use cases in the cloud:
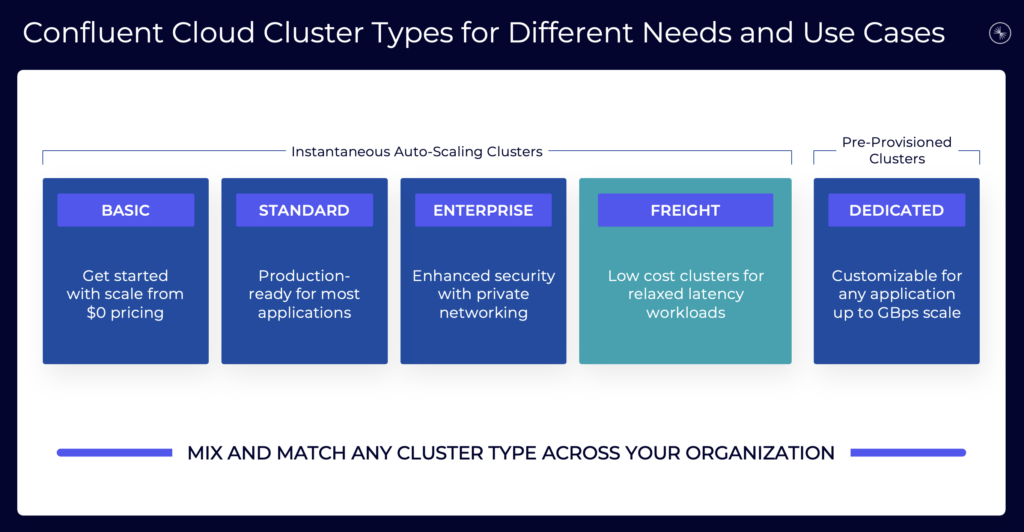
As an example, Freight Clusters was introduced to provide an offering with up to 90 percent less cost. The major trade-off is higher latency. But this is perfect for high volume log analytics at GB/sec scale.
The Business Value: Affordable and Customized Data Streaming
Kafka’s commoditization means more affordable, customizable options for businesses of all sizes. This competition reduces costs, making high-performance data streaming more accessible, even to smaller organizations. By choosing a tailored solution, businesses can enhance customer satisfaction, speed up decision-making, and innovate faster in a competitive landscape.
Trend 2: The Kafka Protocol, not Apache Kafka, is the New Standard for Data Streaming
With the rise of cloud-native architectures, many vendors have shifted to supporting the Kafka protocol rather than the open-source Kafka framework itself, allowing for greater flexibility and cloud optimization. This change enables businesses to choose Kafka-compatible tools that better align with specific needs, moving away from a one-size-fits-all approach.
Confluent introduced its KORA engine, i.e., Kafka re-architected to be cloud-native. A deep technical whitepaper goes into the details (this is not a marketing document but really for software engineers).
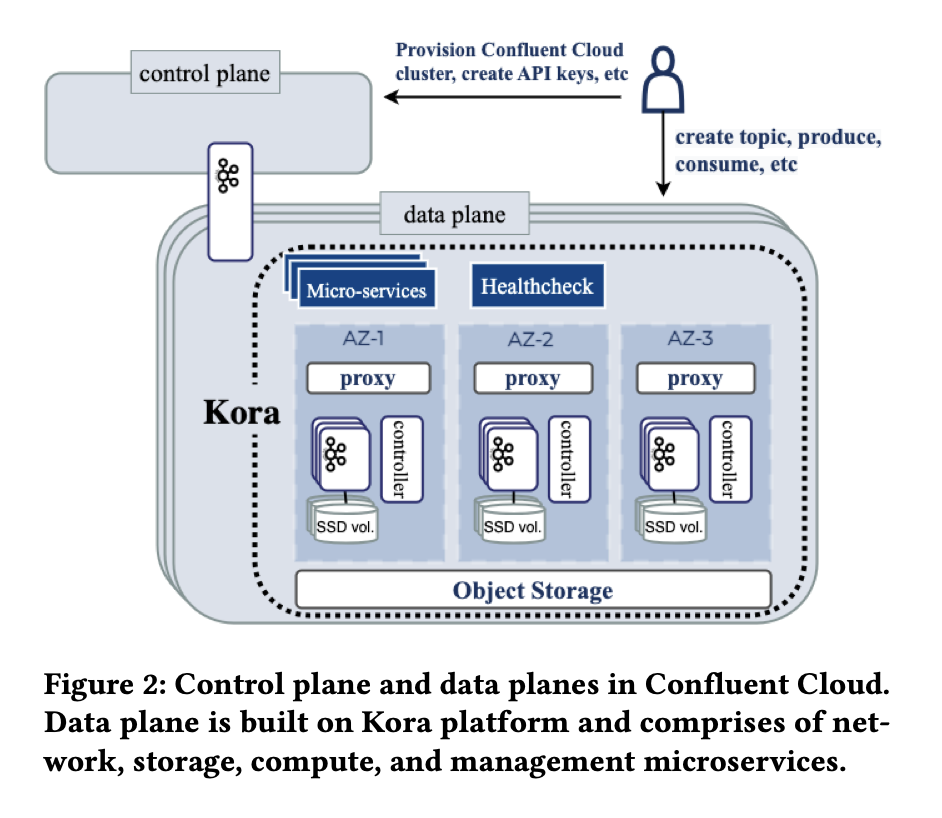
Other players followed Confluent and introduced their own cloud-native “data streaming engines”. For instance, StreamNative has URSA powered by Apache Pulsar, Redpanda talks about its R1 Engine implementing the Kafka protocol, and Ververica recently announced VERA for its Flink-based platform.
Some vendors rely only on the Kafka protocol with a proprietary engine from the beginning. For instance, Azure Event Hubs or WarpStream. Amazon MSK also goes in this direction by adding proprietary features like Tiered Storage or even introducing completely new product options such as Amazon MSK Express brokers.
The Challenge: Limited Compatibility Across Kafka Solutions
When vendors implement the Kafka protocol instead of the entire Kafka framework, it can lead to compatibility issues, especially if the solution doesn’t fully support Kafka APIs. For end users, this can complicate integration, particularly for advanced features like Exactly-Once Semantics, the Transaction API, Compacted Topics, Kafka Connect, or Kafka Streams, which may not be supported or working as expected.
The Solution: Evaluating Kafka Protocol Solutions Critically
To fully leverage the flexibility of Kafka protocol-based solutions, a thorough evaluation is essential. Businesses should carefully assess the capabilities and compatibility of each option, ensuring it meets their specific needs. Key considerations include verifying the support of required features and APIs (such as the Transaction API, Kafka Streams, or Connect).
It is also crucial to evaluate the level of product support provided, including 24/7 availability, uptime SLAs, and compatibility with the latest versions of open-source Apache Kafka. This detailed evaluation ensures that the chosen solution integrates seamlessly into existing architectures and delivers the reliability and performance required for modern data streaming applications.
The Business Value: Expanded Options and Cost-Efficiency
Kafka protocol-based solutions offer greater flexibility, allowing businesses to select Kafka-compatible services optimized for their specific environments. This flexibility opens doors for innovation, enabling companies to experiment with new tools without vendor lock-in.
For instance, innovations such as a “direct write to S3 object store” architecture, as seen in WarpStream, Confluent Freight Clusters, and other data streaming startups that also build proprietary engines around the Kafka protocol. The result is a more cost-effective approach to data streaming, though it may come with trade-offs, such as increased latency. Check out this video about the evolution of Kafka Storage to learn more.
Trend 3: BYOC (Bring Your Own Cloud) as a New Deployment Model for Security and Compliance
As data security and compliance concerns grow, the Bring Your Own Cloud (BYOC) model is gaining traction as a new way to deploy Apache Kafka. BYOC allows businesses to host Kafka in their own Virtual Private Cloud (VPC) while the vendor manages the control plane to handle complex orchestration tasks like partitioning, replication, and failover.
This BYOC approach offers organizations enhanced control over their data while retaining the operational benefits of a managed service. BYOC provides a middle ground between self-managed and fully managed solutions, addressing specific regulatory and security needs without sacrificing scalability or flexibility.
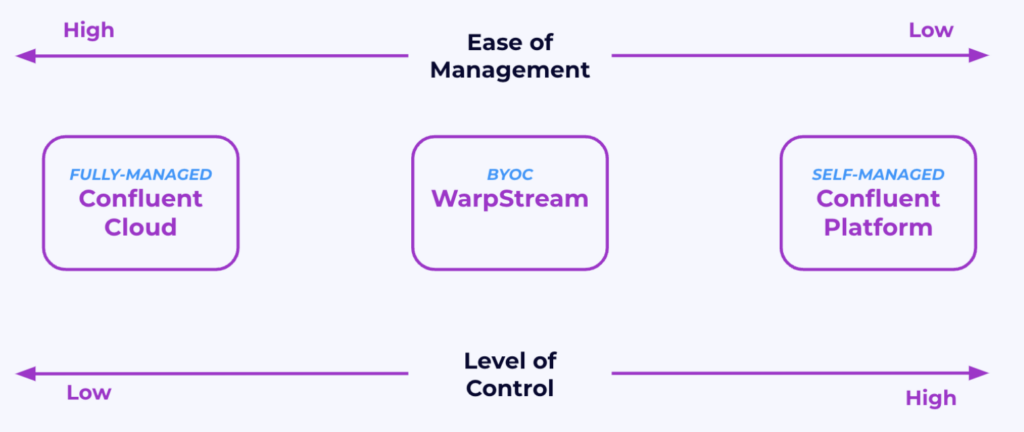
The Challenge: Balancing Security and Ease of Use
Ensuring data sovereignty and compliance is non-negotiable for organizations in highly regulated industries. However, traditional fully managed cloud solutions can pose risks due to vendor access to sensitive data and infrastructure. Many BYOC solutions claim to address these issues but fall short when it comes to minimizing external access to customer environments. Common challenges include:
- Vendor Access to VPCs: Many BYOC offerings require vendors to have access to customer VPCs for deployment, cluster management, and troubleshooting. This introduces potential security vulnerabilities.
- IAM Roles and Elevated Privileges: Cross-account Identity and Access Management (IAM) roles are often necessary for managing BYOC clusters, which can expose sensitive systems to unnecessary risks.
- VPC Peering Complexity: Traditional BYOC solutions often rely on VPC peering, a complex and expensive setup that increases operational overhead and opens additional points of failure.
These limitations create significant challenges for security-conscious organizations, as they undermine the core promise of BYOC: control over the data environment.
The Solution: Gaining Control with a “Zero Access” BYOC Model
WarpStream redefines the BYOC model with a “zero access” architecture, addressing the challenges of traditional BYOC solutions. Unlike other BYOC offerings using the Kafka protocol, WarpStream ensures that no data leaves the customer’s environment, delivering a truly secure-by-default platform. Hence this section discusses specifically WarpStream, not BYOC Kafka offerings in general.
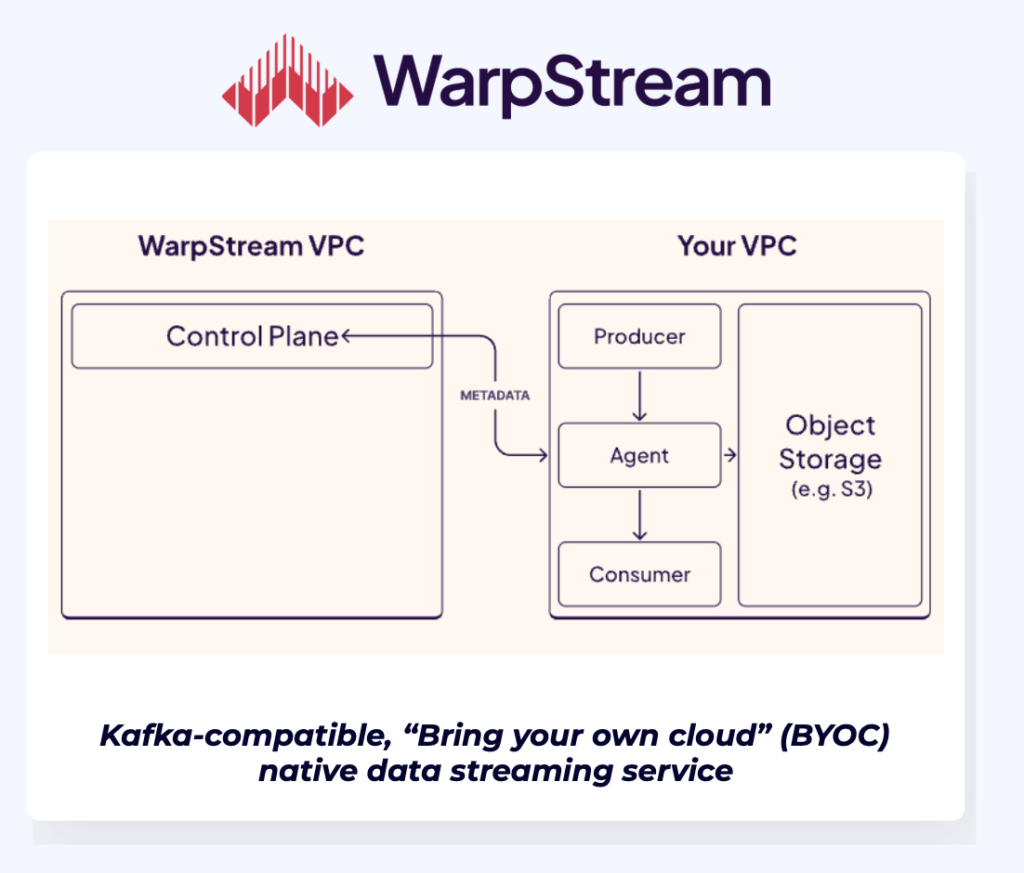
Key features of WarpStream include:
- Zero Access to Customer VPCs: WarpStream eliminates vendor access by deploying stateless agents within the customer’s environment, handling compute operations locally without requiring cross-account IAM roles or elevated privileges to reduce security risks.
- Data/Metadata Separation: Raw data remains entirely within the customer’s network for full sovereignty, while only metadata is sent to WarpStream’s control plane for centralized management, ensuring data security and compliance.
- Simplified Infrastructure: WarpStream avoids complex setups like VPC peering and cross-IAM roles, minimizing operational overhead while maintaining high performance.
Comparison with Other BYOC Solutions using the Kafka protocol:
Unlike most other BYOC offerings (e.g., Redpanda), WarpStream doesn’t require direct VPC access or elevated permissions, avoiding risks like data exposure or remote troubleshooting vulnerabilities. Its “zero access” architecture ensures unparalleled security and compliance.
The Business Value: Secure, Compliant, and Scalable Data Streaming
WarpStream’s innovative approach to BYOC delivers exceptional business value by addressing security and compliance concerns while maintaining operational simplicity and scalability:
- Uncompromised Security: The zero-access architecture ensures that raw data remains entirely within the customer’s environment, meeting the strictest security and compliance requirements for regulated industries like finance, healthcare, and government.
- Operational Efficiency: By eliminating the need for VPC peering, cross-IAM roles, and remote vendor access, WarpStream simplifies BYOC deployments and reduces operational complexity.
- Cost Optimization: WarpStream’s reliance on cloud-native technologies like object storage reduces infrastructure costs compared to traditional disk-based approaches. Stateless agents also enable efficient scaling without unnecessary overhead.
- Data Sovereignty: The data/metadata split guarantees that data never leaves the customer’s environment, ensuring compliance with regulations such as GDPR and HIPAA.
- Peace of Mind for Security Teams: With no vendor access to the VPC or object storage, WarpStream’s zero-access model eliminates concerns about external breaches or elevated privileges, making it easier to gain buy-in from security and infrastructure teams.
BYOC Strikes the Balance Between Control and Managed Services
BYOC offers businesses the ability to strike a balance between control and managed services, but not all BYOC solutions are created equal. WarpStream’s “zero access” architecture sets a new standard, addressing the critical challenges of security, compliance, and operational simplicity. By ensuring that raw data never leaves the customer’s environment and eliminating the need for vendor access to VPCs, WarpStream delivers a BYOC model that meets the highest standards of security and performance. For organizations seeking a secure, scalable, and compliant approach to data streaming, WarpStream represents the future of BYOC data streaming.
But just to be clear: If a data streaming project goes to the cloud, fully managed Kafka (and Flink) should always be the first option as it is much easier to manage and operate to focus on fast time-to-market and business innovation. Choose BYOC only if fully managed does not work for you because of security requirements.
Trend 4: Flink Becomes the De Facto Standard for Stream Processing
Apache Flink has emerged as the premier choice for organizations seeking a robust and versatile framework for continuous stream processing. Its ability to handle complex data pipelines with high throughput, low latency, and advanced stateful operations has solidified its position as the de facto standard for stream processing. Flink’s support for Java, Python, and SQL further enhances its appeal, enabling developers to build powerful data-driven applications using familiar tools.
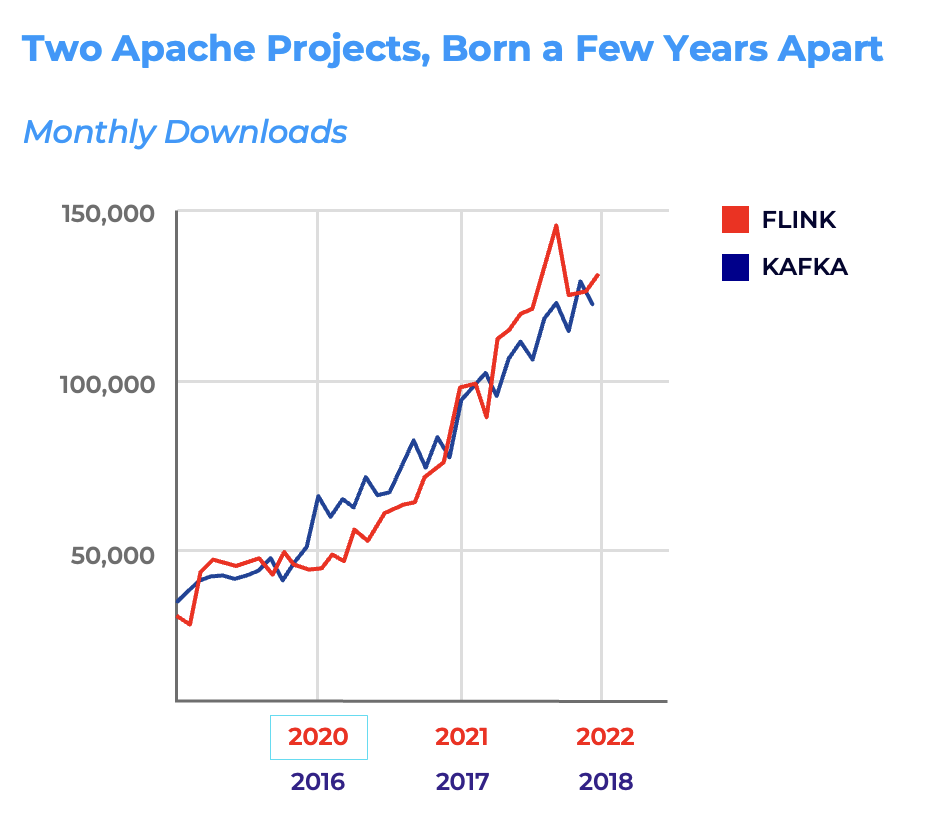
As Flink adoption grows, it increasingly complements Apache Kafka as part of the modern data streaming ecosystem, while the Kafka Streams (Java-only) library remains relevant for lightweight, application-embedded use cases.
The Challenge: Handling Complex, High-Throughput Data Streams
Modern businesses increasingly rely on real-time data for both operational and analytical needs, spanning mission-critical applications like fraud detection, predictive maintenance, and personalized customer experiences, as well as Streaming ETL for integrating and transforming data. These diverse use cases demand robust stream processing capabilities that can address the challenges of:
The Solution: Apache Flink for Scalability and Versatility
Apache Flink’s versatility makes it uniquely positioned to meet the demands of both streaming ETL for data integration and building real-time business applications. Flink provides:
- Low Latency: Near-instantaneous processing is crucial for enabling real-time decision-making in business applications, timely updates in analytical systems, and supporting transactional workloads where rapid processing and immediate consistency are essential for ensuring smooth operations and seamless user experiences.
- High Throughput and Scalability: The ability to process millions of events per second, whether for aggregating operational metrics or moving massive volumes of data into data lakes or warehouses, without bottlenecks.
- Stateful Processing: Support for maintaining and querying the state of data streams, essential for performing complex operations like aggregations, joins, and pattern detection in business applications, as well as data transformations and enrichment in ETL pipelines.
- Multiple Programming Languages: Support for Java, Python, and SQL ensures accessibility for a wide range of developers, enabling efficient implementation across various use cases.
The rise of cloud services has further propelled Flink’s adoption, with offerings from major providers like Confluent, Amazon, IBM, and emerging startups. These cloud-native solutions simplify Flink deployments, making it easier for organizations to operationalize real-time analytics.
Apache Spark and Spark Streaming as Alternative for Flink?
While Apache Flink has emerged as the de facto standard for stream processing, other frameworks like Apache Spark and its streaming module, Structured Streaming, continue to compete in this space. However, Spark Streaming has notable limitations that make it less suitable for many of the complex, high-throughput workloads modern enterprises demand.
The Challenges with Spark Streaming
Apache Spark, originally designed as a batch processing framework, introduced Spark Streaming and later Structured Streaming to address real-time processing needs. However, its batch-oriented roots present inherent challenges:
- Micro-Batch Architecture: Spark Structured Streaming relies on micro-batches, where data is divided into small time intervals for processing. This approach, while effective for certain workloads, introduces higher latency compared to Flink’s true streaming architecture. Applications requiring millisecond-level processing or transactional workloads may find Spark unsuitable.
- Limited Stateful Processing: While Spark supports stateful operations, its reliance on micro-batches adds complexity and latency. This makes Spark Streaming less efficient for use cases that demand continuous state updates, such as fraud detection or complex event processing (CEP).
- Fault Tolerance Complexity: Spark’s recovery model is rooted in its lineage-based approach to fault tolerance, which can be less efficient for long-running streaming applications. Flink, by contrast, uses checkpointing and savepoints to handle failures more gracefully to ensure state consistency with minimal overhead.
- Performance Overhead: Spark’s general-purpose design often results in higher resource consumption compared to Flink, which is purpose-built for stream processing. This can lead to increased infrastructure costs for high-throughput workloads.
- Scalability Challenges for Stateful Workloads: While Spark scales effectively for batch jobs, its scalability for complex stateful stream processing is more limited, as distributed state management in micro-batches can become a bottleneck under heavy load.
By addressing these limitations, Apache Flink provides a more versatile and efficient solution than Apache Spark for organizations looking to handle complex, real-time data processing at scale.
Flink’s architecture is purpose-built for streaming, offering native support for stateful processing, low-latency event handling, and fault-tolerant operation, making it the preferred choice for modern real-time applications. But to be clear: Apache Spark, including Spark Streaming, has its place in data lakes and lakehouses to process analytical workloads.
The Business Value: Real-Time Analytics and Improved Decision-Making with Apache Flink
Flink’s technical capabilities bring tangible business benefits, making it an essential tool for modern enterprises. By providing real-time insights, Flink enables businesses to respond to events as they occur, such as detecting and mitigating fraudulent transactions instantly, reducing losses, and enhancing customer trust.
The support of Flink for both transactional workloads (e.g., fraud detection or payment processing) and analytical workloads (e.g., real-time reporting or trend analysis) ensures versatility across a range of critical business functions. Scalability and resource optimization keep infrastructure costs manageable, even for demanding, high-throughput workloads, while features like checkpointing streamline failure recovery and upgrades, minimizing operational overhead.
Flink stands out with its dual focus on streaming ETL for data integration and building business applications powered by real-time analytics. Its rich APIs for Java, Python, and SQL make it easy for developers to implement complex workflows, accelerating time-to-market for new applications.
Trend 5: AI and Data Streaming: Real-Time Model Inference with Flink
Data streaming has powered AI/ML infrastructure for many years because of its capabilities to scale to high volumes, process data in real-time, and integrate with transactional (payments, orders, ERP, etc.) and analytical (data warehouse, data lake, lakehouse) systems. My first article about Apache Kafka and Machine Learning was published in 2017: “How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka“.
As AI continues to evolve, real-time model inference powered by data streaming is opening up new possibilities for predictive and generative AI applications. By integrating model inference with stream processors such as Apache Flink, businesses can perform on-demand predictions for fraud detection, customer personalization, and more.
The Challenge: Provide Context for AI Applications In Real-Time
Traditional batch-based AI inference is too slow for many applications, delaying responses and leading to missed opportunities or wrong business decisions. To fully harness AI in real-time, businesses need to embed model inference directly within streaming pipelines.
Generative AI (GenAI) demands new design patterns like Retrieval Augmented Generation (RAG) to ensure accuracy, relevance, and reliability in its outputs. Without data streaming, RAG struggles to provide large language models (LLMs) with the real-time, domain-specific context they need, leading to outdated or hallucinated responses. Context is essential to ensure that LLMs deliver accurate and trustworthy outputs by grounding them in up-to-date and precise information.
The Solution: Leveraging Apache Flink for Real-Time Context and Model Inference
Apache Flink enables real-time model inference by connecting data streams to external AI models through APIs. This setup allows companies to use centralized model servers for inference, providing flexibility and scalability while keeping data streams fast and responsive.
Flink’s ability to process data in real-time also enables advanced machine learning workflows, supporting predictive analytics and generative AI use cases that drive innovation.
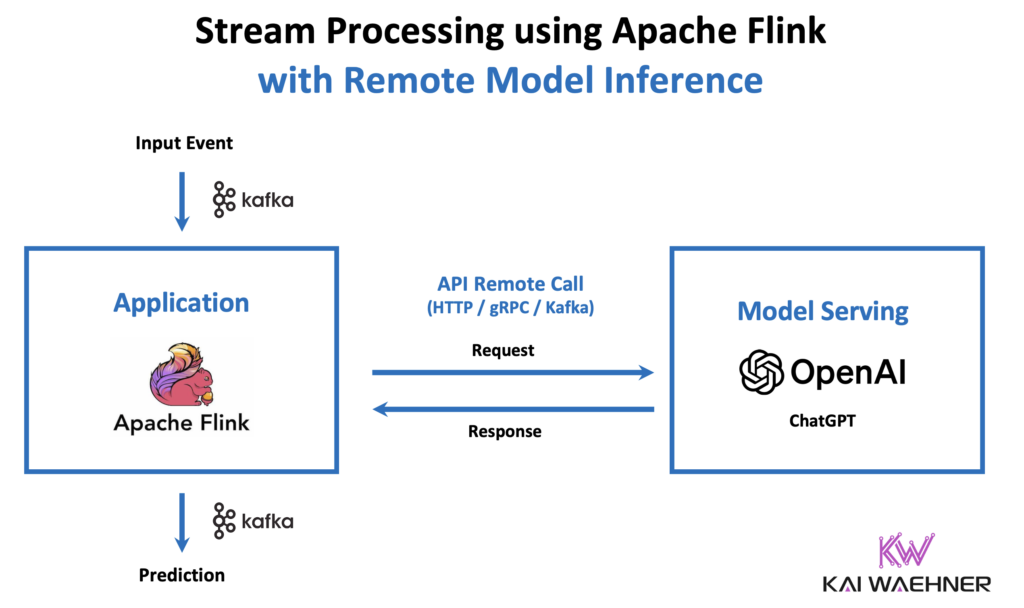
Apache Flink enables real-time model inference by connecting data streams to external AI models through APIs. This setup allows companies to use centralized model servers for inference, providing flexibility and scalability while keeping data streams fast and responsive. By processing data in real-time, Flink ensures that generative AI models operate with the most current and relevant context, reducing errors and hallucinations.
Flink’s real-time processing capabilities also support advanced machine learning workflows. This enables use cases like predictive analytics, anomaly detection, and generative AI applications that require instantaneous decision-making. The ability to join live data streams with historical or external datasets enriches the context for model inference, enhancing both accuracy and relevance.
Additionally, Flink facilitates feature extraction and data preprocessing directly within the stream to ensure that the inputs to AI models are optimized for performance. This seamless integration with model servers and vector databases allows organizations to scale their AI systems effectively, leveraging real-time insights to drive innovation and deliver immediate business value.
The Business Value: Immediate, Actionable AI Insights
Real-time AI model inference with Flink enables businesses to provide personalized customer experiences, detect fraud as it happens, and perform predictive maintenance with minimal latency. This real-time responsiveness empowers companies to make AI-driven decisions in milliseconds, improving customer satisfaction and operational efficiency.
By integrating Flink with event-driven architectures like Apache Kafka, businesses can ensure that AI systems are always fed with up-to-date and trustworthy data, further enhancing the reliability of predictions.
The integration of Flink and data streaming offers a clear path to measurable business impact. By aligning real-time AI capabilities with organizational goals, they can drive innovation while reducing operational costs, such as automating customer support to lower reliance on service agents.
Furthermore, Flink’s ability to process and enrich data streams at scale supports strategic initiatives like hyper-personalized marketing or optimizing supply chains in real-time. These benefits directly translate into enhanced competitive positioning, faster time-to-market for AI-driven solutions, and the ability to make more confident, data-driven decisions at the speed of business.
Trend 6: Becoming a Data Streaming Organization
To harness the full potential of data streaming, companies are shifting toward structured, enterprise-wide data streaming strategies. Moving from a tactical, ad-hoc approach to a cohesive top-down strategy enables businesses to align data streaming with organizational goals, driving both efficiency and innovation.
The Challenge: Fragmented Data Streaming Efforts
Many companies face challenges due to disjointed streaming efforts, leading to data silos and inconsistencies that prevent them from reaping the full benefits of real-time data processing. At Confluent, we call this the enterprise adoption barrier:
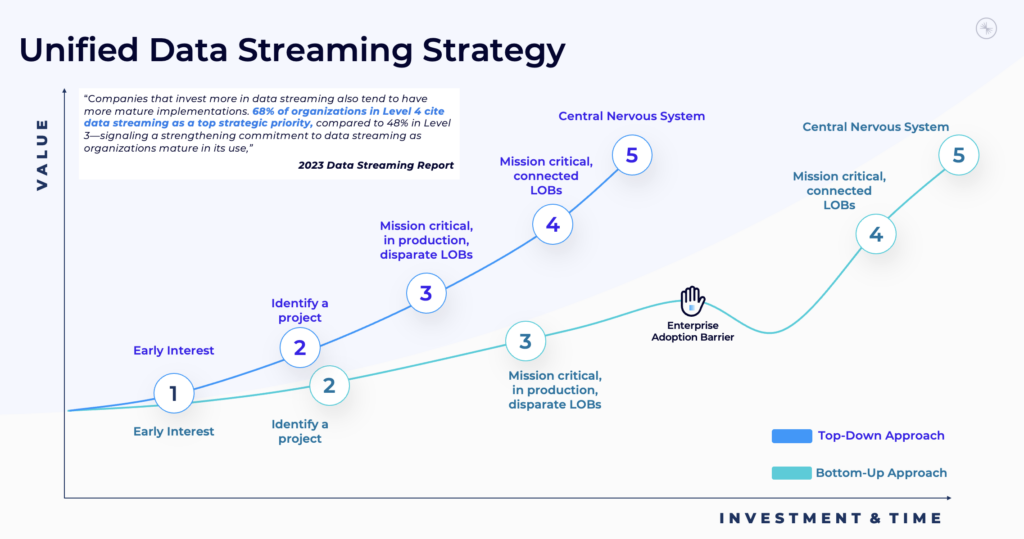
This fragmentation results in inefficiencies, duplication of efforts, and a lack of standardized processes. Without a unified approach, organizations struggle with:
- Data Silos: Limited data sharing across teams creates bottlenecks for broader use cases.
- Inconsistent Standards: Different teams often use varying schemas, patterns, and practices, leading to integration challenges and data quality issues.
- Governance Gaps: A lack of defined roles, responsibilities, and policies results in limited oversight, increasing the risk of data misuse and compliance violations.
These challenges prevent organizations from scaling their data streaming capabilities and realizing the full value of their real-time data investments.
The Solution: Building an Integrated Data Streaming Organization
By adopting a comprehensive data streaming strategy, businesses can create a unified data platform with standardized tools and practices. A dedicated streaming platform team, often called the Center of Excellence (CoE), ensures consistent operations. An internal developer platform provides governed, self-serve access to streaming resources.
Key elements of a data streaming organization include:
- Unified Platform: Move from disparate tools and approaches to a single, standardized data streaming platform. This includes consistent policies for cluster management, multi-tenancy, and topic naming, ensuring a reliable foundation for data streaming initiatives.
- Self-Service: Provide APIs, UIs, and other interfaces for teams to onboard, create, and manage data streaming resources. Self-service capabilities ensure governed access to topics, schemas, and streaming capabilities, empowering developers while maintaining compliance and security.
- Data as a Product: Adopt a product-oriented mindset where data streams are treated as reusable assets. This includes formalizing data products with clear contracts, ownership, and metadata, making them discoverable and consumable across the organization.
- Alignment: Define clear roles and responsibilities, from platform operators and developers to data product owners. Establishing an enterprise-wide data streaming function ensures coordination and alignment across teams.
- Governance: Implement automated guardrails for compliance, quality, and access control. This ensures that data streaming efforts remain secure, trustworthy, and scalable.
The Business Value: Consistent, Scalable, and Agile Data Streaming
Becoming a Data Streaming Organization unlocks significant value by turning data streaming into a strategic asset. The benefits include:
- Enhanced Agility: A unified platform reduces time-to-market for new data-driven products and services, allowing businesses to respond quickly to market trends and customer demands.
- Operational Efficiency: Streamlined processes and self-service capabilities reduce the overhead of managing multiple tools and teams, improving productivity and cost-effectiveness.
- Scalable Innovation: Standardized patterns and reusable data products enable the rapid development of new use cases, fostering a culture of innovation across the enterprise.
- Improved Governance: Clear policies and automated controls ensure data quality, security, and compliance, building trust with customers and stakeholders.
- Cross-Functional Collaboration: By breaking down silos, organizations can leverage data streams across teams, creating a network effect that accelerates value creation.
To successfully adopt a Data Streaming Organization model, companies must combine technical capabilities with cultural and structural change. This involves not just deploying tools but establishing shared goals, metrics, and education to bring teams together around the value of real-time data. As organizations embrace data streaming as a strategic function, they position themselves to thrive in a data-driven world.
Embracing the Future of Data Streaming
As data streaming continues to mature, it has become the backbone of modern digital enterprises. It enables real-time decision-making, operational efficiency, and transformative AI applications. Trends such as the commoditization of Kafka, the adoption of the Kafka protocol, BYOC deployment models, and the rise of Flink as the standard for stream processing demonstrate the rapid evolution and growing importance of this technology. These innovations not only streamline infrastructure but also empower organizations to harness real-time insights, foster agility, and remain competitive in the ever-changing digital landscape.
These advancements in data streaming present a unique opportunity to redefine data strategy. Leveraging data streaming as a central pillar of IT architecture allows businesses to break down silos, integrate machine learning into critical workflows, and deliver unparalleled customer experiences. The convergence of data streaming with generative AI, particularly through frameworks like Flink, underscores the importance of embracing a real-time-first approach to data-driven innovation.
Looking ahead, organizations that invest in scalable, secure, and strategic data streaming infrastructures will be positioned to lead in 2025 and beyond. By adopting these trends, enterprises can unlock the full potential of their data, drive business transformation, and solidify their place as leaders in the digital era. The journey to set data in motion is not just about technology—it’s about building the foundation for a future where real-time intelligence powers every decision and every experience.
What trends do you see for data streaming? Which ones are your favorites? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.






