Slides from my talk “Big Data beyond Apache Hadoop – How to integrate ALL your data” at NoSQLmatters 2013 in Cologne are online.
Here the abstract:
Big data represents a significant paradigm shift in enterprise technology. Big data radically changes the nature of the data management profession as it introduces new concerns about the volume, velocity and variety of corporate data.
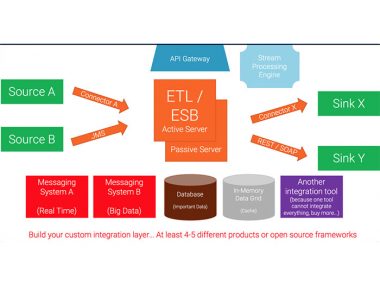
Apache Hadoop is the open source defacto standard for implementing big data solutions on the Java platform. Hadoop consists of its kernel, MapReduce, and the Hadoop Distributed Filesystem (HDFS). A challenging task is to send all data to Hadoop for processing and storage (and then get it back to your application later), because in practice data comes from many different applications (SAP, Salesforce, Siebel, etc.) and databases (File, SQL, NoSQL), uses different technologies and concepts for communication (e.g. HTTP, FTP, RMI, JMS), and consists of different data formats using CSV, XML, binary data, or other alternatives.
This session shows different open source frameworks and tools to solve this challenging task. Learn how to use every thinkable data with Hadoop – without plenty of complex or redundant boilerplate code.
Here the slides:
Click on the button to load the content from www.slideshare.net.