In November 2016, I am at Big Data Spain in Madrid for the first time. A great conference with many awesome speakers and sessions about very hot topics such as Apache Hadoop, Spark Spark, Streaming Processing / Streaming Analytics and Machine Learning. If you are interested in big data, then this conference is for you! My two talks:
Here I wanna share the slides and a video recording of the latter one…
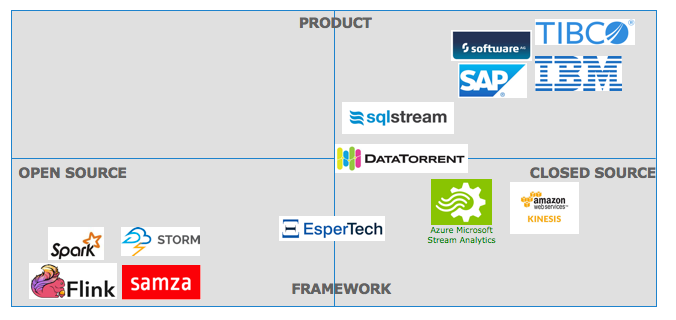
This session discusses the technical concepts of stream processing / streaming analytics and how it is related to big data, mobile, cloud and internet of things. Different use cases such as predictive fault management or fraud detection are used to show and compare alternative frameworks and products for stream processing and streaming analytics.
The focus of the session lies on comparing
The session will also discuss how stream processing is related to Apache Hadoop frameworks (such as MapReduce, Hive, Pig or Impala) and machine learning (such as R, Spark ML or H2O.ai).
The following slide deck is a more extensive version of the talk at Big Data Spain (as the conference talks were only 30 minutes):
Click on the button to load the content from www.slideshare.net.
The video recording walks you through the above slide deck:
As always, I appreciate any comments, questions or other feedback.
The rise of Electric Vehicles (EVs) demands a scalable, efficient charging network—but challenges like fluctuating…
Apache Kafka 4.0 represents a major milestone in the evolution of real-time data infrastructure. Used…
Agentic AI marks a major evolution in artificial intelligence—shifting from passive analytics to autonomous, goal-driven…
Industrial enterprises face increasing pressure to move faster, automate more, and adapt to constant change—without…
As real-time technologies reshape IT architectures, software vendors face a critical decision: specialize deeply in…
Batch processing introduces delays, complexity, and data quality issues that modern businesses can no longer…
{kind=link}