I do a lot of presentations these days at meetups and conferences with one focus: How to leverage Apache Kafka and Kafka Streams to apply analytic models (built with H2O, TensorFlow, DeepLearning4J and other frameworks) to scalable, mission-critical environments. As many attendees have asked me, I created a video recording about this talk (focusing on live demos).
I also see many Confluent customers talking about their challenges to deploy analytic models to a mission-critical, scalable production environment. This is a completely different story than “just” developing a great, accurate model in R or Python. Educating them how Apache Kafka and Kafka Streams can help here is a key task for me these days… 🙂 This leads to many very interesting and disrupting use cases! I will blog more about this in the next months. For example, I will show an example where I train a neural networks with the concept of autoencoders to build analytic models. Some use cases for this: Anomaly detection for predictive maintenance, fraud, customer churn, etc. These neural networks will then be deployed and monitored with Apache Kafka and its Streams API.
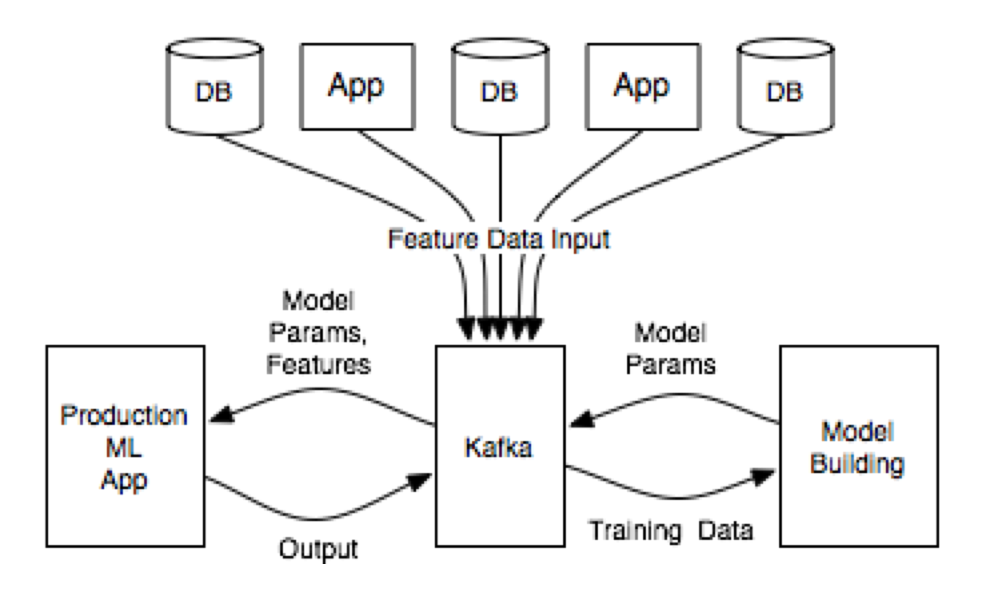
Intelligent real time applications are a game changer in any industry. This session explains how companies from different industries build intelligent real time applications. The first part of this session explains how to build analytic models with R, Python or Scala. No matter which language you favor, you can leverage open source machine learning / deep learning frameworks like TensorFlow, DeepLearning4J or H2O.ai. The second part discusses the deployment of these built analytic models to your own applications or microservices. Here you leverage the Apache Kafka cluster and Kafka’s Streams API instead of setting up a new, complex stream processing cluster. The session focuses on live demos. It also teaches lessons learned for executing analytic models in a highly scalable, mission-critical and performant way.
You can find the Java code examples and analytic models for H2O and TensorFlow in my Github project.
Just clone the repository and run “maven clean package”. Then take a look at the Unit Tests to understand how to apply analytic models with Apache Kafka’s Streams API.
Finally, here we go with the video recording:
As always, I appreciate any comments (feedback, questions, criticism)… Have fun watching the video.
You can also see a corresponding slide deck:
You are currently viewing a placeholder content from Default. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
ERP modernization fails when the technology leads and the process work follows. Three German manufacturers…
Most organizations start their data governance journey by asking how to track where data comes…
Every enterprise is being told to go agentic. Meanwhile, the platforms holding your most critical…
AI agents fail in production when they are connected directly to raw event streams. Flink…
Complex Event Processing is the most underused capability in Apache Flink. It detects meaningful event…
MCP, REST/HTTP APIs, and Apache Kafka are not alternatives. They solve different problems at different…
{kind=link}