Machine Learning / Deep Learning models can be used in different ways to do predictions. My preferred way is to deploy an analytic model directly into a stream processing application (like Kafka Streams or KSQL). You could e.g. use the TensorFlow for Java API. This allows best latency and independence of external services. Several examples can be found in my Github project: Model Inference within Kafka Streams Microservices using TensorFlow, H2O.ai, Deeplearning4j (DL4J).
However, direct deployment of models is not always a feasible approach. Sometimes it makes sense or is needed to deploy a model in another serving infrastructure like TensorFlow Serving for TensorFlow models. Model Inference is then done via RPC / Request Response communication. Organisational or technical reasons might force this approach. Or you might want to leverage the built-in features for managing and versioning different models in the model server.
So you combine stream processing with RPC / Request-Response paradigm. The architecture looks like the following:
Pros of an external model serving infrastructure like TensorFlow Serving:
Cons:
I created the Github Java project “TensorFlow Serving + gRPC + Java + Kafka Streams” to demo how to do model inference with Apache Kafka, Kafka Streams and a TensorFlow model deployed using TensorFlow Serving. The concepts are very similar for other ML frameworks and Cloud Providers, e.g. you could also use Google Cloud ML Engine for TensorFlow (which uses TensorFlow Serving under the hood) or Apache MXNet and AWS model server.
Most ML servers for model serving are also extendible to serve other types of models and data, e.g. you could also deploy non-TensorFlow models to TensorFlow Serving. Many ML servers are available as cloud service and for local deployment.
Let’s discuss TensorFlow Serving quickly. It can be used to host your trained analytic models. Like with most model servers, you can do inference via request-response paradigm. gRPC and REST / HTTP are the two common technologies and concepts used.
The blog post “How to deploy TensorFlow models to production using TF Serving” is a great explanation of how to export and deploy trained TensorFlow models to a TensorFlow Serving infrastructure. You can either deploy your own infrastructure anywhere or leverage a cloud service like Google Cloud ML Engine. A SavedModel is TensorFlow’s recommended format for saving models, and it is the required format for deploying trained TensorFlow models using TensorFlow Serving or deploying on Goodle Cloud ML Engine.
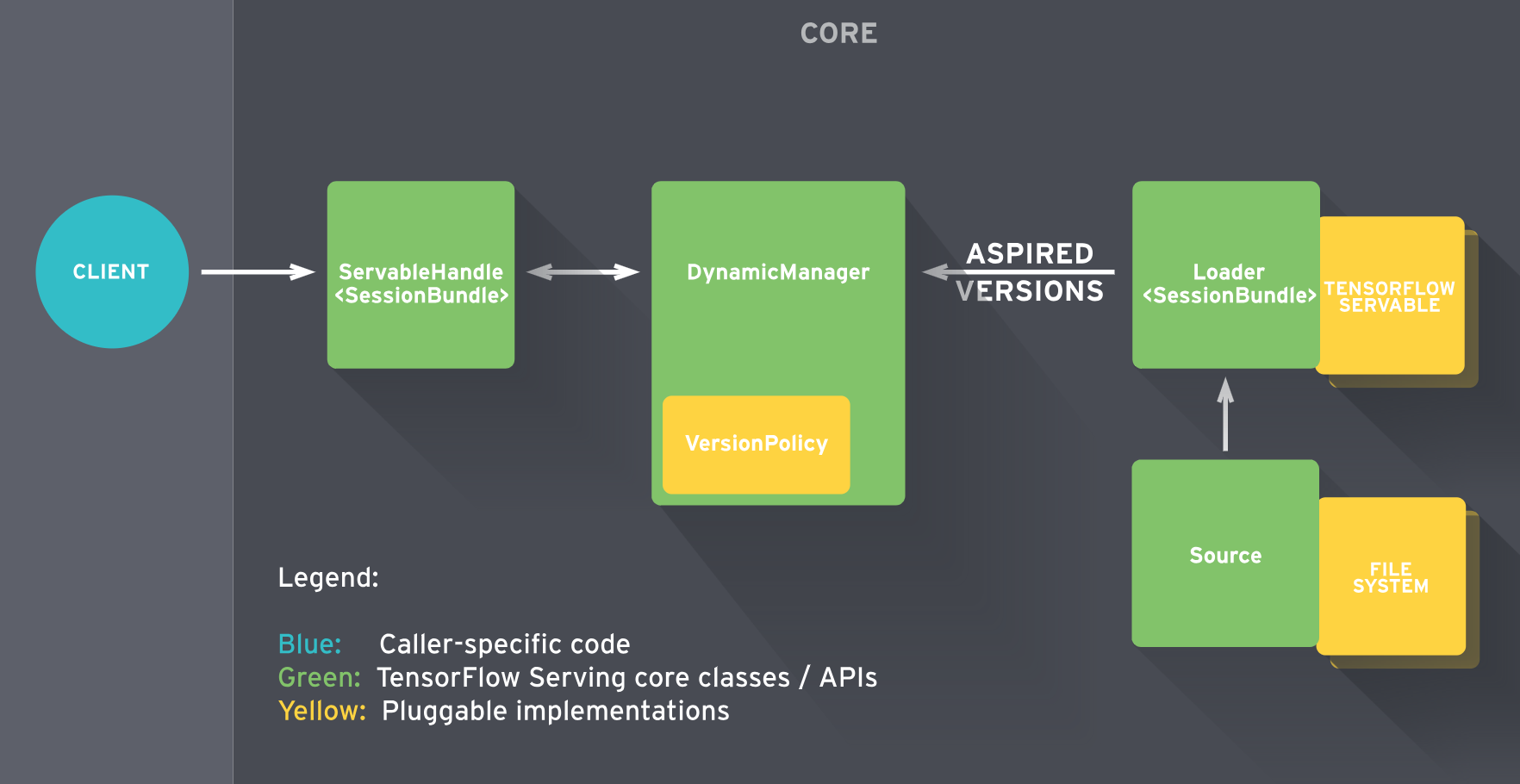
The core architecture is described in detail in TensorFlow Serving’s architecture overview:
This architecture allows deployement and managend of different models and versions of these models including additional features like A/B testing. In the following demo, we just deploy one single TensorFlow model for Image Recognition (based on the famous Inception neural network).
Disclaimer: The following is a shortened version of the steps to do. For full example including source code and scripts, please go to my Github project “TensorFlow Serving + gRPC + Java + Kafka Streams“.
I simply added an existing pretrained Image Recognition model built with TensorFlow. You just need to export a model using TensorFlow’s API and then use the exported folder. TensorFlow uses Protobuf to store the model graph and adds variables for the weights of the neural network.
Google ML Engine shows how to create a simple TensorFlow model for predictions of census using the “ML Engine getting started guide“. In a second step, you can build a more advanced example for image recognition using Transfer Learning folling the guide “Image Classification using Flowers dataset“.
You can also combine cloud and local services, e.g. build the analytic model with Google ML Engine and then deploy it locally using TensorFlow Serving as we do.
Different options are available. Installing TensforFlow Serving on a Mac is still a pain in mid of 2018. apt-get works much easier on Linux operating systems. Unforunately there is nothing like a ‘brew’ command or simple zip file you can use on Mac. Alternatives:
If you want to your own model, read the guide “Deploy TensorFlow model to TensorFlow serving“. Or to use a cloud service, e.g. take a look at “Getting Started with Google ML Engine“.
Create a local Kafka environment (Apache Kafka broker + Zookeeper). The easiest way is the open source Confluent CLI – which is also part of Confluent Open Source and Confluent Enteprise Platform. Just type “confluent start kafka“.
You can also create a cluster using Kafka as a Service. Best option is Confluent Cloud – Apache Kafka as a Service. You can choose between Confluent Cloud Professional for “playing around” or Confluent Cloud Enterprise on AWS, GCP or Azure for mission-critical deployments including 99.95% SLA and very large scale up to 2 GBbyte/second throughput. The third option is to connect to your existing Kafka cluster on premise or in cloud (note that you need to change the broker URL and port in the Kafka Streams Java code before building the project).
Next create the two Kafka topics for this example (‘ImageInputTopic’ for URLs to the image and ‘ImageOutputTopic’ for the prediction result):
The Kafka Streams microservice (i.e. Java class) “Kafka Streams TensorFlow Serving gRPC Example” is the Kafka Streams Java client. The microservice uses gRPC and Protobuf for request-response communication with the TensorFlow Serving server to do model inference to predict the contant of the image. Note that the Java client does not need any TensorFlow APIs, but just gRPC interfaces.
This example executes a Java main method, i.e. it starts a local Java process running the Kafka Streams microservice. It waits continuously for new events arriving at ‘ImageInputTopic’ to do a model inference (via gRCP call to TensorFlow Serving) and then sending the prediction to ‘ImageOutputTopic’ – all in real time within milliseconds.
In the same way, you could deploy this Kafka Streams microservice anywhere – including Kubernetes (e.g. on premise OpenShift cluster or Google Kubernetes Engine), Mesosphere, Amazon ECS or even in a Java EE app – and scale it up and down dynamically.
Now send messages, e.g. with kafkacat, and use kafka-console-consumer to consume the predictions.
Once again, if you want to see source code and scripts, then please go to my Github project “TensorFlow Serving + gRPC + Java + Kafka Streams“.
Complex Event Processing is the most underused capability in Apache Flink. It detects meaningful event…
MCP, REST/HTTP APIs, and Apache Kafka are not alternatives. They solve different problems at different…
The Enterprise Agentic AI Landscape 2026 maps every major AI vendor across two dimensions that…
Agentic AI without governed processes is fast but ungoverned. Event-driven integration without process intelligence moves…
Two toolchains, two skill sets, two CI/CD pipelines — that has been the reality for…
The Shift Left Architecture moves data integration logic into an event-driven architecture where governed data…
{kind=link}
{kind=link}