Confluent Operator is now GA for production deployments (Download Confluent Operator for Kafka here). This is a Kafka Operator for Kubernetes which provides automated provisioning and operations of an Apache Kafka cluster and its whole ecosystem (Kafka Connect, Schema Registry, KSQL, etc.) on any Kubernetes infrastructure.
I want to share a slide deck which explains:
Software as a Service (SaaS) and Serverless Platforms provide software and services in the public cloud as managed service. Cloud-native infrastructures allow you to leverage the features of SaaS / Serverless in your own self-managed infrastructure (either on premise or in public cloud, and without vendor-lockin).
What is Cloud Native? Many different definitions exist on the web. Two definitions which I like are “The Twelve-Factor App” and “10 key characteristics of The New Stack“.
Some of the key benefits of cloud-native infrastructures:
This is very different from traditional bare metal or VM infrastructures. Even if you use containers like Docker, you don’t automatically get above benefits. Providing cloud-native infrastructure is a key requirement to build a DevOps infrastructure and culture. Note that technology is just one part of a fully successful DevOps mentality, of course.
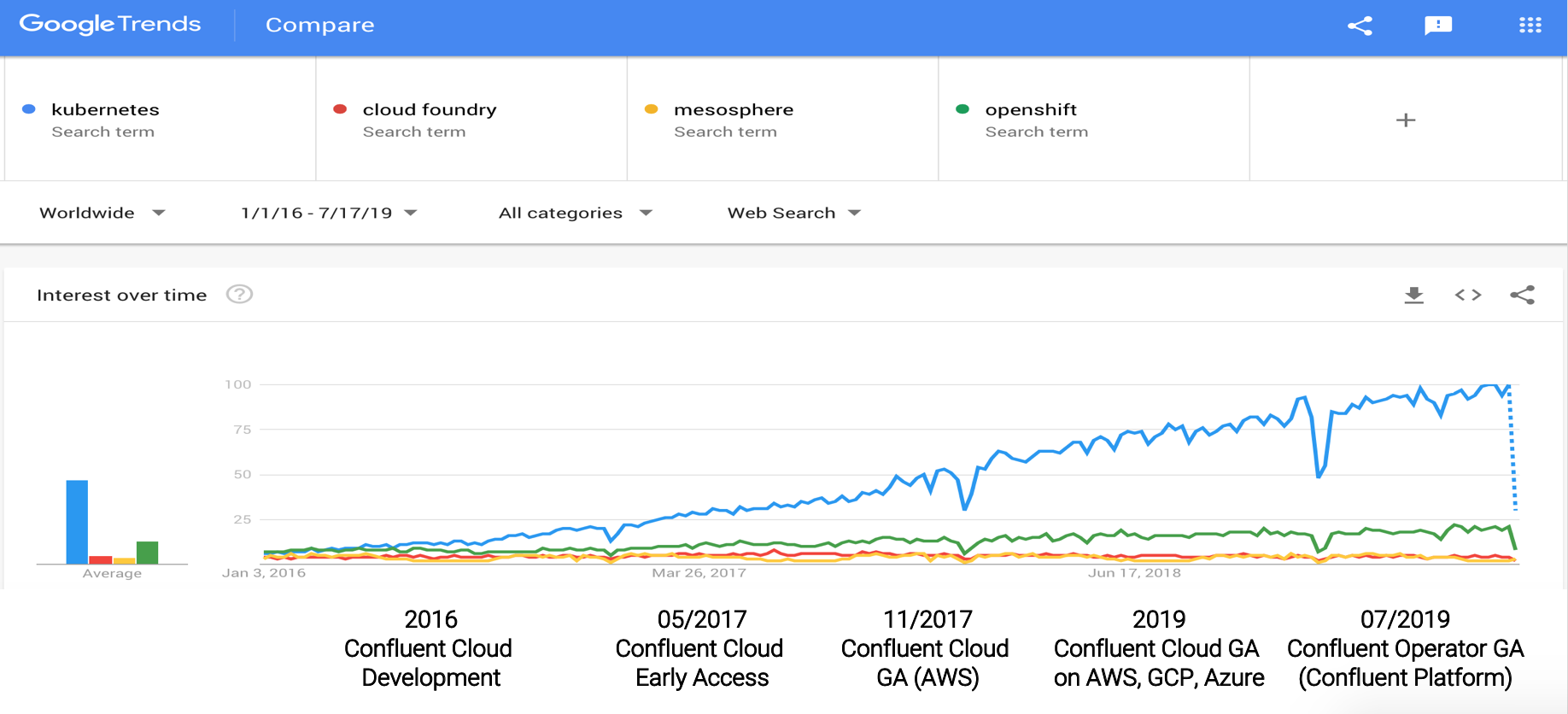
In the beginning, many cloud-native container platforms built their own cloud-native technology and infrastructure. Many of these solutions were open source, but only one took over. Just take a look at these Google Trends of last five years:
In the meantime, most cloud-native infrastructure providers (such as Red Hat OpenShift, Mesosphere, Pivotal Cloud Foundry) moved their whole strategy around supporting Kubernetes. These vendors enhance the user experience and add additional features to differentiate from vanilla Kubernetes. OpenShift made this decision a few years earlier than most others; take a look how the above trends reflect this decision. Furthermore, Kubernetes is also available as managed service on all major cloud providers (AWS, Azure, GCP) in the meantime.
Kubernetes was mainly used for stateless deployments in the early phases (for instance to deploy REST microservices). Today, people deploy everything on Kubernetes because it adds a lot of value – as discussed in the section about cloud-native infrastructure above. This includes the Kafka backend and clients.
Stateful deployments of backend services leverage the Kubernetes Operator pattern. For many infrastructure components, like databases, messaging, search engines, etc. The implementation of the Operator Pattern includes standard Kubernetes objects like StatefulSets, ConfigMaps, Secrets and Persistent Volumes. However, the secret sauce are the custom Kubernetes Controller and Custom Resource Definitions (CRDs) which implement unique application functionality for the specific stateful deployment.
Apache Kafka became the de facto standard for event streaming platforms. Apache Kafka and its ecosystem provides a powerful option to build reliable, scalable, mission-critical distributed systems. Therefore, as you can image, it is harder to operate than a traditional messaging system or database which do not scale elastically without downtime and just use active/passive for high availability.
Kubernetes environments are similar: Very powerful but not easy to operate. Hence the combination of both, Kafka and Kubernetes, does not make it easier. Here are some challenges running the Apache Kafka ecosystem on Kubernetes:
This is the secret sauce which a Kubernetes Operator has to implement and automate. Consequently, a Kafka Operator sounds like a very good and valuable component.
Confluent has long experience running Kafka on Kubernetes:
Confluent Cloud runs on Kubernetes using a Kafka Operator to offer “Serverless Kafka”: Confluent Cloud provides mission-critical SLAs on all three major cloud providers (Google GCP, Microsoft Azure, Amazon AWS), consumption-based pricing and throughput of several GB / sec using a single Kafka cluster. Seems like running Kafka on Kubernetes using a Kafka Operator is not a bad idea.
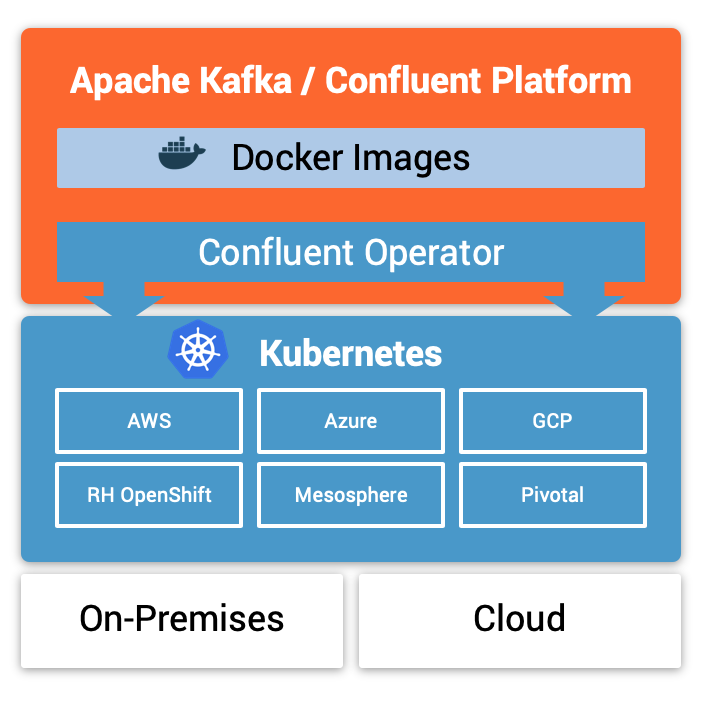
My slide deck describes the journey and the features of Confluent Operator to deploy and operate Kafka in a cloud-native way similar to how Kafka and its ecosystem (like Kafka Connect, Schema Registry, KSQL) is deployed in Confluent Cloud.
Confluent Operator enables you to:
Here is the Agenda of the slide deck:
Click on the button to load the content from www.slideshare.net.
Also check out the documentation for Confluent Operator.
Please let me know if you have any comments or feedback.
The shift from Lambda to Kappa architecture reflects the growing demand for unified, real-time data…
FinOps bridges the gap between finance and engineering to control cloud spend in real time.…
Industrial companies are connecting machines, sensors, and enterprise systems like never before. Real-time data, cloud-native…
Open RAN is transforming telecom by decoupling hardware and software to unlock flexibility, innovation, and…
Regulated FinTech is transforming financial services by combining compliance with innovation. This post explores how…
Mobile Premier League (MPL) is a leading mobile eSports skill-based gaming platform with over 90…
{kind=link}
{kind=link}
{kind=link}
{kind=link}