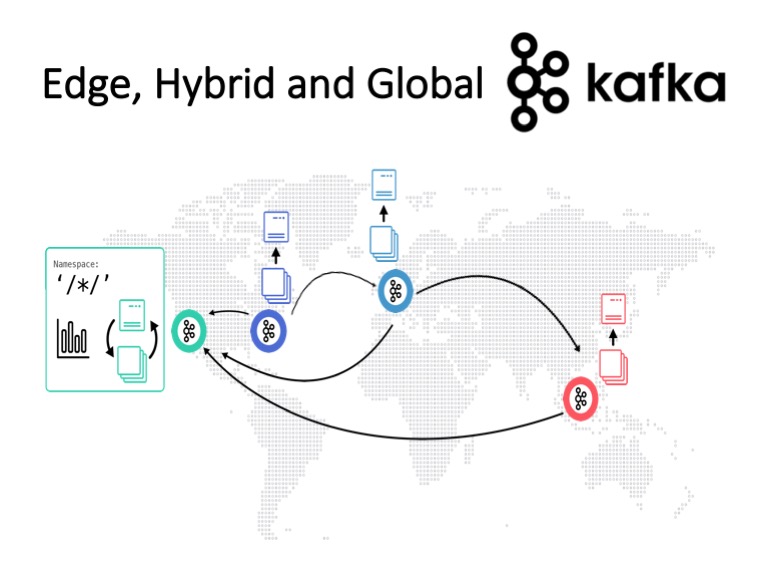
Multi-cluster and cross-data center deployments of Apache Kafka have become the norm rather than an exception. Learn about several scenarios that may require multi-cluster solutions and see real-world examples with their specific requirements and trade-offs, including disaster recovery, aggregation for analytics, cloud migration, mission-critical stretched deployments and global Kafka.
Key takeaways for Multi Data Center Kafka Architectures
- In many scenarios, one Kafka cluster is not enough. Understand different architectures and alternatives for multi-cluster deployments.
- Zero data loss and high availability are two key requirements. Understand how to realize this, including trade-offs.
- Learn about features and limitations of Kafka for multi cluster deployments- Global Kafka and mission-critical multi-cluster deployments with zero data loss and high availability became the normal, not an exception.
- Learn about architectures like stretched cluster, hybrid integration and fully-managed serverless Kafka in the cloud (using Confluent Cloud), and tools like MirrorMaker 2, Confluent Replicator, Multi-Region Clusters (MRP), Global Kafka, and more.
Slide Deck
Click on the button to load the content from www.slideshare.net.
Video Recording

By loading the video, you agree to YouTube’s privacy policy.
Learn more






