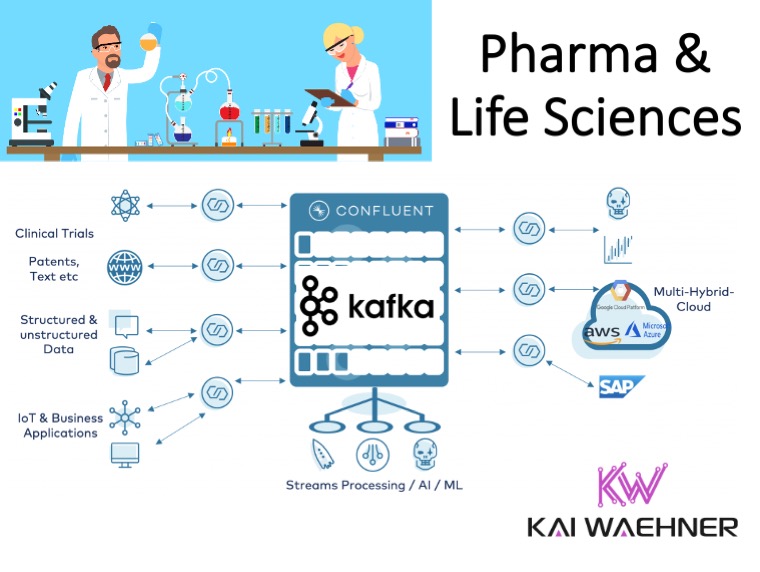
This blog post covers use cases and architectures for Apache Kafka and Event Streaming in Pharma and Life Sciences. The technical example explores drug development and discovery with real time data processing, machine learning, workflow orchestration and image / video processing.
Use Cases in Pharmaceuticals and Life Sciences for Event Streaming and Apache Kafka
The following shows some of the use cases I have seen in the field in pharma and life sciences:
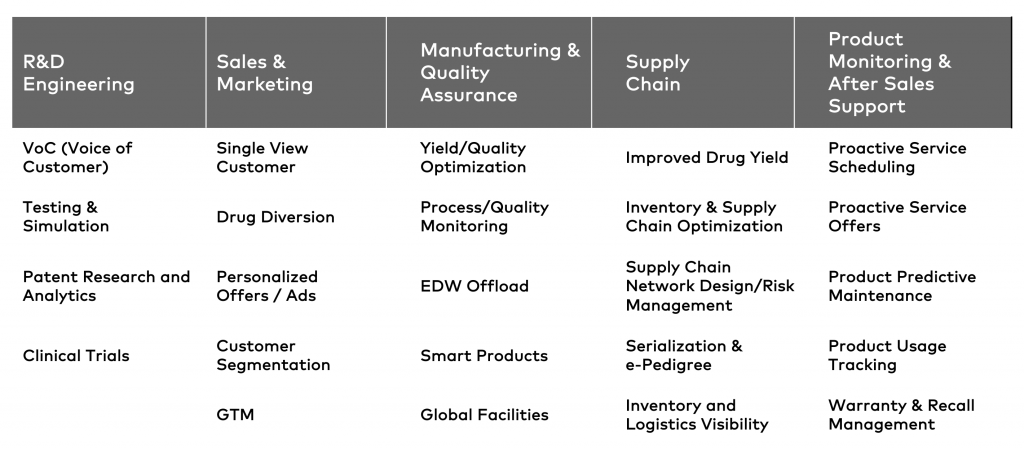
Many of them have in common that they are not new. But event streaming at scale in real time can help improve the processes and allow innovative new applications. Therefore Apache Kafka is a perfect fit for the Pharma and Life Science industry. Having said this, starting with a use case and goal is important to add business value:
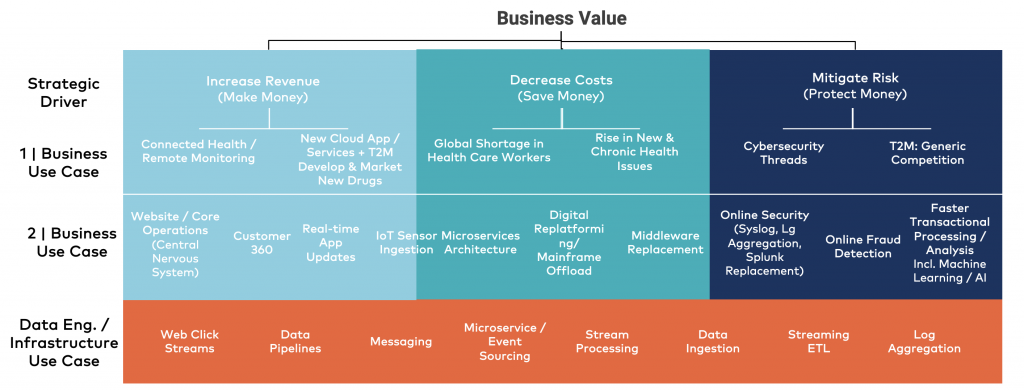
From a technical perspective, the next step is drilling down into technologies as you can see in the above picture. Typically, you combine different concepts like ‘data pipelines’ and ‘stream processing’ to implement the business solution.
Generate Added Value from your Data
The pharmaceutical and life science industry today has an unprecedented wealth of opportunities to generate added value from data.
These possibilities cover all relevant areas such as:
- R&D / Engineering
- Sales and Marketing
- Manufacturing and Quality Assurance
- Supply Chain
- Product Monitoring / After Sales Support
Novel data use:
- Better therapies
- Faster and more accurate diagnoses
- Faster drug development
- Improvement of clinical studies
- Real-World Data Generation
- real-world evidence
- Precision Medicine
- Support Remote Health etc
Challenges:
- Data silos
- Integration between different technologies and communication paradigms
- Data growth / explosion
- Cloud / on-premises / hybrid
- Use of new technologies like Artificial Intelligence (AI) / Machine Learning (ML)
- Time to market
- Regulatory affairs
- Security
- Performance (throughput, scale and speed)
- Open API interfaces
Let’s now take a look at how to solve these challenges to add value from existing data…
Event Streaming for Data Processing at Scale in Real Time
Here are a few examples of Pharma and Life Sciences companies relying on event streaming with Kafka and its ecosystem:
- Invitae: Combination of Data Science and 24/7 Production Deployment
- Babylon Health: Connectivity and Agile Microservice Architecture
- Bayer AG: On Premise / Cloud / Hybrid Real Time Replication at Scale
- celmatrix: Real Time Aggregation of Heterogeneous Data + Governance / Security
These companies spoke on a past Kafka Summit about their use cases. Find more details in the linked slides and video recordings.
All of them have in common that the event streaming platform based on Apache Kafka is the heart of their integration and data processing infrastructure:
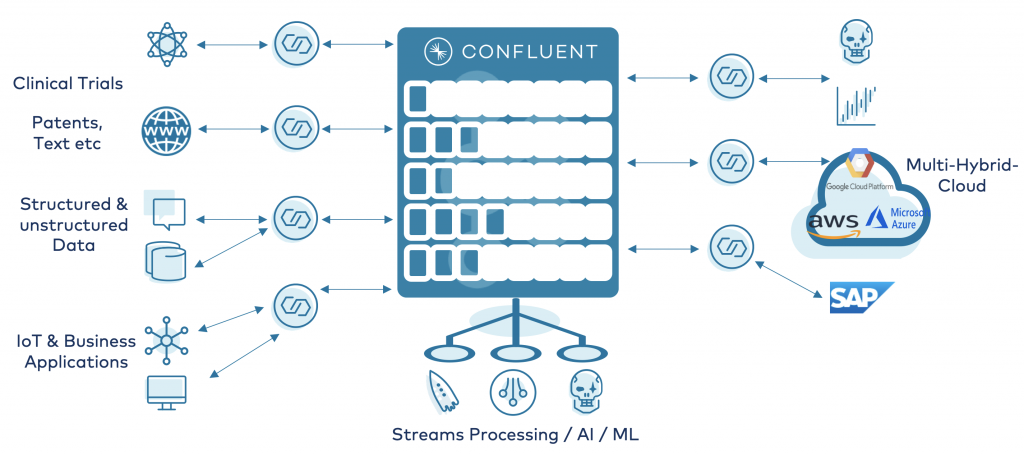
Let’s now take a look at a concrete example to go into more details.
Pharma Use Case: Drug Research and Development with Kafka
I want to cover one specific use case: Drug Discovery. Honestly, I am not an expert in this area. Therefore, I use examples from the company ‘Recursion Pharmaceutical’. They presented at a past Kafka Summit about “Drug Discovery at Scale in Real Time with Kafka Streams“.
Cost Reduction and Faster Time-to-Market
The motivation for improving the drug development process is pretty clear: Cost reduction and faster time-to-market.
Here are a few quotes from McKinsey & Company:
- “Collectively, the top 20 pharmaceutical companies spend approximately $60 billion on drug development each year, and the estimated average cost of bringing a drug to market (including drug failures) is now $2.6 billion—a 140 percent increase in the past ten years.”
- “It should be possible to bring medicines to the market 500 days faster, which would create a competitive advantage within increasingly crowded asset classes and bring much-needed therapies to patients sooner. To transform drug development, this acceleration can be combined with improved quality and compliance, enhanced patient and healthcare-professional experience, better insights and decision making, and a reduction in development costs of up to 25 percent.”
- “The McKinsey Global Institute1 estimates that applying big-data strategies to better inform decision making could generate up to $100 billion in value annually across the US health-care system, by optimizing innovation, improving the efficiency of research and clinical trials, and building new tools for physicians, consumers, insurers, and regulators to meet the promise of more individualized approaches.”
The Drug Research and Development Process
The process for drug discovery is long and complex:
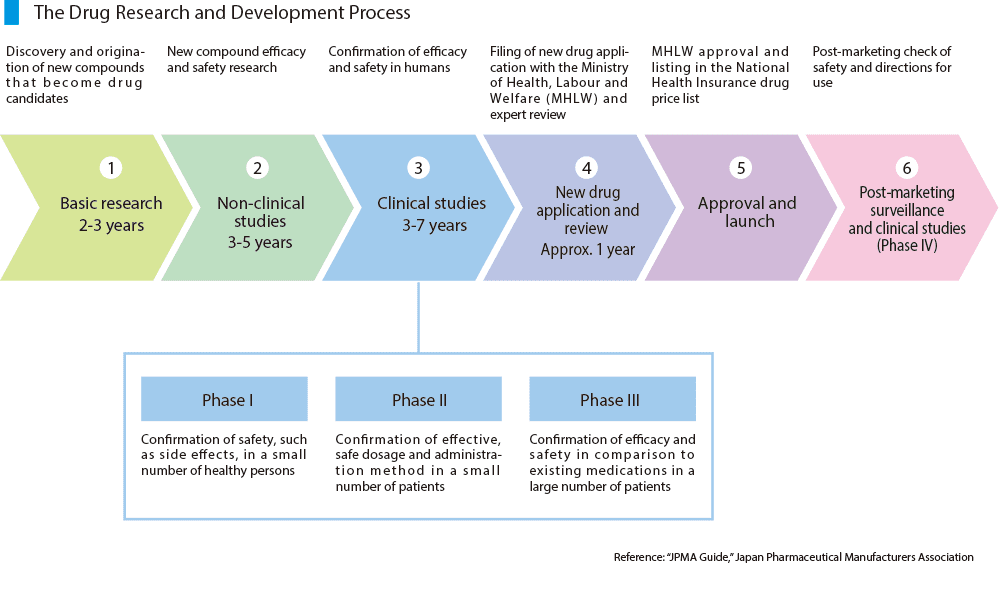
As you can see, the drug development process takes many years. Part of that reason is that drug discovery requires a lot of clinical studies doing data processing and analytics of big data sets.
Drug Discovery At Scale in Real Time with Kafka Streams
Recursion Pharmaceutical went from ‘drug discovery in manual and slow, not scalable, bursty BATCH MODE’ to ‘drug discovery in automated, scalable, reliable REAL TIME MODE’
They created a massively parallel system that combines experimental biology, artificial intelligence, automation and real-time event streaming to accelerate drug discovery:
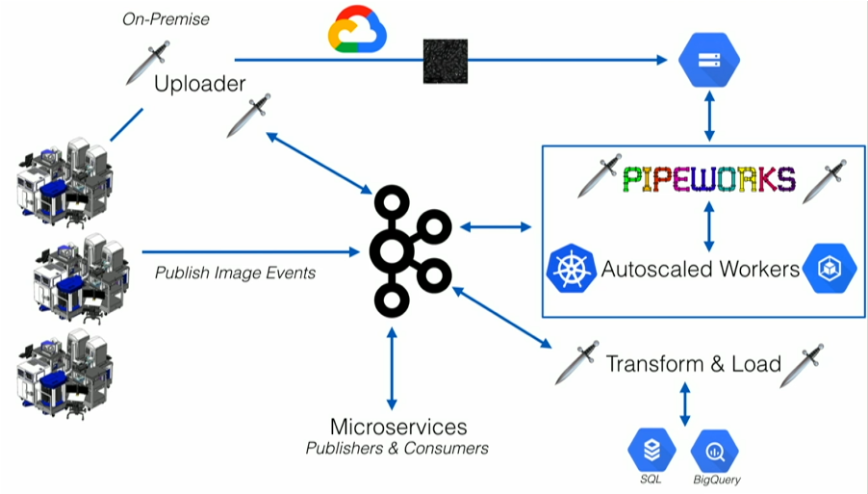
This hybrid event streaming architecture is explained in more detail in Recursion Pharmaceutical’s Kafka Summit talk.
Streaming Machine Learning in Pharma and Life Sciences with Kafka
While Recursion Pharmaceutical showed a concrete example, I want to share a more general view of such an architecture in the following…
Streaming Analytics for Drug Discovery in Real Time at Scale
The following is a possible solution to do data processing based on business rules (e.g. feature engineering or filtering) in conjunction with machine learning (e.g. image recognition using a convolutional neural network / CNN):
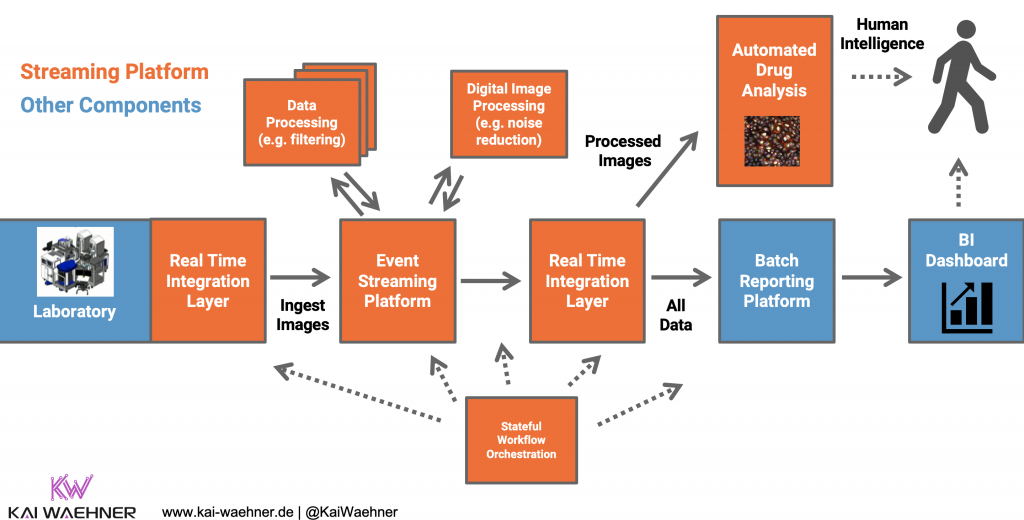
Such an infrastructure typically combines modern technologies with old, legacy interfaces (like file processing on a old Windows server). Different programming languages and tools are used in different parts of the process. It is not uncommon to see Python, Java, .NET and some proprietary tools in one single workflow.
Kafka + ksqlDB + Kafka Streams + .NET + TensorFlow
The following maps the above use case to concrete cutting-edge technologies:
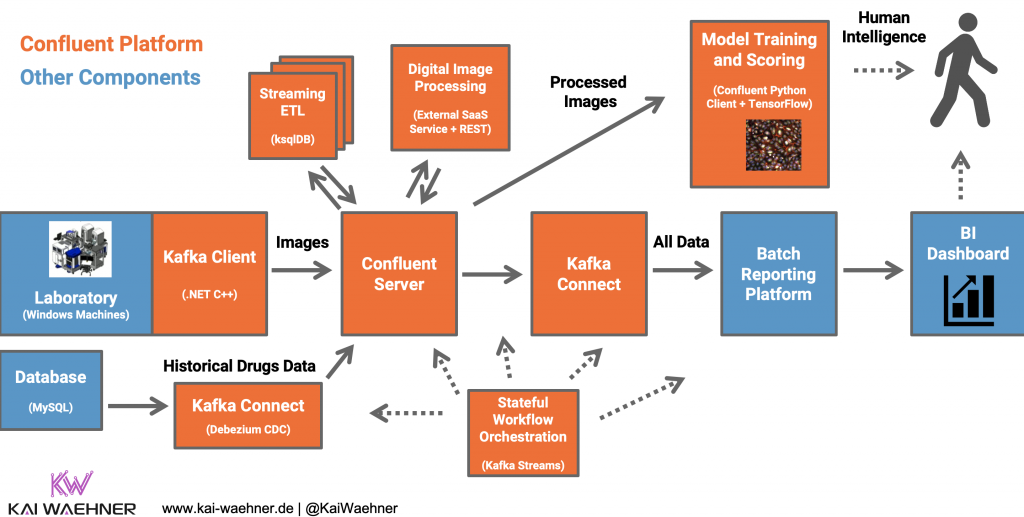
What makes this architecture exciting?
- Data processing and correlation at scale in real time
- Integration with any data source and sink (no matter if real time, batch or request-response)
- Single machine learning pipeline for model training, scoring and monitoring
- No need for a data lake (but you can use one if you want or have to, of course)
- Combination of different technologies to solve the impedance mismatch between different teams (like Python for the data scientist, Java for the production engineer, and Tableau for the business expert)
- Compatibility with any external system (no matter if modern or legacy, no matter if open or proprietary, no matter if edge, on premise data center or cloud)
I did not have the time to implement this use case. But the good news is that there is a demo available showing exactly the same architecture and combination of technologies (showcasing a connected car infrastructure for real time data processing and analytics at scale in real time). Check out the Blog and video or the Github project for more details.
Image / Video Processing, Workflow Orchestration, Middleware…
I want to cover a few more topics which come up regularly when I discuss Kafka use cases with customers from pharma, life sciences and other industries:
- Image / video processing
- Workflow orchestration
- Middleware and integration with legacy systems
Each one is worth its own blog post, but the following will guide you into the right direction.
Image / Video Processing with Apache Kafka
Image and video processing is a very important topic in many industries. Many pharma and life sciences processes require it, too.
The key question: Can and should you do image / video processing with Kafka? Or how does this fit into the story at all?
Alternatives for Processing Large Payloads with Kafka
Several alternatives exists (and I have seen all three in the field several times):
- Kafka-native image / video processing: This is absolutely doable! You can easily increase the maximum message size (from the 1Mb default to any value which makes sense for you) and stream images or videos through Kafka. If have seen a few deployments where Kafka was combined with a video buffering framework on the consumer side. Processing images from video cameras is a good example. It does not matter if you combine Kafka with image processing frameworks like OpenCV or with Deep Learning frameworks like TensorFlow.
- Split + re-assemble large messages: Big messages can be chunked into smaller messages and aggregated on the consumer side. This makes a lot of sense for binary data (like images). If the input is a delimited CSV file or JSON / XML, another option is to split the data up so that only the chunks are processed by consumers.
- Metadata-only and object store: Kafka messages only contain the metadata and the link to the image / video. The actual data is store in an external storage (like AWS S3 object storage).
- Externalizing large payloads: Receive the large payload but filter and externalize it before sending the data to Kafka. Kafka Connect’s SMT (Single Message Transformations) are a great way to implement this. This enterprise integration pattern (EIP) is called ‘Claim Check Pattern‘. A source connector could receive the payload with the image, filter and store the image into another data store, and send the payload (including an added link to the image) to Kafka. A sink connector can use a SMT similarly to load an image from the data store before sending it to another sink system.
All approaches are valid and have their pros and cons.
Large Payload Handling at LinkedIn
LinkedIn did a great presentation in 2016 about this topic. Here are their trade-offs for sending large messages via Kafka vs. sending just the reference link:
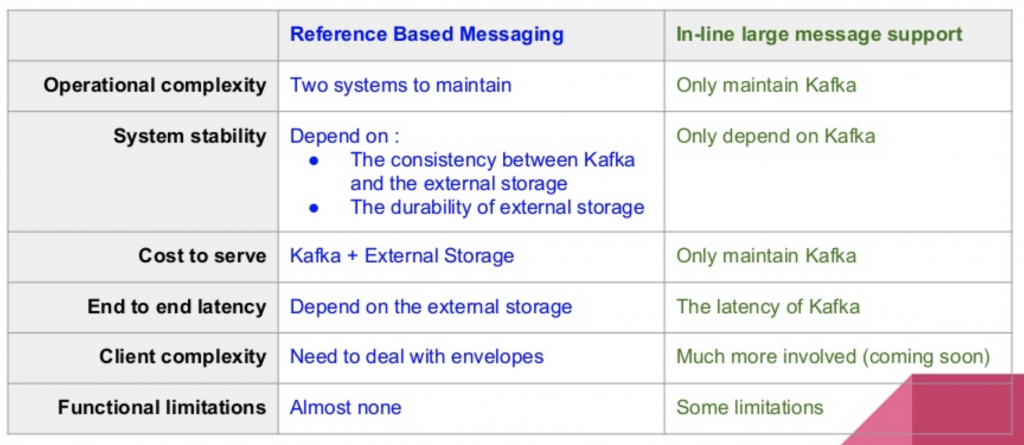
Please keep in mind that this presentation was done in 2016. Kafka and its ecosystem improved a lot since that time. Infrastructures also changed a lot regarding scalability and cost. Therefore, find the right architecture and cost structure for your use case!
UPDATE 2020: I wrote a blog post about the current status of processing large messages with Kafka. Check it out for the latest capabilities and use cases.
Workflow Orchestration of Pharma Processes with Apache Kafka
Business processes are often complex. Some can be fully automated. Others need human interaction. In short, there are two approaches for Workflow Orchestration in a Kafka infrastructure:
- Kafka-native Workflow Orchestration: The Orchestration is implemented within a Kafka application. This is pretty straightforward for streaming data, but more challenging for long-running processes with human interaction. For the latter, you obviously should build a nice UI on top of the streaming app. Dagger is a dynamic realtime stream processing framework based on Kafka Streams for task assignment and workflow management. Swisscom also presented their own Kafka Streams based orchestration engine at a Kafka Meetup in Zurich in 2019.
- External Business Process Management (BPM) Tool: Plenty of workflow orchestration tools and BPM engines exist on the market. Both open source and proprietary. Just to give one example, Zeebe is a modern, scalable open source workflow engine. It actually provides a Kafka Connect connector to easily combine event streaming with the orchestration engine.
The advantage of Kafka-native workflow orchestration is that there is only one infrastructure to operate 24/7. But if it is not sufficient or you want to use a nice, pre-built UI, then nothing speaks against combining Kafka with an external workflow orchestration tool.
Integration with Middleware and Legacy Systems like Mainframes or Old ERP Systems
I pointed this out above already, but want to highlight it again in its own section: Apache Kafka is a great technology to deploy a modern, scalable, reliable middleware. In pharma and life sciences, many different technologies, protocols, interfaces and communication paradigms have to be integrated with each other. From Mainframe and batch systems to modern big data analytics platforms and real time event streaming applications.
Kafka and its ecosystem are a perfect fit:
- Building a scalable 24/7 middleware infrastructure with real time processing, zero downtime, zero data loss and integration to legacy AND modern technologies, databases and applications
- Integration with existing legacy middleware (ESB, ETL, MQ)
- Replacement of proprietary integration platforms
- Offloading from expensive systems like Mainframes
The following shows how you can leverage the Strangler Design Pattern to integrate and (partly) replace legacy systems like mainframes:
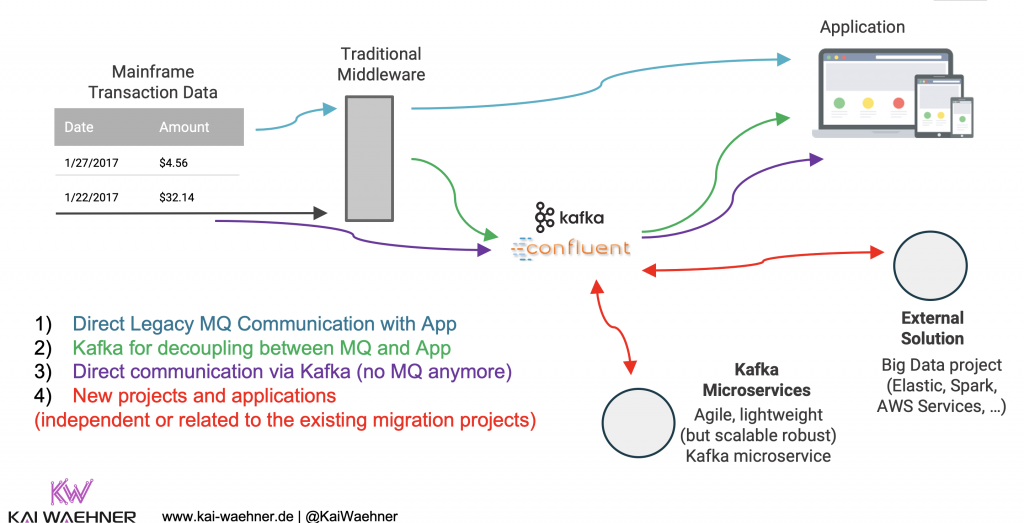
If you think about using the Kafka ecosystem in your Pharma or Life Science projects, please check out my blogs, slides and videos about Apache Kafka vs. Middleware (MQ, ETL, ESB) and “Mainframe Offloading and Replacement with Apache Kafka“.
Slides and Video Recording for Kafka in Pharma and Life Sciences
I created some slides and a video recording discussing Apache Kafka and Machine Learning in Pharma and Life Sciences. Check it out:
Slides:
Click on the button to load the content from www.slideshare.net.
Video recording:

By loading the video, you agree to YouTube’s privacy policy.
Learn more
Generate Added Value with Kafka in Pharma and Life Sciences Industry
The pharmaceutical and life science industry today has an unprecedented wealth of opportunities to generate added value from data. Apache Kafka and Event Streaming are a perfect fit. This includes scalable big data pipelines, machine learning for real time analytics, image / video processing, and workflow orchestration.
What are your experiences in pharma and life science projects? Did you or do you plan to use Apache Kafka and its ecosystem? What is your strategy? Let’s connect on LinkedIn and discuss!






