The energy industry is changing from system-centric to smaller-scale and distributed smart grids and microgrids. A smart grid requires a flexible, scalable, elastic, and reliable cloud-native infrastructure for real-time data integration and processing. This post explores use cases, architectures, and real-world deployments of event streaming with Apache Kafka in the energy industry to implement a smart grid and real-time end-to-end integration.

Smart Grid – The Energy Production and Distribution of the Future
The energy sector includes corporations that primarily are in the business of producing or supplying energy such as fossil fuels or renewables.
What is a Smart Grid?
A smart grid is an electrical grid that includes a variety of operation and energy measures,, including smart meters, smart appliances, renewable energy resources, and energy-efficient resources. Electronic power conditioning and control of the production and distribution of electricity are important aspects of the smart grid.
The European Union Commission Task Force for Smart Grids provides smart grid definition as:
“A Smart Grid is an electricity network that can cost-efficiently integrate the behavior and actions of all users connected to it – generators, consumers and those that do both – to ensure economically efficient, sustainable power system with low losses and high levels of quality and security of supply and safety. A smart grid employs innovative products and services, together with intelligent monitoring, control, communication, and self-healing technologies to:
- Better facilitate the connection and operation of generators of all sizes and technologies.
- Allow consumers to play a part in optimizing the operation of the system.
- Provide consumers with greater information and options for how they use their supply.
- Significantly reduce the environmental impact of the whole electricity supply system.
- Maintain or even improve the existing high levels of system reliability, quality, and security of supply.
- Maintain and improve existing services efficiently.”
Technologies and Evolution of a Smart Grid
The Roll-out of smart grid technology also implies a fundamental re-engineering of the electricity services industry, although typical usage of the term is focused on the technical infrastructure. Key smart grid technologies include solar power, smart meters, microgrids, and self-optimizing systems:
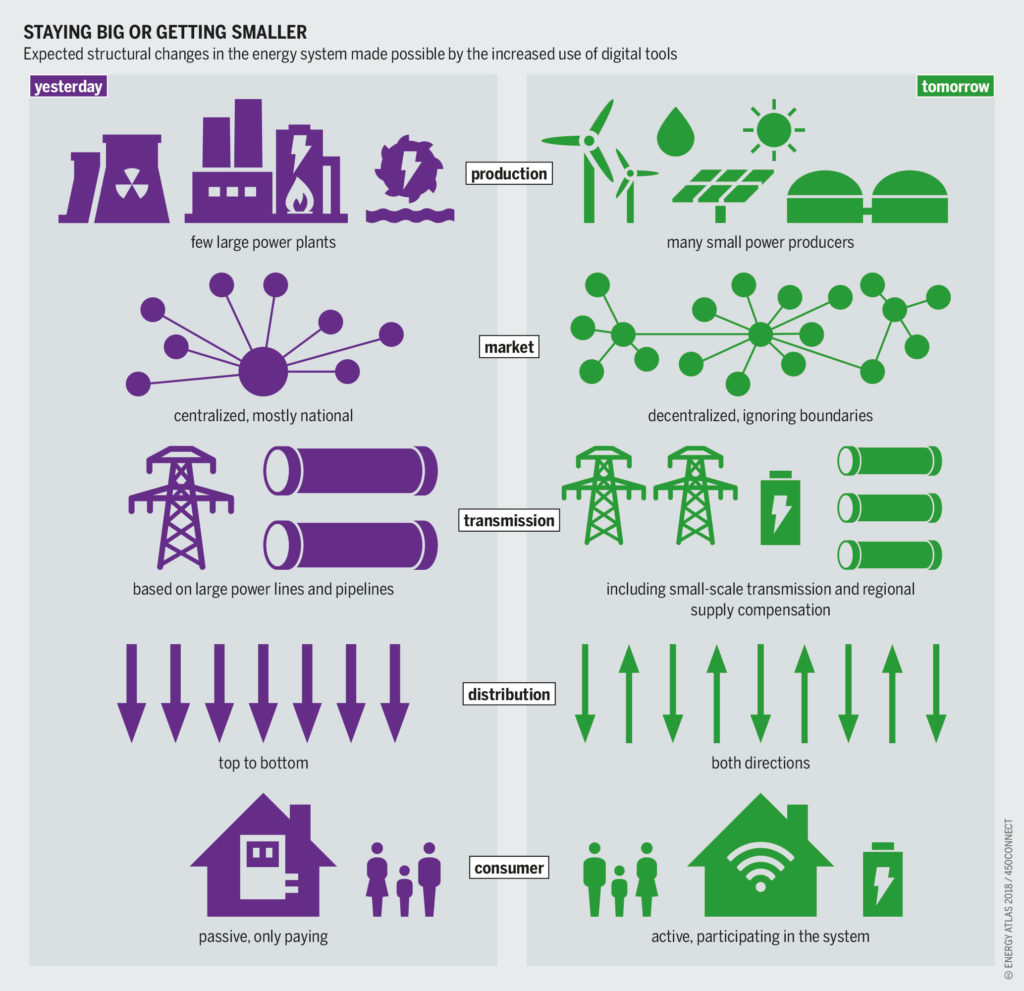
Requirements for a Smart Grid and Modern Energy Infrastructure
- Reliability: The smart grid uses technologies such as state estimation which improve fault detection and allow self-healing of the network without the intervention of technicians. This will ensure a more reliable supply of electricity and reduced vulnerability to natural disasters or attack.
- Flexibility in network topology: Next-generation transmission and distribution infrastructure will be better able to handle possible bidirectional energy flows, allowing for distributed generation such as from photovoltaic panels on building roofs, but also charging to/from the batteries of electric cars, wind turbines, pumped hydroelectric power, the use of fuel cells, and other sources.
- Efficiency: Numerous contributions to the overall improvement of the efficiency of energy infrastructure are anticipated from the deployment of smart grid technology, in particular including demand-side management, for example, turning off air conditioners during short-term spikes in electricity price, reducing the voltage when possible on distribution lines through Voltage/VAR Optimization (VVO), eliminating truck-rolls for meter reading, and reducing truck-rolls by improved outage management using data from Advanced Metering Infrastructure systems. The overall effect is less redundancy in transmission and distribution lines and greater utilization of generators, leading to lower power prices.
- Sustainability: The smart grid’s improved flexibility permits greater penetration of highly variable renewable energy sources such as solar power and wind power, even without the addition of energy storage.
- Market-enabling: The smart grid allows for systematic communication between suppliers (their energy price) and consumers (their willingness-to-pay. It permits both the suppliers and the consumers more flexible and sophisticated operational strategies.
- Cybersecurity: Provide a secure infrastructure with encrypted and authenticated communication and real-time anomaly detection at scale across the supply chain.
Architectures with Kafka for a Smart Grid
From a technical perspective, use cases such as load adjustment/load balancing or peak curtailment/leveling and time of use pricing cannot be implemented with traditional, monolith software like they were used in the past in the energy industry.
A smart grid requires a cloud-native infrastructure that is flexible, scalable, elastic, and reliable. All of that in combination with real-time data integration and data processing. These requirements explain why more and more energy companies rely heavily on event streaming with Apache Kafka and its ecosystem.
Energy Production and Distribution with a Hybrid Architecture
Many energy companies have a cloud-first strategy. They build new innovative applications in the cloud. Especially in the energy industry, this makes a lot of sense. The need for elastic and scalable data processing is key to success. However, not everything can run in the cloud. Most energy-related use cases required data processing at the edge, too. This is true for energy production and energy distribution.
Here is an example architecture leveraging Apache Kafka in the cloud and at the edge:
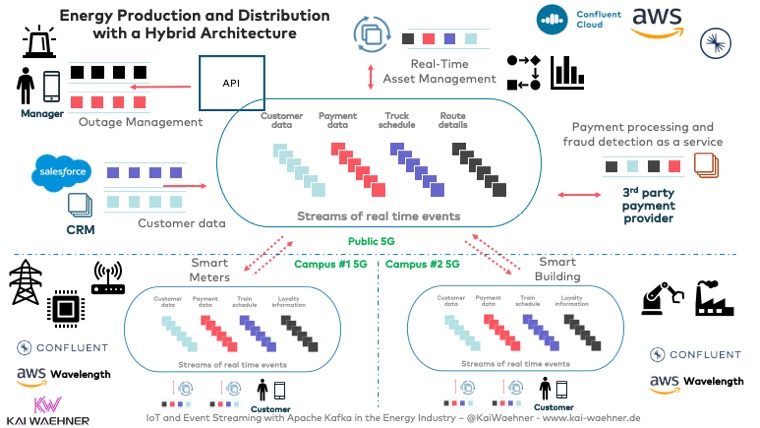
The integration in the cloud requires connecting to modern technologies such as Snowflake data warehouse, Google’s Machine Learning services based on TensorFlow, or 3rd party SaaS services like Salesforce. The edge is different. Connectivity is required for machines, equipment, sensors, PLCs, SCADA systems, and many other systems. Kafka Connect is a perfect, Kafka-native tool to implement these integrations in real-time at scale.
Replication in real-time between the edge sites and the cloud is another important case where tools like MirrorMaker 2 or Confluent’s Cluster Linking fit perfectly.
The continuous processing of data (aka stream processing) is possible with Kafka-native components like Kafka Streams or ksqlDB. Using an external tool such as Apache Flink is also a good fit.
Event Streaming for Energy Production at the Edge with a 5G Campus Network
Kafka at the edge is the new black. Energy production a great example:
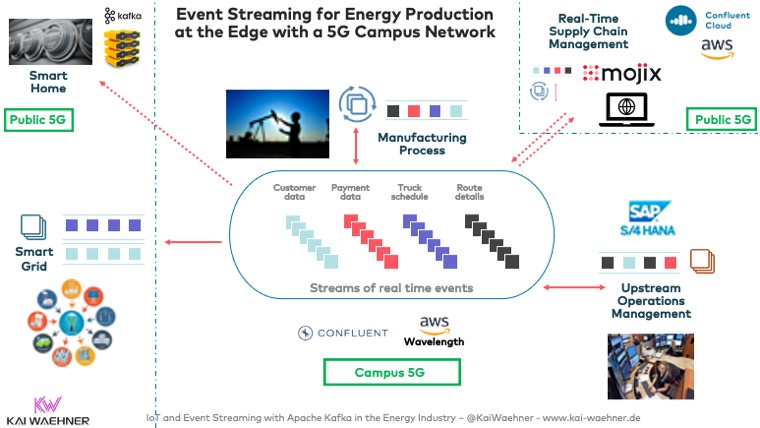
More details about deploying Kafka at edge sites is described in the post “Building a Smart Factory with Apache Kafka and 5G Campus Networks“.
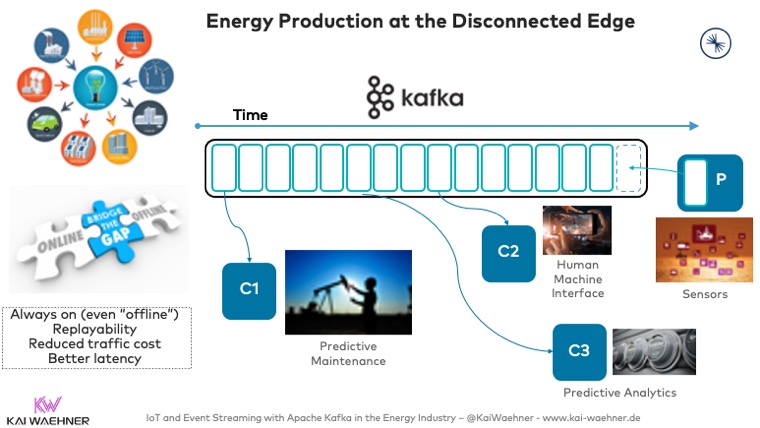
The edge is often disconnected from the cloud or remote data centers. Mission-critical applications have to run 24/7 in a decoupled way even if the internet connection is not available or not stable:
Example: Real-Time Outage Management with Kafka in the Utilities Sector
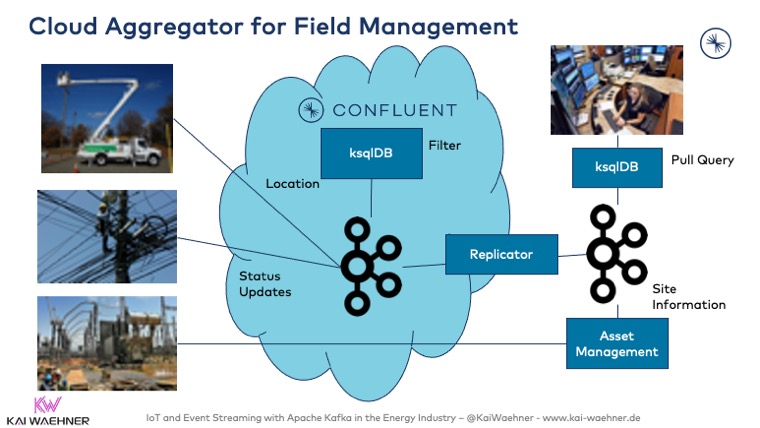
Let’s take a look at an example implemented in the utilities sector: Continous processing of smart meter sensor data with Kafka and ksqlDB:

The preprocessing and filtering happens at the edge, as shown in the above picture. However, the aggregation and monitoring of all the assets of the smart grid (including smart home, smart buildings, powerlines, switches, etc.) happen in the cloud:
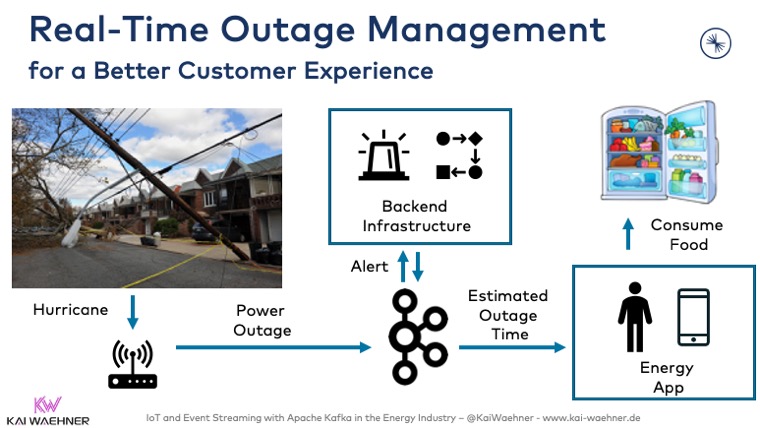
Real-time data processing is not just important for operations. Huge added value comes from the improved customer experience. For instance, the outage management operations tool can alert a customer in real-time:
Let’s now take a look at a few real-world examples of energy-related use cases.
Kafka Real-World Deployments in the Energy Sector
This section explores three very different deployments and architectures of Kafka-based infrastructure to build smart grids and energy production-related use cases: EON, WPX Energy, and Tesla.
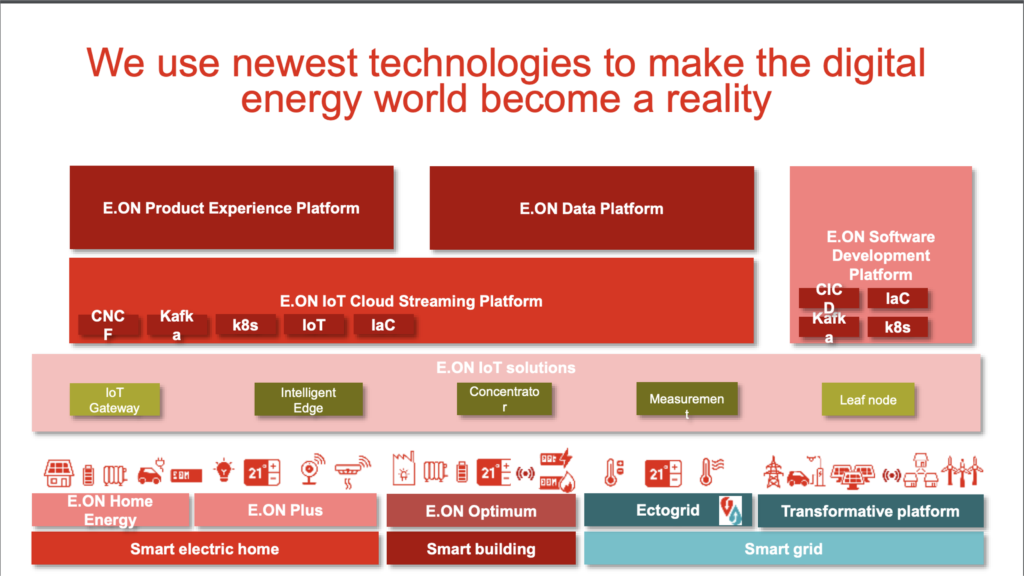
EON – Smart Grid for Energy Production and Distribution with Kafka
The EON Streaming Platform is built on the following paradigms to provide a cloud-native smart grid infrastructure:
- IoT scale capabilities of public cloud providers
- EON microservices that are independent of cloud providers
- Real-time data integration and processing powered by Apache Kafka
WPX Energy – Kafka at the Edge for Integration and Analytics
WPX Energy (now merged into Devon Energy) is a company in the oil&gas industry. The digital transformation creates many opportunities to improve processes and reduce costs in this vertical. WPX leverages Confluent Platform on Hivecell edge hardware to realize edge processing and replication to the cloud in real-time at scale.
The solution is designed for true real-time decision making and future potential closed-loop control optimization. WPX conducts edge stream processing to enable true real-time decision-making at well site. They also replicate business-relevant data streams produced by machine learning models and analytical preprocessed data at the well site to the cloud, enabling WPX to harness the full power of its real-time events.
Tesla – Kafka-based Data Platform for Trillions of Data Points per Day
Tesla is not just a car maker. Telsa is a tech company writing a lot of innovative and cutting-edge software. They provide an energy infrastructure for cars with their Telsa Superchargers, solar energy production at their Gigafactories, and much more. Processing and analyzing the data from their smart grids and the integration with the rest of the IT backend services in real-time is a key piece of their success:

Tesla has built a Kafka-based data platform infrastructure “to support millions of devices and trillions of data points per day”. Tesla showed an interesting history and evolution of their Kafka usage at a Kafka Summit in 2019:
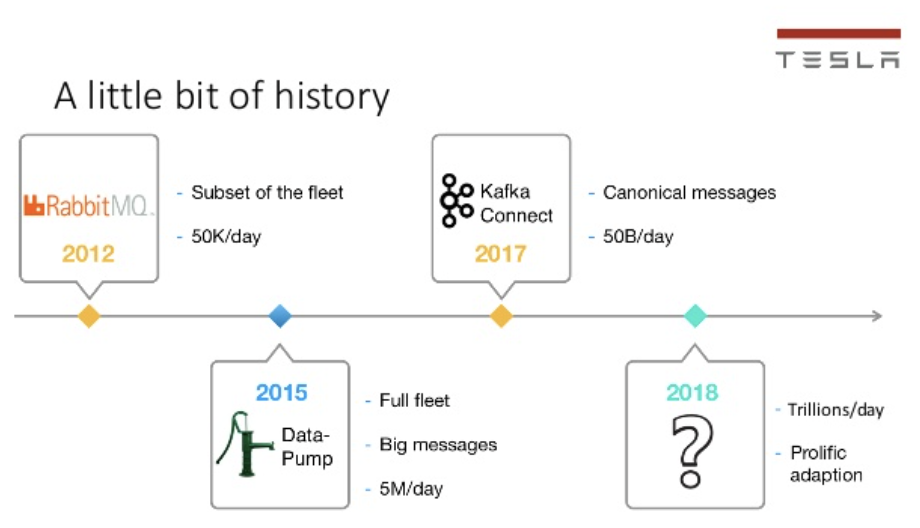
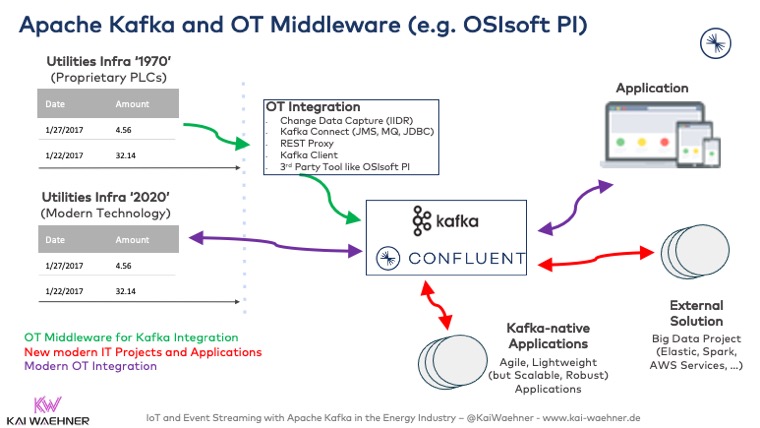
Kafka + OT Middleware (OSIsoft PI, Siemens MindSphere, et al)
A common and very relevant question is the relation between Apache Kafka and traditional OT middleware such as OSIsoft PI or Siemens MindSphere.
TL;DR: Apache Kafka and OT middleware complement each other. Kafka is NOT an IoT platform. OT middleware is not built for the integration and correlation of OT data with the rest of the enterprise IT. Kafka and OT middleware connect to each other very well. Both sides provide integration options, including REST APIs, native Kafka Connect connectors, and more. Hence, in many cases, enterprises leverage and integrate both technologies instead of choosing just one of them.
Please check out the following blogs/slides/videos to understand how Apache Kafka and OT middleware complement each other very well:
-
Apache Kafka vs. Middleware (MQ, ETL, ESB): Blog or Slides/Video.
- Domain-driven Design (DDD) with Apache Kafka for true decoupling and flexible integration infrastructures
Slides: Kafka-based Smart Grid and Energy Use Cases and Architectures
The following slide deck goes into more details about this topic:
Click on the button to load the content from www2.slideshare.net.
The Future of Kafka for the Energy Sector and Smart Grid
Kafka is relevant in many use cases for building an elastic and scalable smart grid infrastructure. Even beyond, many projects utilize Kafka heavily for customer 360, payment processing, and many other use cases. Check out the various “Use Cases and Architectures for Apache Kafka across Industries“. Energy companies can apply many of these use cases, too.
If you have read this far and actually wonder what “real-time” actually means in the context of Kafka and the OT/IT convergence, please check out the post “Kafka is NOT hard real-time“.
What are your experiences and plans for event streaming in the energy industry? Did you already build a smart grid with Apache Kafka? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.






