Apache Kafka is the de facto standard for event streaming to process data in motion. With its significant adoption growth across all industries, I get a very valid question every week: When NOT to use Apache Kafka? What limitations does the event streaming platform have? When does Kafka simply not provide the needed capabilities? How to qualify Kafka out as it is not the right tool for the job? This blog post explores the DOs and DONTs. Separate sections explain when to use Kafka, when NOT to use Kafka, and when to MAYBE use Kafka.

Market Trends – A Connected World
Let’s begin with understanding why Kafka comes up everywhere in the meantime. This clarifies the huge market demand for event streaming but also shows that there is no silver bullet solving all problems. Kafka is NOT the silver bullet for a connected world, but a crucial component!
The world gets more and more connected. Vast volumes of data are generated and need to be correlated in real-time to increase revenue, reduce costs, and reduce risks. I could pick almost any industry. Some are faster. Others are slower. But the connected world is coming everywhere. Think about manufacturing, smart cities, gaming, retail, banking, insurance, and so on. If you look at my past blogs, you can find relevant Kafka use cases for any industry.
I picked two market trends that show this insane growth of data and the creation of innovation and new cutting-edge use cases (and why Kafka’s adoption is insane across industries, too).
Connected Cars – Insane volume of telemetry data and aftersales
Here is the “Global Opportunity Analysis and Industry Forecast, 2020–2027” by Allied Market Research:

The Connected Car market includes a much wider variety of use cases and industries than most people think. A few examples: Network infrastructure and connectivity, safety, entertainment, retail, aftermarket, vehicle insurance, 3rd party data usage (e.g., smart city), and so much more.
Gaming – Billions of players and massive revenues
The gaming industry is already bigger than all other media categories combined, and this is still just the beginning of a new era – as Bitkraft depicts:
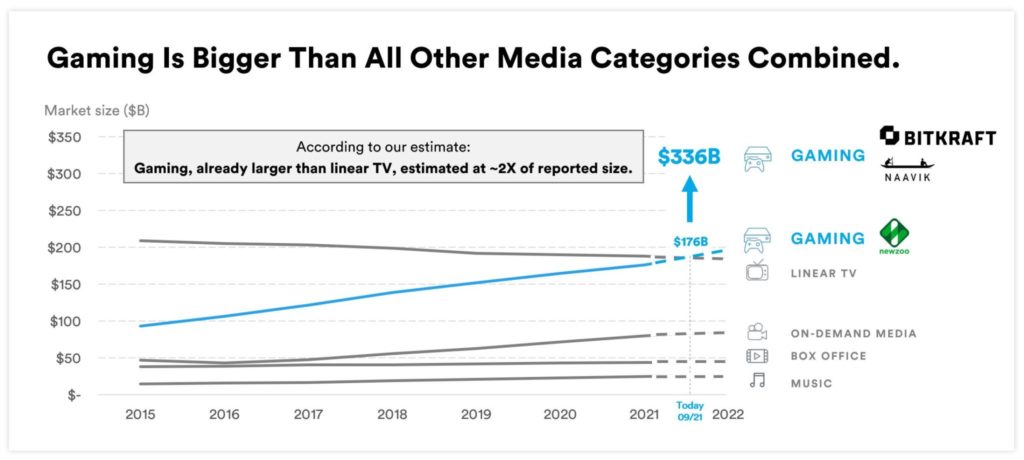
Millions of new players join the gaming community every month across the globe. Connectivity and cheap smartphones are sold in less wealthy countries. New business models like “play to earn” change how the next generation of gamers plays a game. More scalable and low latency technologies like 5G enable new use cases. Blockchain and NFT (Non-Fungible Token) are changing the monetization and collection market forever.
These market trends across industries clarify why the need for real-time data processing increases significantly quarter by quarter. Apache Kafka established itself as the de facto standard for processing analytical and transactional data streams at scale. However, it is crucial to understand when (not) to use Apache Kafka and its ecosystem in your projects.
What is Apache Kafka, and what is it NOT?
Kafka is often misunderstood. For instance, I still hear way too often that Kafka is a message queue. Part of the reason is that some vendors only pitch it for a specific problem (such as data ingestion into a data lake or data warehouse) to sell their products. So, in short:
Kafka is…
- a scalable real-time messaging platform to process millions of messages per second.
- an event streaming platform for massive volumes of big data analytics and small volumes of transactional data processing.
- a distributed storage provides true decoupling for backpressure handling, support of various communication protocols, and replayability of events with guaranteed ordering.
- a data integration framework for streaming ETL.
- a data processing framework for continuous stateless or stateful stream processing.
This combination of characteristics in a single platform makes Kafka unique (and successful).
Kafka is NOT…
- a proxy for millions of clients (like mobile apps) – but Kafka-native proxies (like REST or MQTT) exist for some use cases.
- an API Management platform – but these tools are usually complementary and used for the creation, life cycle management, or the monetization of Kafka APIs.
- a database for complex queries and batch analytics workloads – but good enough for transactional queries and relatively simple aggregations (especially with ksqlDB).
- an IoT platform with features such as device management – but direct Kafka-native integration with (some) IoT protocols such as MQTT or OPC-UA is possible and the appropriate approach for (some) use cases.
- a technology for hard real-time applications such as safety-critical or deterministic systems – but that’s true for any other IT framework, too. Embedded systems are a different software!
For these reasons, Kafka is complementary, not competitive, to these other technologies. Choose the right tool for the job and combine them!
Case studies for Apache Kafka in a connected world
This section shows a few examples of fantastic success stories where Kafka is combined with other technologies because it makes sense and solves the business problem. The focus here is case studies that need more than just Kafka for the end-to-end data flow.
No matter if you follow my blog, Kafka Summit conferences, online platforms like Medium or Dzone, or any other tech-related news. You find plenty of success stories around real-time data streaming with Apache Kafka for high volumes of analytics and transactional data from connected cars, IoT edge devices, or gaming apps on smartphones.
A few examples across industries and use cases:
- Audi: Connected car platform rolled out across regions and cloud providers
- BMW: Smart factories for the optimization of the supply chain and logistics
- SolarPower: Complete solar energy solutions and services across the globe
- Royal Caribbean: Entertainment on cruise ships with disconnected edge services and hybrid cloud aggregation
- Disney+ Hotstar: Interactive media content and gaming/betting for millions of fans on their smartphone
- The list goes on and on and on.
So what is the problem with all these great IoT success stories? Well, there is no problem. But some clarification is needed to explain when to use event streaming with the Apache Kafka ecosystem and where other complementary solutions usually complement it.
When to use Apache Kafka?
Before we discuss when NOT to use Kafka, let’s understand where to use it to get more clear how and when to complement it with other technologies if needed.
I will add real-world examples to each section. In my experience, this makes it much easier to understand the added value.
Kafka consumes and processes high volumes of IoT and mobile data in real-time
Processing massive volumes of data in real-time is one of the critical capabilities of Kafka.
Tesla is not just a car maker. Tesla is a tech company writing a lot of innovative and cutting-edge software. They provide an energy infrastructure for cars with their Tesla Superchargers, solar energy production at their Gigafactories, and much more. Processing and analyzing the data from their vehicles, smart grids, and factories and integrating with the rest of the IT backend services in real-time is a crucial piece of their success.
Tesla has built a Kafka-based data platform infrastructure “to support millions of devices and trillions of data points per day”. Tesla showed an exciting history and evolution of their Kafka usage at a Kafka Summit in 2019:
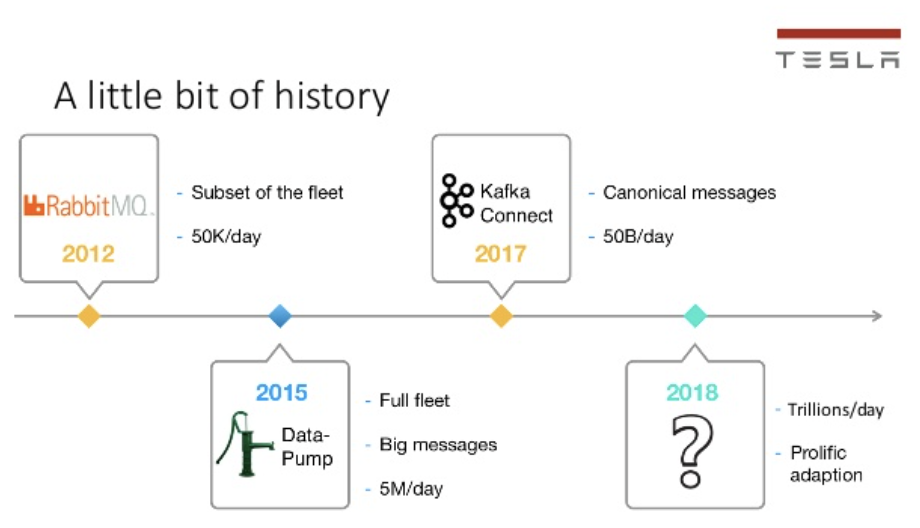
Keep in mind that Kafka is much more than just messaging. I repeat this in almost every blog post as too many people still don’t get it. Kafka is a distributed storage layer that truly decouples producers and consumers. Additionally, Kafka-native processing tools like Kafka Streams and ksqlDB enable real-time processing.
Kafka correlates IoT data with transactional data from the MES and ERP systems
Data integration in real-time at scale is relevant for analytics and the usage of transactional systems like an ERP or MES system. Kafka Connect and non-Kafka middleware complement the core of event streaming for this task.
BMW operates mission-critical Kafka workloads across the edge (i.e., in the smart factories) and public cloud. Kafka enables decoupling, transparency, and innovation. The products and expertise from Confluent add stability. The latter is vital for success in manufacturing. Each minute of downtime costs a fortune. Read my related article “Apache Kafka as Data Historian – an IIoT / Industry 4.0 Real-Time Data Lake” to understand how Kafka improves the Overall Equipment Effectiveness (OEE) in manufacturing.
BMW optimizes its supply chain management in real-time. The solution provides information about the right stock in place, both physically and in transactional systems like BMW’s ERP powered by SAP. “Just in time, just in sequence” is crucial for many critical applications. The integration between Kafka and SAP is required for almost 50% of customers I talk to in this space. Beyond the integration, many next-generation transactional ERP and MES platforms are powered by Kafka, too.
Kafka integrates with all the non-IoT IT in the enterprise at the edge and hybrid or multi-cloud
Multi-cluster and cross-data center deployments of Apache Kafka have become the norm rather than an exception. Learn about several scenarios that may require multi-cluster solutions and see real-world examples with their specific requirements and trade-offs, including disaster recovery, aggregation for analytics, cloud migration, mission-critical stretched deployments, and global Kafka.
The true decoupling between different interfaces is a unique advantage of Kafka vs. other messaging platforms such as IBM MQ, RabbitMQ, or MQTT brokers. I also explored this in detail in my article about Domain-driven Design (DDD) with Kafka.
Infrastructure modernization and hybrid cloud architectures with Apache Kafka are typical across industries.
One of my favorite examples is the success story from Unity. The company provides a real-time 3D development platform focusing on gaming and getting into other industries like manufacturing with their Augmented Reality (AR) / Virtual Reality (VR) features.
The data-driven company already had content installed 33 billion times in 2019, reaching 3 billion devices worldwide. Unity operates one of the largest monetization networks in the world. They migrated this platform from self-managed Kafka to fully-managed Confluent Cloud. The cutover was executed by the project team without downtime or data loss. Read Unity’s post on the Confluent Blog: “How Unity uses Confluent for real-time event streaming at scale “.
Kafka is the scalable real-time backend for mobility services and gaming/betting platforms
Many gaming and mobility services leverage event streaming as the backbone of their infrastructure. Use cases include the processing of telemetry data, location-based services, payments, fraud detection, user/player retention, loyalty platform, and so much more. Almost all innovative applications in this sector require real-time data streaming at scale.
A few examples:
- Mobility services: Uber, Lyft, FREE NOW, Grab, Otonomo, Here Technologies, …
- Gaming services: Disney+ Hotstar, Sony Playstation, Tencent, Big Fish Games, …
- Betting services: William Hill, Sky Betting, …
Just look at the job portals of any mobility or gaming service. Not everybody is talking about their Kafka usage in public. But almost everyone is looking for Kafka experts to develop and operate their platform.
These use cases are just as critical as a payment process in a core banking platform. Regulatory compliance and zero data loss are crucial. Multi-Region Clusters (i.e., a Kafka cluster stretched across regions like US East, Central, and West) enable high availability with zero downtime and no data loss even in the case of a disaster.
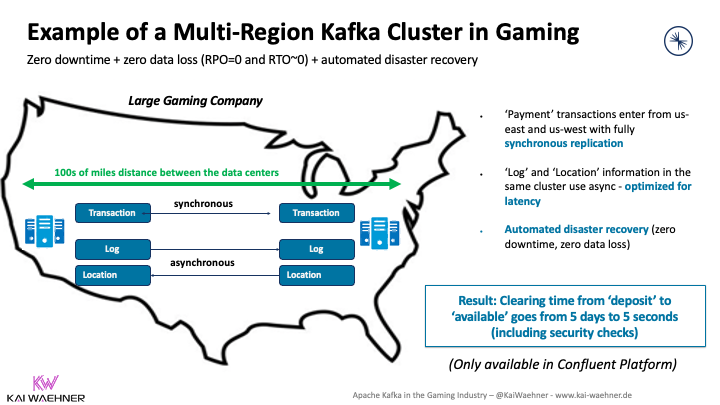
Vehicles, machines, or IoT devices embed a single Kafka broker
The edge is here to stay and grow. Some use cases require the deployment of a Kafka cluster or single broker outside a data center. Reasons for operating a Kafka infrastructure at the edge include low latency, cost efficiency, cybersecurity, or no internet connectivity.
Examples for Kafka at the edge:
- Disconnected edge in logistics to store logs, sensor data, and images while offline (e.g., a truck on the street or a drone flying around a ship) until a good internet connection is available in the distribution center
- Vehicle-to-Everything (V2X) communication in a local small data center like AWS Outposts (via a gateway like MQTT if large area, a considerable number of vehicles, or lousy network), or via direct Kafka client connection for a few hundreds of machines, e.g., in a smart factory )
- Offline mobility services like integrating a car infrastructure with gaming, maps, or a recommendation engine with locally processed partner services (e.g., the next Mc Donalds comes in 10 miles, here is a coupon).
The cruise line Royal Caribbean is a great success story for this scenario. It operates the four largest passenger ships in the world. As of January 2021, the line operates twenty-four ships and has six additional ships on order.
Royal Caribbean implemented one of Kafka’s most famous use cases at the edge. Each cruise ship has a Kafka cluster running locally for use cases such as payment processing, loyalty information, customer recommendations, etc.:
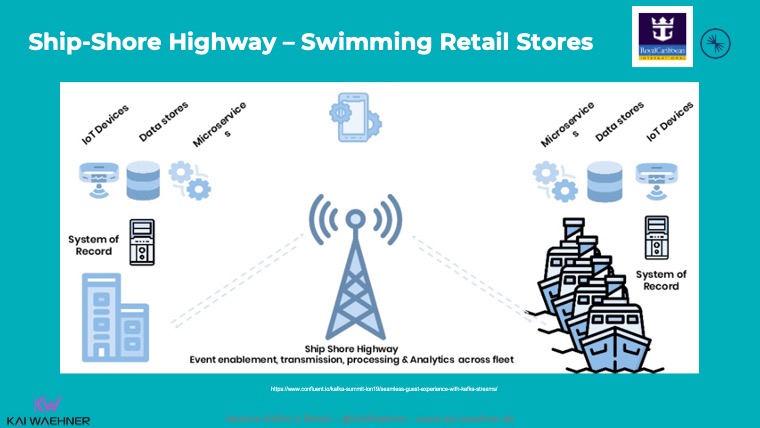
I covered this example and other Kafka edge deployments in various blogs. I talked about use cases for Kafka at the edge, showed architectures for Kafka at the edge, and explored low latency 5G deployments powered by Kafka.
When NOT to use Apache Kafka?
Finally, we are coming to the section everybody was looking for, right? However, it is crucial first to understand when to use Kafka. Now, it is easy to explain when NOT to use Kafka.
For this section, let’s assume that we talk about production scenarios, not some ugly (?) workarounds to connect Kafka to something for a proof of concept directly; there is always a quick and dirty option to test something – and that’s fine for that goal. But things change when you need to scale and roll out your infrastructure globally, be compliant to law, and guarantee no data loss for transactional workloads.
With this in mind, it is relatively easy to qualify out Kafka as an option for some use cases and problems:
Kafka is NOT hard real-time
The definition of the term “real-time” is difficult. It is often a marketing term. Real-time programs must guarantee a response within specified time constraints.
Kafka – and all other frameworks, products, and cloud services used in this context – is only soft real-time and built for the IT world. Many OT and IoT applications require hard real-time with zero latency spikes.
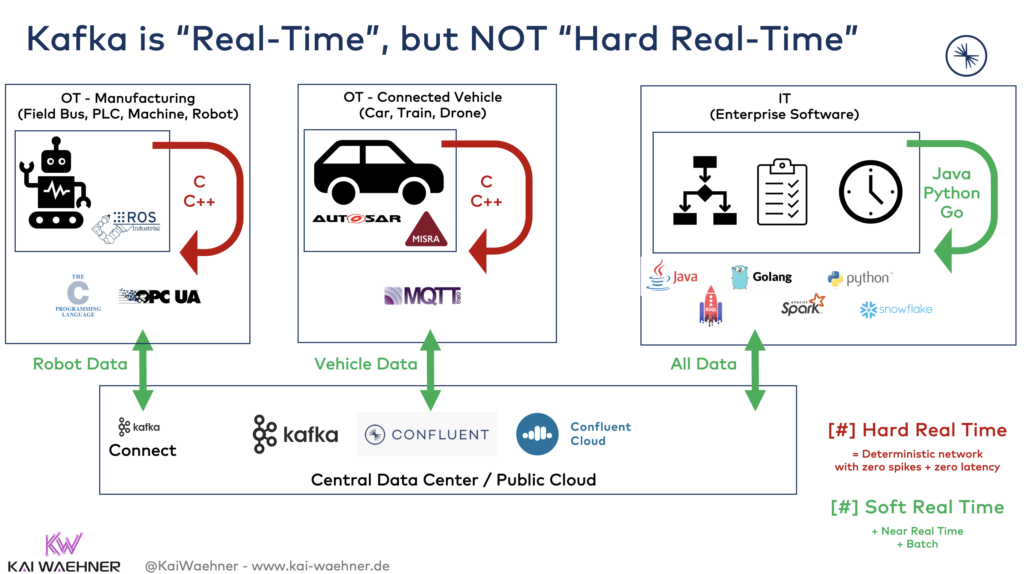
Soft real-time is used for applications such as
- Point-to-point messaging between IT applications
- Data ingestion from various data sources into one or more data sinks
- Data processing and data correlation (often called event streaming or event stream processing)
If your application requires sub-millisecond latency, Kafka is not the right technology. For instance, high-frequency trading is usually implemented with purpose-built proprietary commercial solutions.
Kafka is NOT deterministic for embedded and safety-critical systems
This one is pretty straightforward and related to the above section. Kafka is not a deterministic system. Safety-critical applications cannot use it for a car engine control system, a medical system such as a heart pacemaker, or an industrial process controller.
A few examples where Kafka CANNOT be used for:
- Safety-critical data processing in the car or vehicle. That’s Autosar / MINRA C / Assembler and similar technologies.
- CAN Bus communication between ECUs.
- Robotics. That’s C / C++ or similar low-level languages combined with frameworks such as Industrial ROS (Robot Operating System).
- Safety-critical machine learning / deep learning (e.g., for autonomous driving)
- Vehicle-to-Vehicle (V2V) communication. That’s 5G sidelink without an intermediary like Kafka.
My post “Apache Kafka is NOT Hard Real-Time BUT Used Everywhere in Automotive and Industrial IoT” explores this discussion in more detail.
TL;DR: Safety-related data processing must be implemented with dedicated low-level programming languages and solutions. That’s not Kafka! The same is true for any other IT software, too. Hence, don’t replace Kafka with IBM MQ, Flink, Spark, Snowflake, or any other similar IT software.
Kafka is NOT built for bad networks
Kafka requires good stable network connectivity between the Kafka clients and the Kafka brokers. Hence, if the network is unstable and clients need to reconnect to the brokers all the time, then operations are challenging, and SLAs are hard to reach.
There are some exceptions, but the basic rule of thumb is that other technologies are built specifically to solve the problem of bad networks. MQTT is the most prominent example. Hence, Kafka and MQTT are friends, not enemies. The combination is super powerful and used a lot across industries. For that reason, I wrote a whole blog series about Kafka and MQTT.
Kafka does NOT provide connectivity to tens of thousands of client applications
Another specific point to qualify Kafka out as an integration solution is that Kafka cannot connect to tens of thousands of clients. If you need to build a connected car infrastructure or gaming platform for mobile players, the clients (i.e., cars or smartphones) will not directly connect to Kafka.
A dedicated proxy such as an HTTP gateway or MQTT broker is the right intermediary between thousands of clients and Kafka for real-time backend processing and the integration with further data sinks such as a data lake, data warehouse, or custom real-time applications.
Where are the limits of Kafka client connections? As so often, this is hard to say. I have seen customers connect directly from their shop floor in the plant via .NET and Java Kafka clients via a direct connection to the cloud where the Kafka cluster is running. Direct hybrid connections usually work well if the number of machines, PLCs, IoT gateways, and IoT devices is in the hundreds. For higher numbers of client applications, you need to evaluate if you a) need a proxy in the middle or b) deploy “edge computing” with or without Kafka at the edge for lower latency and cost-efficient workloads.
When to MAYBE use Apache Kafka?
The last section covered scenarios where it is relatively easy to quality Kafka out as it simply cannot provide the required capabilities. I want to explore a few less apparent topics, and it depends on several things if Kafka is a good choice or not.
Kafka does (usually) NOT replace another database
Apache Kafka is a database. It provides ACID guarantees and is used in hundreds of companies for mission-critical deployments. However, most times, Kafka is not competitive with other databases. Kafka is an event streaming platform for messaging, storage, processing, and integration at scale in real-time with zero downtime or data loss.
Kafka is often used as a central streaming integration layer with these characteristics. Other databases can build materialized views for their specific use cases like real-time time-series analytics, near real-time ingestion into a text search infrastructure, or long-term storage in a data lake.
In summary, when you get asked if Kafka can replace a database, then there are several answers to consider:
- Kafka can store data forever in a durable and high available manner providing ACID guarantees
- Further options to query historical data are available in Kafka
- Kafka-native add-ons like ksqlDB or Tiered Storage make Kafka more potent than ever before for data processing and event-based long-term storage
- Stateful applications can be built leveraging Kafka clients (microservices, business applications) with no other external database
- Not a replacement for existing databases, data warehouses, or data lakes like MySQL, MongoDB, Elasticsearch, Hadoop, Snowflake, Google BigQuery, etc.
- Other databases and Kafka complement each other; the right solution has to be selected for a problem; often, purpose-built materialized views are created and updated in real-time from the central event-based infrastructure
- Different options are available for bi-directional pull and push-based integration between Kafka and databases to complement each other
My blog post “Can Apache Kafka replace a database, data warehouse, or data lake?” discusses the usage of Kafka as a database in much more detail.
Kafka does (usually) NOT process large messages
Kafka was not built for large messages. Period.
Nevertheless, more and more projects send and process 1Mb, 10Mb, and even much bigger files and other large payloads via Kafka. One reason is that Kafka was designed for large volume/throughput – which is required for large messages. A very common example that comes up regularly is the ingestion and processing of large files from legacy systems with Kafka before ingesting the processed data into a Data Warehouse.
However, not all large messages should be processed with Kafka. Often you should use the right storage system and just leverage Kafka for the orchestration. Reference-based messaging (i.e. storing the file in another storage system and sending the link and metadata) is often the better design pattern:
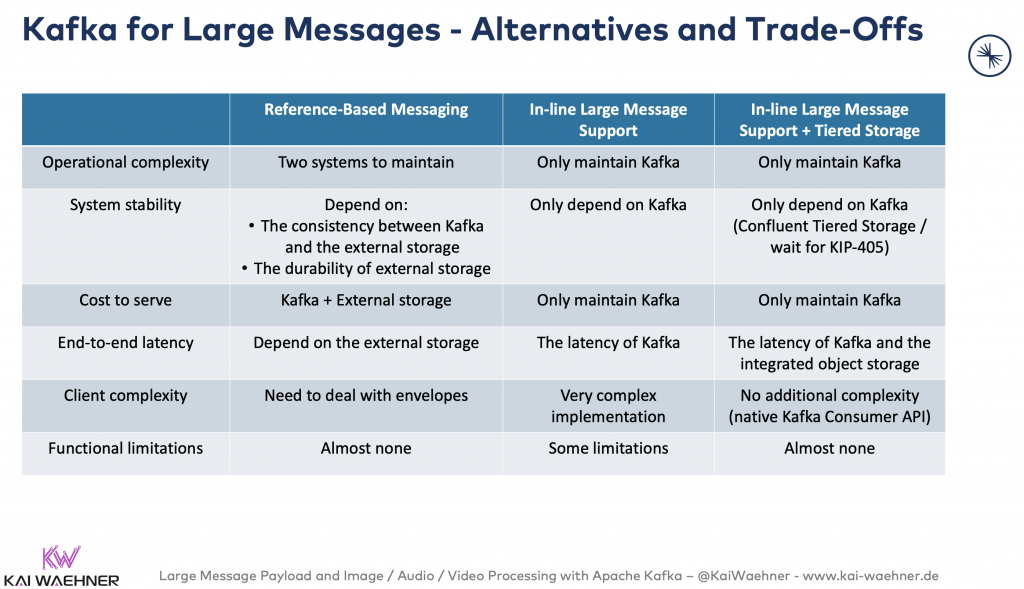
Know the different design patterns and choose the right technology for your problem.
For more details and use cases about handling large files with Kafka, check out this blog post: “Handling Large Messages with Apache Kafka (CSV, XML, Image, Video, Audio, Files)“.
Kafka is (usually) NOT the IoT gateway for the last-mile integration of industrial protocols…
The last-mile integration with IoT interfaces and mobile apps is a tricky space. As discussed above, Kafka cannot connect to thousands of Kafka clients. However, many IoT and mobile applications only require tens or hundreds of connections. In that case, a Kafka-native connection is straightforward using one of the various Kafka clients available for almost any programming language on the planet.
Suppose a connection on TCP level with a Kafka client makes little sense or is not possible. In that case, a very prevalent workaround is the REST Proxy as the intermediary between the clients and the Kafka cluster. The clients communicate via synchronous HTTP(S) with the streaming platform.
Use cases for HTTP and REST APIs with Apache Kafka include the control plane (= management), the data plane (= produce and consume messages), and automation, respectively DevOps tasks.
Unfortunately, many IoT projects require much more complex integrations. I am not just talking about a relatively straightforward integration via an MQTT or OPC-UA connector. Challenges in Industrial IoT projects include:
- The automation industry does often not use open standards but is slow, insecure, not scalable, and proprietary.
- Product Lifecycles are very long (tens of years), with no simple changes or upgrades.
- IIoT usually uses incompatible protocols, typically proprietary and built for one specific vendor.
- Proprietary and expensive monoliths that are not scalable and not extendible.
Therefore, many IoT projects complement Kafka with a purpose-built IoT platform. Most IoT products and cloud services are proprietary but provide open interfaces and architectures. The open-source space is small in this industry. A great alternative (for some use cases) is Apache PLC4X. The framework integrates with many proprietary legacy protocols, such as Siemens S7, Modbus, Allen Bradley, Beckhoff ADS, etc. PLC4X also provides a Kafka Connect connector for native and scalable Kafka integration.
A modern data historian is open and flexible. The foundation of many strategic IoT modernization projects across the shop floor and hybrid cloud is powered by event streaming:
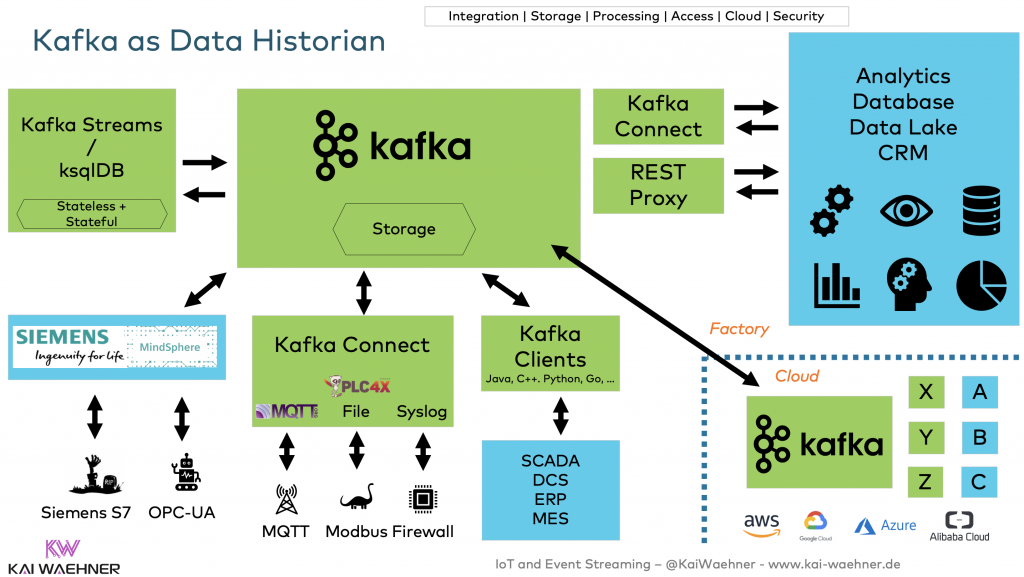
Kafka is NOT a blockchain (but relevant for web3, crypto trading, NFT, off-chain, sidechain, oracles)
Kafka is a distributed commit log. The concepts and foundations are very similar to a blockchain. I explored this in more detail in my post “Apache Kafka and Blockchain – Comparison and a Kafka-native Implementation“.
A blockchain should be used ONLY if different untrusted parties need to collaborate. For most enterprise projects, a blockchain is unnecessary added complexity. A distributed commit log (= Kafka) or a tamper-proof distributed ledger (= enhanced Kafka) is sufficient.
Having said this, more interestingly, I see more and more companies using Kafka within their crypto trading platforms, market exchanges, and NFT token trading marketplaces.
To be clear: Kafka is NOT the blockchain on these platforms. The blockchain is a cryptocurrency like Bitcoin or a platform providing smart contracts like Ethereum where people build new distributed applications (dApps) like NFTs for the gaming or art industry. Kafka is the streaming platform to connect these blockchains with other Oracles (= the non-blockchain apps) like the CRM, data lake, data warehouse, and so on: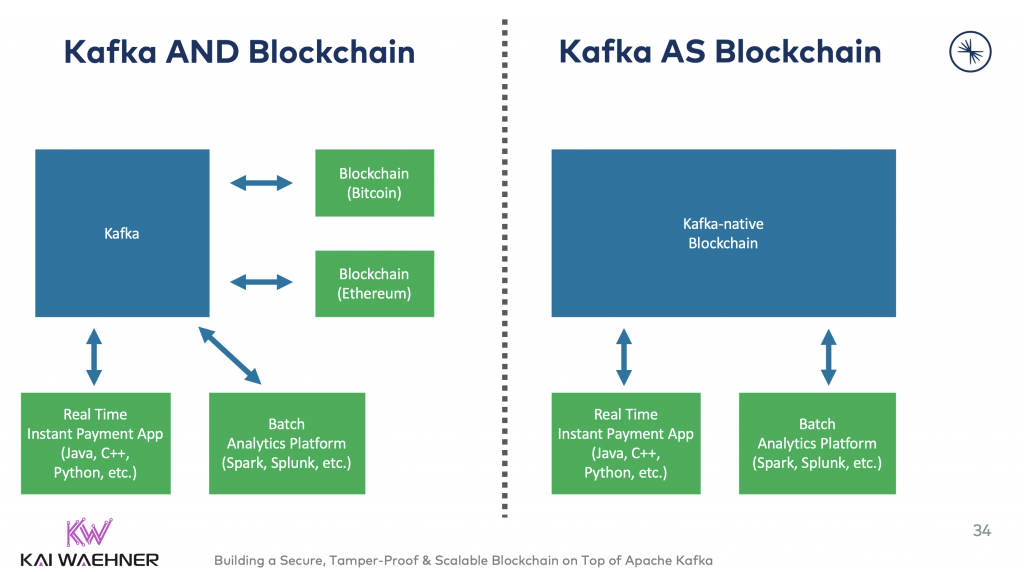
TokenAnalyst is an excellent example that leverages Kafka to integrate blockchain data from Bitcoin and Ethereum with their analytics tools. Kafka Streams provides a stateful streaming application to prevent using invalid blocks in downstream aggregate calculations. For example, TokenAnalyst developed a block confirmer component that resolves reorganization scenarios by temporarily keeping blocks, and only propagates them when a threshold of a number of confirmations (children to that block are mined) is reached.
In some advanced use cases, Kafka is used to implementing a sidechain or off-chain platform as the original blockchain does not scale well enough (blockchain is known as on-chain data). Not just Bitcoin has the problem of only processing single-digit (!) transactions per second. Most modern blockchain solutions cannot scale even close to the workloads Kafka processes in real-time.
From DAOs to blue chip companies, measuring the health of blockchain infrastructure and IOT components is still necessary even in a distributed network to avoid downtime, secure the infrastructure, and make the blockchain data accessible. Kafka provides an agentless and scalable way to present that data to the parties involved and make sure that the relevant data is exposed to the right teams before a node is lost. This is relevant for cutting-edge Web3 IoT projects like Helium, or simpler closed distributed ledgers (DLT) like R3 Corda.
My recent post about live commerce powered by event streaming and Kafka transforming the retail metaverse shows how the retail and gaming industry connects virtual and physical things. The retail business process and customer communication happen in real-time; no matter if you want to sell clothes, a smartphone, or a blockchain-based NFT token for your collectible or video game.
TL;DR: Kafka is NOT…
… a replacement for your favorite database or data warehouse.
… hard real-time for safety-critical embedded workloads.
… a proxy for thousands of clients in bad networks.
… an API Management solution.
… an IoT gateway.
… a blockchain.
It is easy to qualify Kafka out for some use cases and requirements.
However, analytical and transactional workloads across all industries use Kafka. It is the de-facto standard for event streaming everywhere. Hence, Kafka is often combined with other technologies and platforms.
Where do you (not) use Apache Kafka? What other technologies do you combine Kafka with? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.