Not all workloads should go to the cloud! Low latency, cybersecurity, and cost-efficiency require a suitable combination of edge computing and cloud integration. This blog post explores architectures and design patterns for software and hardware considerations to deploy hybrid data streaming with Apache Kafka anywhere. A live demo shows data synchronization from the edge to the public cloud across continents with Kafka on Hivecell edge hardware and serverless Confluent Cloud.

Not every workload should go into the cloud
Almost every company has a cloud-first strategy in the meantime. Nevertheless, not all workloads should be deployed in the public cloud. A few reasons why IT applications still run at the edge or in a local data center:
- Cost-efficiency: The more data produced at the edge, the more costly it is to transfer everything to the cloud. This significant data transfer is often non-sense for high volumes of raw sensor and telemetry data.
- Low latency: Some use cases require data processing and correlation in real-time in milliseconds. Communication with remote locations increases the response time significantly.
- Bad, unstable internet connection: Some environments do not provide good connectivity to the cloud or are entirely disconnected all the time or for some time of the day.
- Cybersecurity with air-gapped environments: The disconnected Edge is common in safety-critical environments. Controlled data replication is only possible via unidirectional hardware gateways or manual human copy tasks within the site.
Here is a great recent example of why not all workloads should go to the cloud: AWS outage that created enormous issues for visitors to Disney World as the mobile app features are running online in the cloud. Business continuity is not possible if the connection to the cloud is offline:

The Edge is…
To be clear: The term ‘edge’ needs to be defined at the beginning of every conversation. I define the edge as having the following characteristics and needs:
- Edge is NOT a data center
- Offline business continuity
- Often 100+ locations
- Low-footprint and low-touch
- Hybrid integration
Hybrid cloud for Kafka is the norm; not an exception
Multi-cluster and cross-data center deployments of Apache Kafka have become the norm rather than an exception. Several scenarios require multi-cluster solutions. Real-world examples have different requirements and trade-offs, including disaster recovery, aggregation for analytics, cloud migration, mission-critical stretched deployments, and global Kafka.
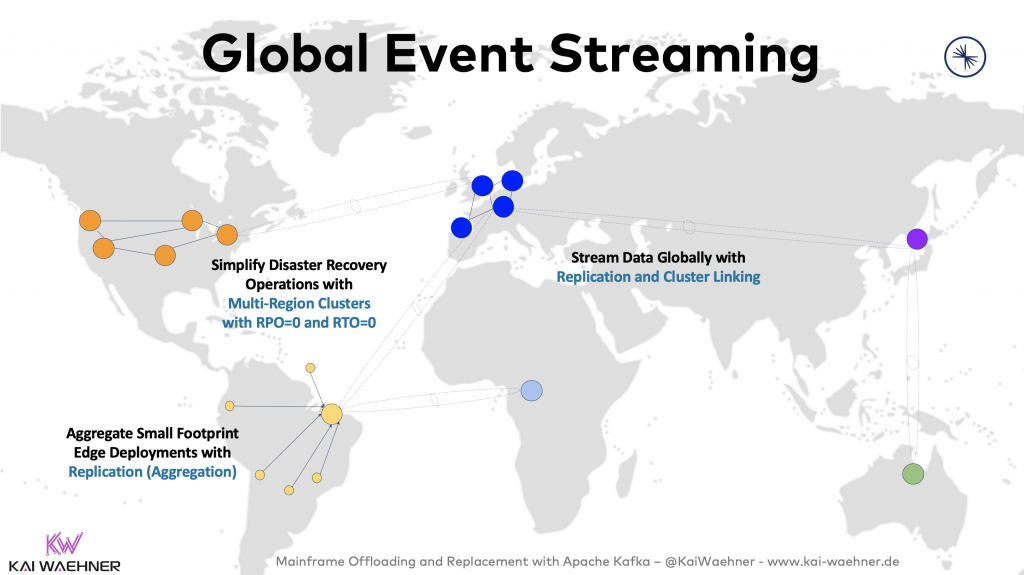
I posted about this in the past. Check out “architecture patterns for distributed, hybrid, edge and global Apache Kafka deployments“.
Apache Kafka at the Edge
From a Kafka perspective, the edge can mean two things:
- Kafka clients at the edge connecting directly to the Kafka cluster in a remote data center or public cloud, connecting via a native client (Java, C++, Python, etc.) or a proxy (MQTT Proxy, HTTP / REST Proxy)
- Kafka clients AND the Kafka broker(s) deployed at the edge, not just the client applications
Both alternatives are acceptable and have their trade-offs. This post is about the whole Kafka infrastructure at the edge (potentially replicating to another remote Kafka cluster via MirrorMaker, Confluent Replicator, or Cluster Linking).
Check out my Infrastructure Checklist for Apache Kafka at the edge for more details.
I also covered various Apache Kafka use cases for the edge and hybrid cloud across industries like manufacturing, transportation, energy, mining, retail, entertainment, etc.
Hardware for edge computing and analytics
Edge hardware has some specific requirements to be successful in a project:
- No special equipment for power, air conditioning, or networking
- No technicians are required on-site to install, configure, or maintain the hardware and software
- Start with the smallest footprint possible to show ROI
- Easily add more compute power as workload expands
- Deploy and operate simple or distributed software for containers, middleware, event streaming, business applications, and machine learning
- Monitor, manage and upgrade centrally via fleet management and automation, even when behind a firewall
Devon Energy: Edge and Hybrid Cloud with Kafka, Confluent, and Hivecell
Devon Energy (formerly named WPX Energy) is a company in the oil & gas industry. The digital transformation creates many opportunities to improve processes and reduce costs in this vertical. WPX leverages Confluent Platform on Hivecell edge hardware to realize edge processing and replication to the cloud in real-time at scale.
The solution is designed for real-time decision-making and future closed-loop control optimization. Devon Energy conducts edge stream processing to enable real-time decision-making at the well sites. They also replicate business-relevant data streams produced by machine learning models and analytical preprocessed data at the well site to the cloud, enabling Devon Energy to harness the full power of its real-time events:
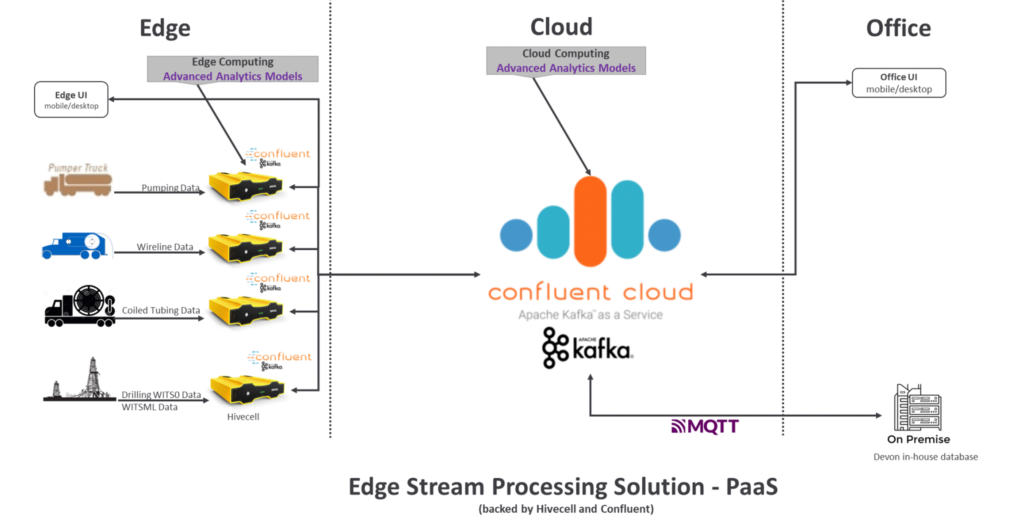
A few interesting notes about this hybrid Edge to cloud deployment:
- Improved drilling and well completion operations
- Edge stream processing / analytics + closed-loop control ready
- Vendor agnostic (pumping, wireline, coil, offset wells, drilling operations, producing wells)
- Replication to the cloud in real-time at scale
- Cloud agnostic (AWS, GCP, Azure)
Live Demo – How to deploy a Kafka Cluster in production on your desk or anywhere
Confluent and Hivecell delivered the promise of bringing a piece of Confluent Cloud right there to your desk and delivering managed Kafka on a cloud-native Kubernetes cluster at the edge. For the first, Kafka deployments run time at scale at the edge, enabling local Kafka clusters at oil drilling sites, on ships, in factories, or in quick-service restaurants.
In this webinar, we showed how it works during a live demo – where we deploy an edge Confluent cluster, stream edge data, and synchronize it with Confluent Cloud across regions and even continents:
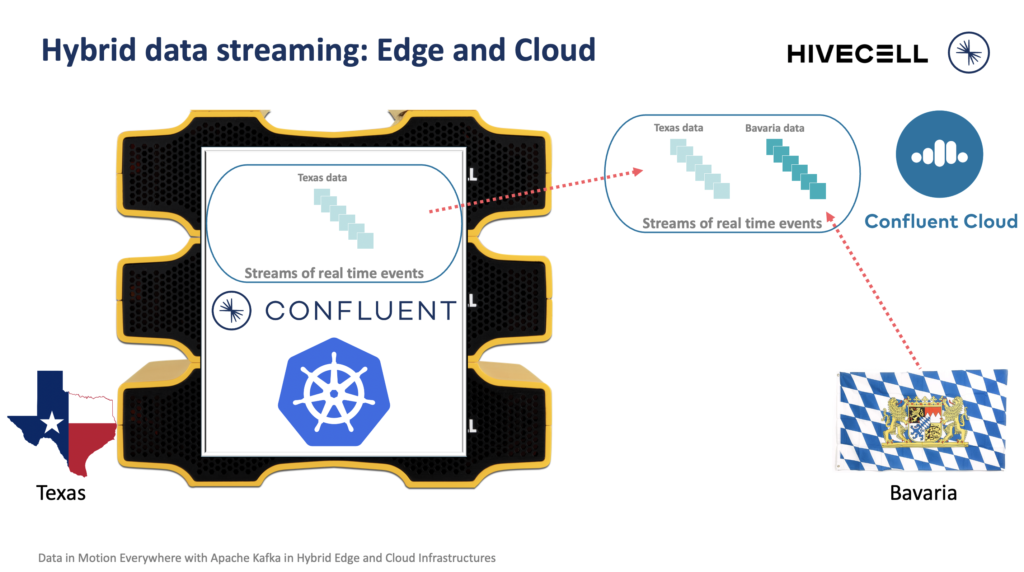
Dominik and I had our Hivecell cluster in our home in Texas, USA, respectively, Bavaria, Germany. We synchronized events across continents to a central Confluent Cloud cluster and simulated errors and cloud-native self-healing by “killing” one of my Hivecell nodes in Germany.
The webinar covered the following topics:
– Edge computing as the next significant paradigm shift in IT
– Apache Kafka and Confluent use cases at the Edge in IoT environments
– An easy way of setting up Kafka clusters where ever you need them, including fleet management and error handling
– Hands-on examples of Kafka cluster deployment and data synchronization
Slides and on-demand video recording
Here are the slides:
Click on the button to load the content from www.slideshare.net.
And the on-demand video recording:

Real-time data streaming everywhere required hybrid edge to cloud data streaming!
A cloud-first strategy makes sense. Elastic scaling, agile development, and cost-efficient infrastructure allow innovation. However, not all workloads should go to the cloud for latency, cost, or security reasons.
Apache Kafka can be deployed everywhere. Essential for most projects is the successful deployment and management at the edge and the uni- or bidirectional synchronization in real-time between the edge and the cloud. This post showed how Confluent Cloud, Kafka at the Edge on Hivecell edge hardware, and Cluster Linking enable hybrid streaming data exchanges.
How do you use Apache Kafka? Do you deploy in the public cloud, in your data center, or at the edge outside a data center? How do you process and replicate the data streams? What other technologies do you combine with Kafka? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.