Digital transformation requires agility and fast time to market as critical factors for success in any enterprise. The decentralization with a data mesh separates applications and business units into independent domains. Data sharing in real-time with data streaming helps to provide information in the proper context to the correct application at the right time. This blog post explores a case study from the financial services sector where a data mesh was built across countries for loosely coupled data sharing but standardized enterprise-wide data governance.
Data mesh and the need for real-time data streaming
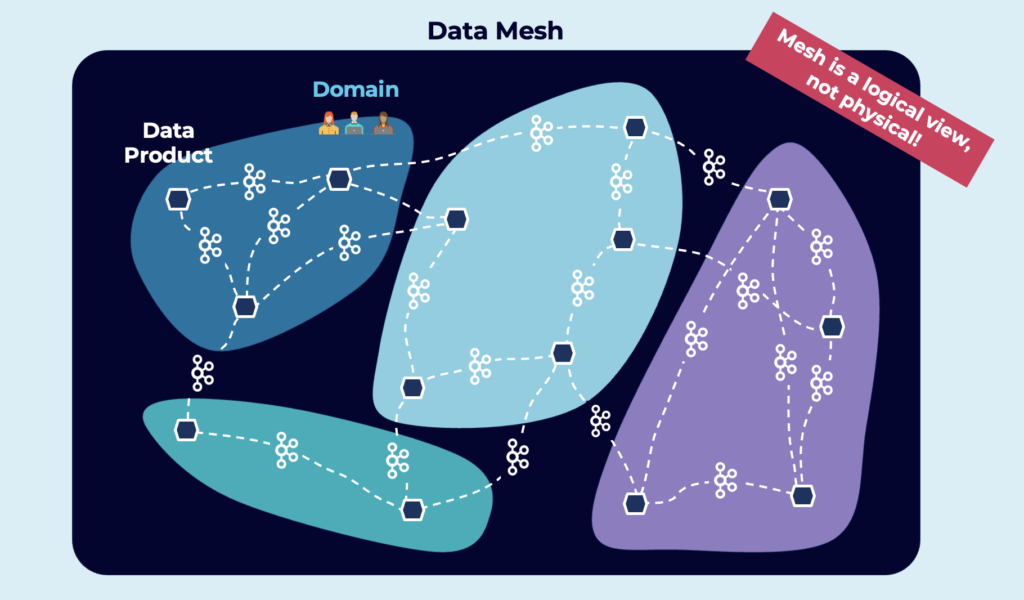
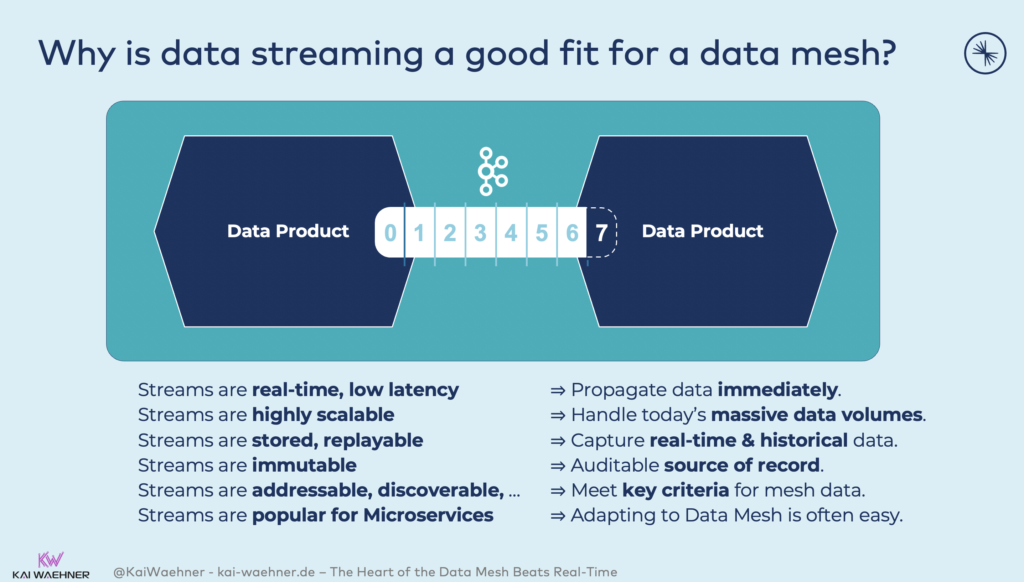
If there were a buzzword of the hour, it would undoubtedly be “data mesh“! This new architectural paradigm unlocks analytic and transactional data at scale and enables rapid access to an ever-growing number of distributed domain datasets for various usage scenarios. The data mesh addresses the most common weaknesses of the traditional centralized data lake or data platform architecture. And the heart of a decentralized data mesh infrastructure must be real-time, reliable, and scalable:
The digital transformation in financial services
The new enterprise reality in the financial services sector: Innovate or be disrupted!
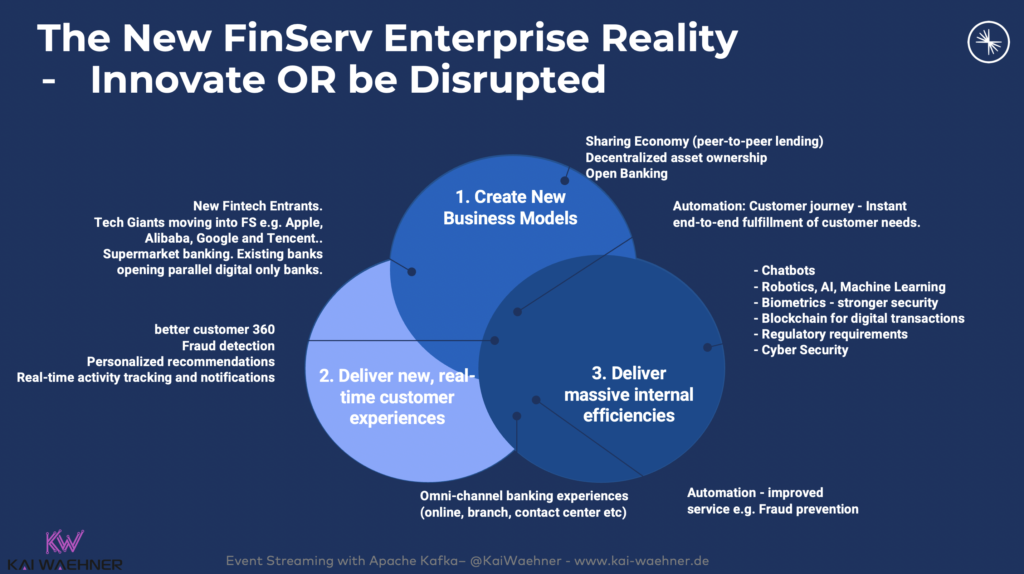
A few initiatives I have seen in banks around the world with real-time data leveraging data streaming:
- Legacy modernization, e.g., mainframe offloading and replacement with Apache Kafka
- Middleware modernization with scalable, open infrastructures replacing ETL, ESB, and iPaaS platforms
- Hybrid cloud data replication for disaster recovery, migration, and other scenarios
- Transactions and analytics in real-time at any scale
- Fraud detection in real-time with Kafka and Flink to prevent fraud before it happens
- Cloud-native core banking to enable modern business processes
- Digital payment innovation with Apache Kafka as the data hub for Cryptocurrency, DeFi, NFT, and Metaverse (beyond the buzz)
Let’s look at a practical example from the real world.
Raiffeisen Bank International – A bank transformation across 12 countries
Raiffeisen Bank International (RBI) is scaling an event-driven architecture across the group as part of a bank-wide transformation program. This includes the creation of a reference architecture and the re-use of technology and concepts across 12 countries.
The universal bank is headquartered in Vienna, Austria. It has decades of experience (and related legacy infrastructure) in retail, corporate and markets, and investment banking.
Let’s explore the journey of Raiffeisen Bank’s digital transformation. If you want to listen to the story told by themselves, watch the free on-demand webinar.
Building a data mesh without knowing it…
Raiffeisen Bank, operating across 12 countries, has all the apparent challenges and requirements for data sharing across applications, platforms, and governments.
Raiffeisen Bank built a decentralized data mesh enterprise architecture with real-time data sharing as the fundamental key to its digital transformation. They did not even know about it because the buzzword did not exist when they started making it… 🙂 But there are good reasons for using data streaming as the data hub:
The enterprise architecture of RBI’s data mesh with data streaming
The reference architecture includes data streaming as the heart of the infrastructure. It is real-time, scalable, and decoupled independent domains and applications. Open Banking APIs exist for request-response communication:
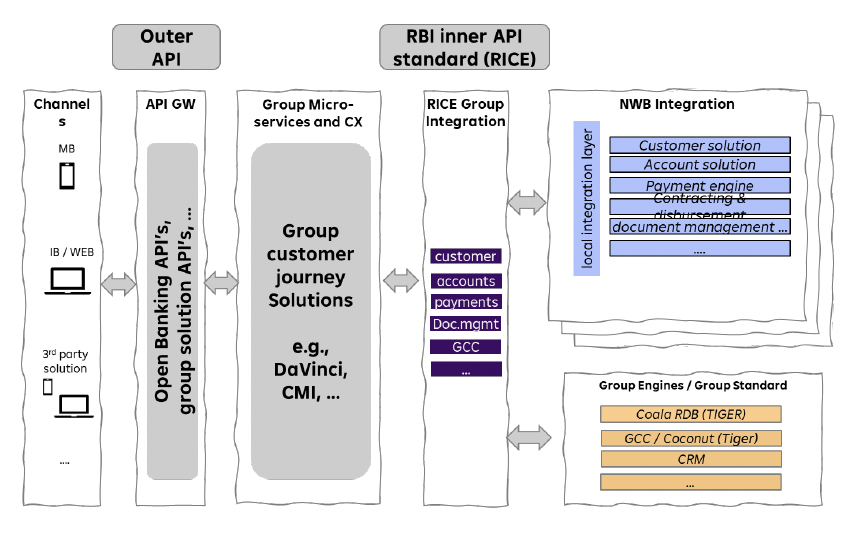
The three core principles of the enterprise architecture ensure an agile, scalable, and future-ready infrastructure across the countries:
- API: Internal APIs standardized based on domain-driven design
- Group integration: Live, connected with 11 countries, 320 APIs available, constantly increasing
- EDA: Event-driven reference architecture created and roll-out ongoing, group Layer live with the first use cases
The combination of data streaming with Apache Kafka and request-response with REST / HTTP is prevalent in enterprise architectures. Having said that, more and more use cases directly leverage a stream data exchange for data sharing across business units or organizations.
Decoupling with decentralized data streaming as the integration layer
The whole IT platform and technology stack is built for re-use in the group:
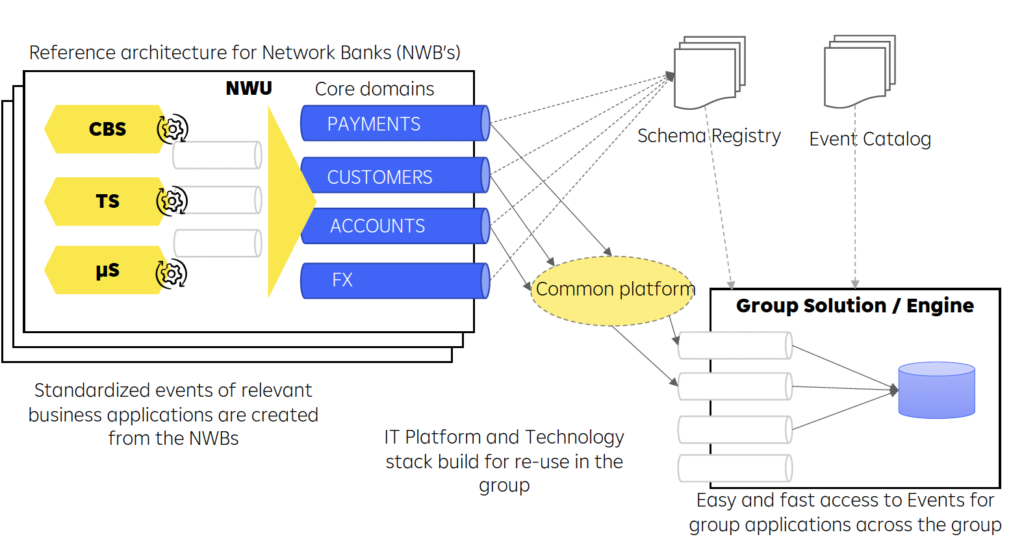
Raiffeisen Bank’s reference architecture has all the characteristics that define a data mesh:
- Loose coupling between applications, databases, and business units with domain-driven design
- Independent microservices and data products (like different core banking platforms or individual analytics in the countries)
- Data sharing in real-time via a decentralized data streaming platform (fully-managed in the cloud where possible, but freedom of choice for each country
- Enterprise-wide API contacts (= schemas in the Kafka world)
Data governance in regulated banking across the data mesh
Financial service is a regulated market around the world. PCI, GDPR, and other compliance requirements are mandatory, whether you build monoliths or a decentralized data mesh.
Raiffeisenbank international built its data mesh with data governance, legal compliance, and data privacy in mind from the beginning:
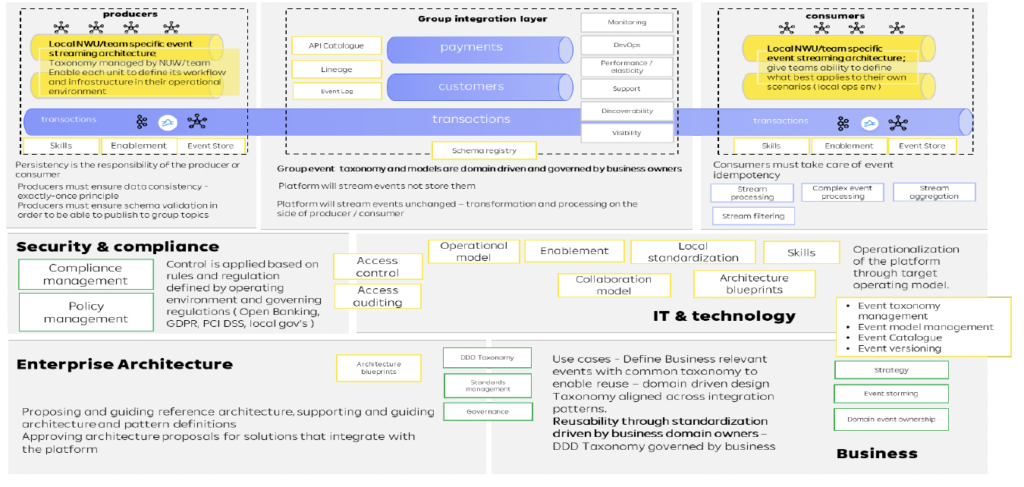
Here are the fundamental principles of Raiffeisen Bank’s data governance strategy:
- Central integration layer for data sharing across the independent groups in real-time for transactional and analytical workloads
- Cloud-first strategy (when it makes sense) with fully-managed Confluent Cloud for data streaming
- Group-wide standardized event taxonomy and API contracts with Schema Registry
- Group-wide governance with event product owners across the group
- Platform as a service for self-service for internal customers within the different groups
Combining these paradigms and rules enables independent data processing and innovation while still being compliant and enabling data sharing across different groups.
The heart of a data mesh beats in real-time
Independent applications, domains, and organizations built separate data products in a data mesh. Real-time data sharing across these units with standardized and loosely coupled events is a critical success factor. Each downstream consumer gets the data as needed: Real-time, near real-time, batch, or request-response.
The case study from Raiffeisen Bank International showed how to build a powerful and flexible data mesh leveraging cloud-native data streaming powered by Apache Kafka. While this example comes from financial services, the principles and architectures apply to any vertical. The business objects and interfaces look different. But the significant challenges are very similar across industries.
How do you build a data mesh? Do you use batch technology like ETL tools and data lakes or rely on real-time data streaming for data sharing and integration? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.