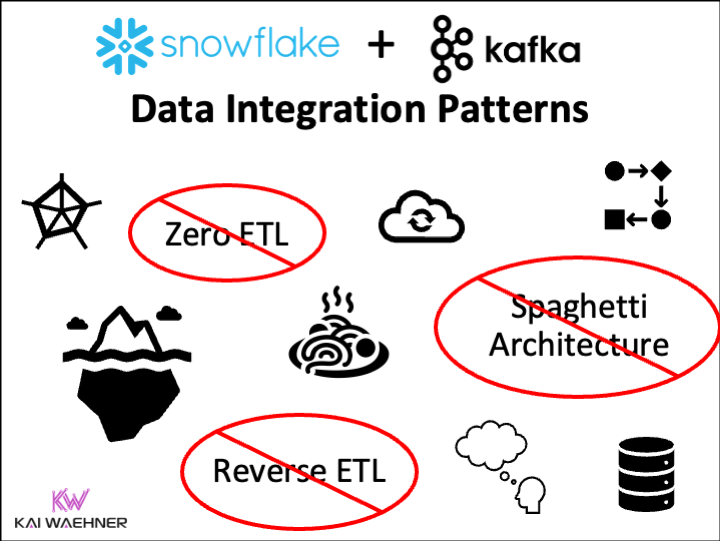
Snowflake is a leading cloud-native data warehouse. Integration patterns include batch data integration, Zero ETL and near real-time data ingestion with Apache Kafka. This blog post explores the different approaches and discovers its trade-offs. Following industry recommendations, it is suggested to avoid anti-patterns like Reverse ETL and instead use data streaming to enhance the flexibility, scalability, and maintainability of enterprise architecture.
Blog Series: Snowflake and Apache Kafka
Snowflake is a leading cloud-native data warehouse. Its usability and scalability made it a prevalent data platform in thousands of companies. This blog series explores different data integration and ingestion options, including traditional ETL / iPaaS and data streaming with Apache Kafka. The discussion covers why point-to-point Zero-ETL is only a short term win, why Reverse ETL is an anti-pattern for real-time use cases and when a Kappa Architecture and shifting data processing “to the left” into the streaming layer helps to build transactional and analytical real-time and batch use cases in a reliable and cost-efficient way.
This is part one of a blog series:
- THIS POST: Snowflake Integration Patterns: Zero ETL and Reverse ETL vs. Apache Kafka
- Snowflake Data Integration Options for Apache Kafka (including Iceberg)
- Apache Kafka + Flink + Snowflake: Cost Efficient Analytics and Data Governance
Subscribe to my newsletter to get an email about the next publications.
Snowflake: Transitioning from a Cloud-Native Data Warehouse to a Data Cloud for Everything
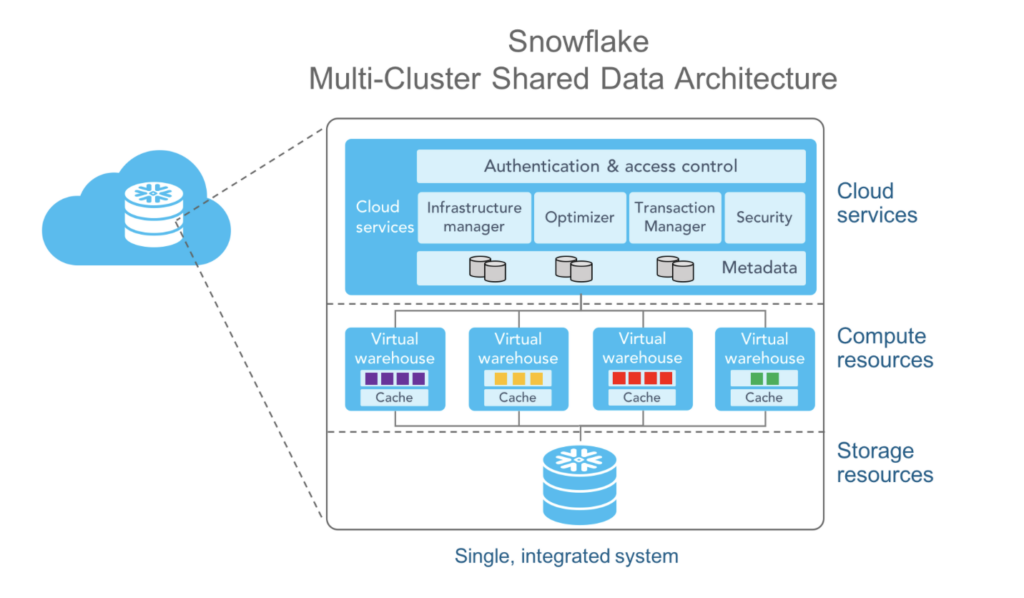
Snowflake is a leading cloud-based data warehousing platform (CDW) that allows organizations to store and analyze large volumes of data in a scalable and efficient manner. It works with cloud providers such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). Snowflake provides a fully managed and multi-cluster, multi-tenant architecture, making it easy for users to scale and manage their data storage and processing needs.
The Origin: A Cloud Data Warehouse
Snowflake provides a flexible and scalable solution for managing and analyzing large datasets in a cloud environment. It has gained popularity for its ease of use, performance, and the ability to handle diverse workloads with its separation of compute and storage.
Reporting and analytics are the major use cases. Data integration and transformation using ELT (Extract-Load-Transform) is a common scenario; often using DBT to process the data within Snowflake.
Snowflake earns its reputation for simplicity and ease of use. It uses SQL for querying, making it familiar to users with SQL skills. The platform abstracts many of the complexities of traditional data warehousing, reducing the learning curve.
The Future: One ‘Data Cloud’ for Everything?
Snowflake is much more than a data warehouse. Product innovation and several acquisitions strengthen the product portfolio. Several acquired companies focus on different topics related to the data management space, including search, privacy, data engineering, generative AI, and more. The company transitions into a “Data Cloud” (that’s Snowflake’s current marketing term).
Quote from Snowflake’s website: “The Data Cloud is a global network that connects organizations to the data and applications most critical to their business. The Data Cloud enables a wide range of possibilities, from breaking down silos within an organization to collaborating over content with partners and customers, and even integrating external data and applications for fresh insights. Powering the Data Cloud is Snowflake’s single platform. Its unique architecture connects businesses globally, at practically any scale to bring data and workloads together.”

Well, we will see what the future brings. Today, Snowflake’s main use case is Cloud Data Warehouse, similar to SAP focusing on ERP or Databricks on data lake and ML/AI. I am always sceptical when a company tries to solve every problem and use case within a single platform. A technology has sweet spots for some use cases, but brings trade-offs for other use cases from a technical and cost perspective.
Snowflake Trade-Offs: Cloud-Only, Cost, and More
While Snowflake is a powerful and widely used data cloud-native platform, it’s important to consider some potential disadvantages:
- Cost: While Snowflake’s architecture allows for scalability and flexibility, it can also result in costs that may be higher than anticipated. Users should carefully manage and monitor their resource consumption to avoid unexpected expenses. “DBT’ing” all the data sets at rest again and again increases the TCO significantly.
- Cloud-Only: On-premise and hybrid architectures are not possible. As a cloud-based service, Snowflake relies on a stable and fast internet connection. In situations where internet connectivity is unreliable or slow, users may experience difficulties in accessing and working with their data.
- Data at Rest: Moving large volumes of data around and processing it repeatedly is time-consuming, bandwidth-intensive and costly. This is sometimes referred to as the “data gravity” problem, where it becomes challenging to move large datasets quickly because of physical constraints.
- Analytics: Snowflake initially started as a cloud data warehouse. It was never built for operational use cases. Choose the right tool for the job regarding SLAs, latency, scalability, and features. There is no single allrounder.
- Customization Limitations: While Snowflake offers a wide range of features, there may be cases where users require highly specialized or custom configurations that are not easily achievable within the platform.
- Third-Party Tool Integration: Although Snowflake supports various data integration tools and provides its own marketplace, there may be instances where specific third-party tools or applications are not fully integrated or at least not optimized for use with Snowflake.
These trade-offs show why many enterprises (have to) combine Snowflake with other technologies and SaaS to build a scalable but also cost-efficient enterprise architecture. While all of the above trade-offs are obvious, cost concerns with the growing data sets and analytical queries are the clear number one I hear from customers these days.
Snowflake Integration Patterns
Every middleware provides a Snowflake connector today because of its market presence. Let’s explore the different integration options:
- Traditional data integration with ETL, ESB or iPaaS
- ELT within the data warehouse
- Reverse ETL with purpose built products
- Data Streaming (usually via the industry standard Apache Kafka)
- Zero ETL via direct configurable point-to-point connectons
1. Traditional Data Integration: ETL, ESB, iPaaS
ETL is the way most people think about integrating with a data warehouse. Enterprises started adopting Informatica and Teradata decades ago. The approach is still the same today:
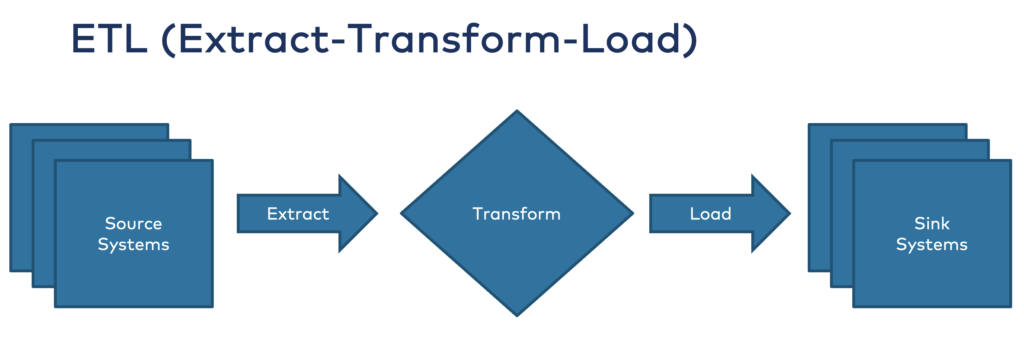
ETL meant batch processing in the past. An ESB (Enterprise Service Bus) often allows near real-time integration (if the data warehouse is capable of this) – but has scalability issues because of the underlying API (= HTTP/REST) or message broker infrastructure.
iPaaS (Integration Platform as a Service) is very similar to an ESB, often from the same vendors, but provides as fully managed service in the public cloud. Often not cloud-native, but just deployed in Amazon EC2 instances (so-called cloud washing of legacy middleware).
2. ELT: Data Processing within the Data Warehouse
Many Snowflake users actually only ingest the raw data sets and do all the transformations and processing in the data warehouse.
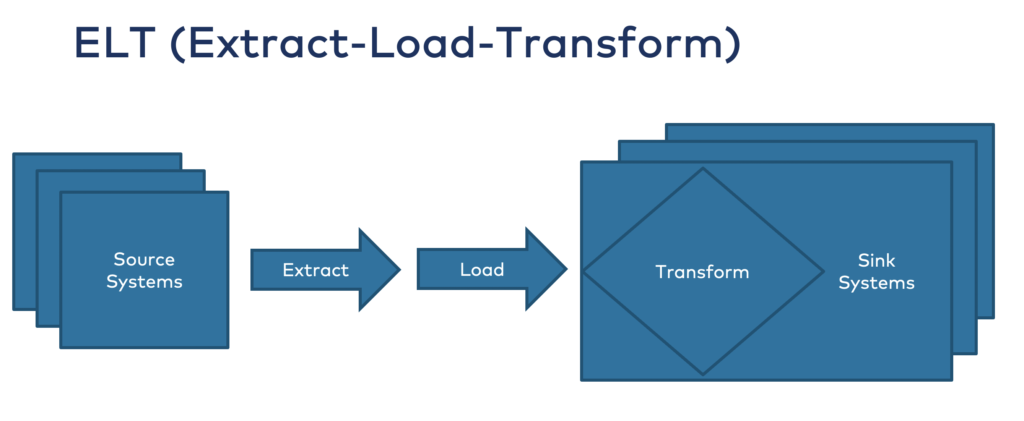
DBT is the favorite tool of most data engineers. The simple tool enables the straightforward execution of simple SQL queries to re-processing data again and again at rest. While the ELT approach is very intuitive for the data engineers, it is very costly for the business unit that pays the Snowflake bill.
3. Reverse ETL: “Real Time Batch” – What?!
As the name says, Reverse ETL turns the story from ETL around. It means moving data from a cloud data warehouse into third-party systems to “make data operational”, as the marketing of these solutions says:
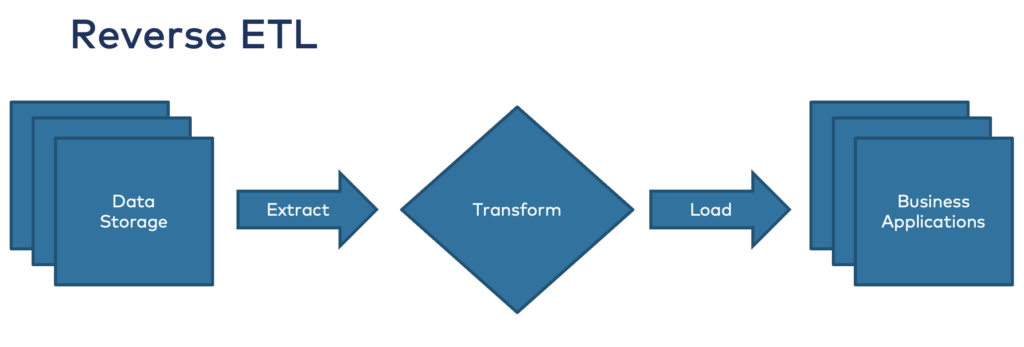
Unfortunately, Reverse ETL is a huge ANTI-PATTERN to build real-time use cases. And it is NOT cost efficient.
If you store data in a data warehouse or data lake, you cannot process it in real-time anymore as it is already stored at rest. These data stores are built for indexing, search, batch processing, reporting, model training, and other use cases that make sense in the storage system. But you cannot consume the data in real-time in motion from storage at rest:
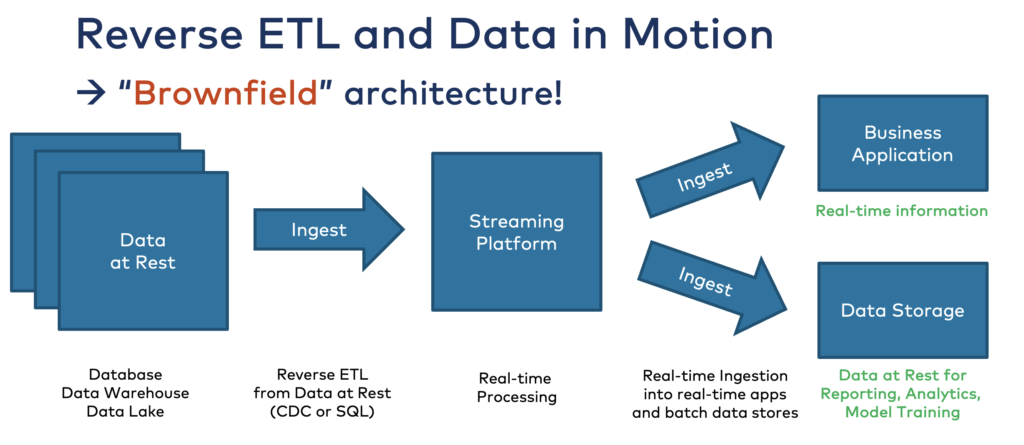
Instead, think about only feeding (the right) data into the data warehouse for reporting and analytics. Real-time use cases should run ONLY in a real-time platform like an ESB or a data streaming platform.
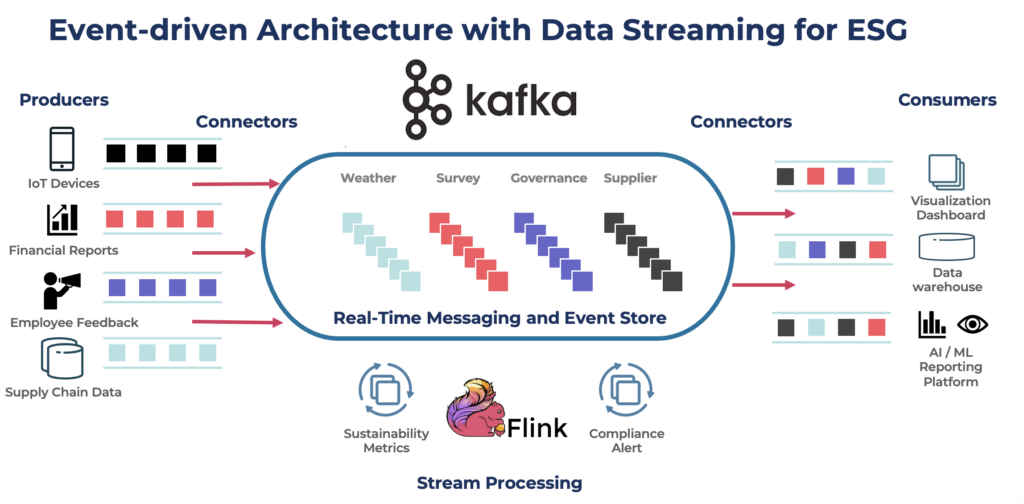
4. Data Streaming: Apache Kafka for Real Time and Batch with Data Consistency
Data streaming is a relatively new software category. It combines:
- real-time messaging at scale for analytics and operational workloads.
- an event store for long-term persistence, true decoupling of producers and consumers, and replayability of historical data in guaranteed order.
- data integration in real-time at scale.
- stream processing for stateless or stateful data correlation of real-time and historical data.
- data governance for end-to-end visiblity and observability across the entire data flow
The de facto standard of data streaming is Apache Kafka.
Apache Flink is becoming the de facto standard for stream processing; but Kafka Streams is another excellent and widely adopted Kafka-native library.
In December 2023, the research company Forrester published “The Forrester Wave™: Streaming Data Platforms, Q4 2023“. Get free access to the report here. The report explores what Confluent and other vendors like AWS, Microsoft, Google, Oracle and Cloudera provide. Similarly, in April 2024, IDC published the IDC MarketScape for Worldwide Analytic Stream Processing 2024.
Data streaming enables real-time data processing where it is appropriate from a technical perspective or where it adds business value versus batch processing. But data streaming also connects to non-real-time systems like Snowflake for reporting and batch analytics.
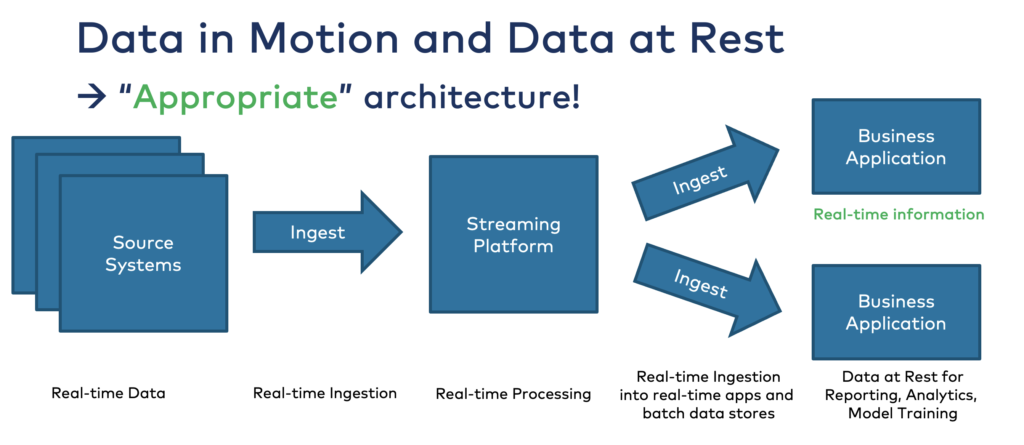
Kafka Connect is part of open source Kafka. It provides data integration capabilities in real-time at scale with no additional ETL tool. Native connectors to streaming systems (like IoT or other message brokers) and Change Data Capture (CDC) connectors that consume from databases like Oracle or Salesforce CRM push changes as event in real-time into Kafka.
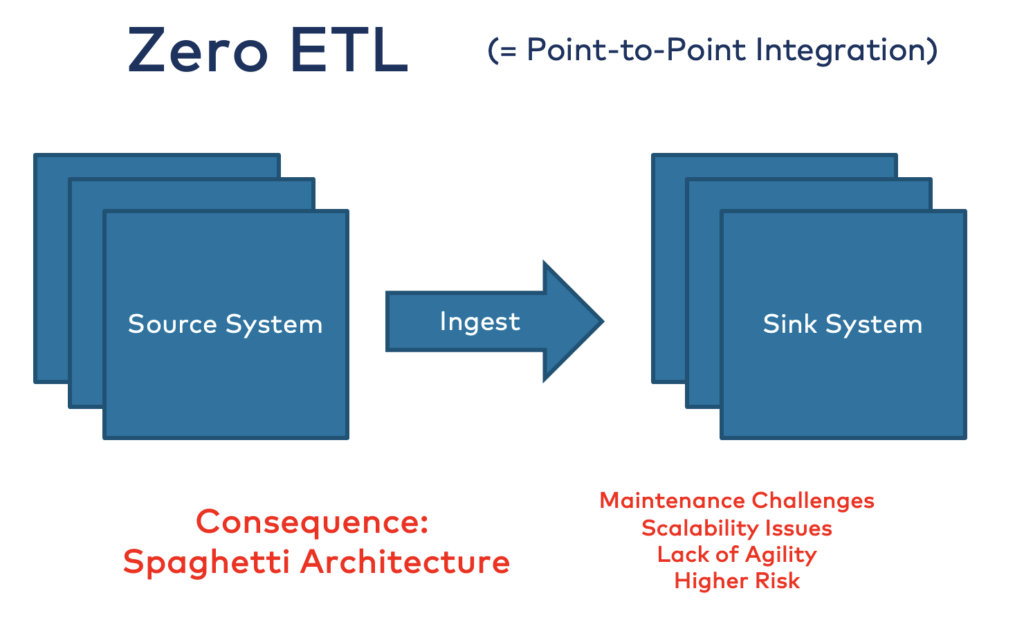
5. Zero ETL: Point-to-Point Integrations and Spaghetti Architecture
Zero ETL refers to an approach in data processing. ETL processes are minimized or eliminated. Traditional ETL processes – as discussed in the above sections – involve extracting data from various sources, transforming it into a usable format, and loading it into a data warehouse or data lake.
In a Zero ETL approach, data is ingested in its raw form directly from a data source into a data lake without the need for extensive transformation upfront. This raw data is then made available for analysis and processing in its native format, allowing organizations to perform transformations and analytics on-demand or in real-time as needed. By eliminating or minimizing the traditional ETL pipeline, organizations can reduce data processing latency, simplify data integration, and enable faster insights and decision-making.
Zero ETL from Salesforce CRM to Snowflake
A concrete Snowflake example is the bi-directional integration and data sharing with Salesforce. The feature GA’ed recently and enables “zero-ETL data sharing innovation that reduces friction and empowers organizations to quickly surface powerful insights across sales, service, marketing and commerce applications”.
So far, the theory. Why did I put this integration pattern last and not first on my list if it sounds so amazing?
Spaghetti Architecture: Integration and Data Mess
For decades, you can do point-to-point integrations with CORBA, SOAP, REST/HTTP, and many other technologies. The consequence is a spaghetti architecture:
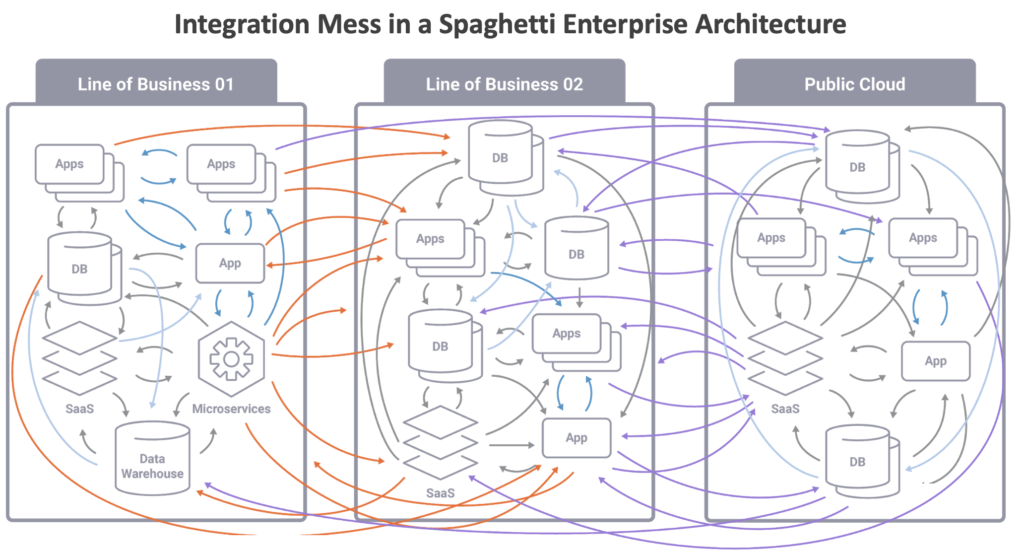
In a spaghetti architecture, code dependencies are often tangled and interconnected in a way that makes it challenging to make changes or add new features without unintended consequences. This can result from poor design practices, lack of documentation, or gradual accumulation of technical debt.
The consequences of a spaghetti architecture include:
- Maintenance Challenges: It becomes difficult for developers to understand and modify the codebase without introducing errors or unintended side effects.
- Scalability Issues: The architecture may struggle to accommodate growth or changes in requirements, leading to performance bottlenecks or instability.
- Lack of Agility: Changes to the system become slow and cumbersome, inhibiting the ability of the organization to respond quickly to changing business needs or market demands.
- Higher Risk: The complexity and fragility of the architecture increase the risk of software bugs, system failures, and security vulnerabilities.
Therefore, please do NOT build zero-code point-to-point spaghetti architectures if you care about the mid-term and long-term success of your company regarding data consistency, time-to-market and cost efficiency.
Short-Term and Long-Term Impact of Snowflake and Integration Patterns with(out) Kafka
Zero ETL using Snowflake sounds compelling. But it is only if you need a point-to-point connection. Most information is relevant in many applications. Data Streaming with Apache Kafka enables true decoupling. Ingest events only once and consume from multiple downstream applications independently with different communication patterns (real-time, batch, request-response). This is a common pattern for years in legacy integration, for instance, mainframe offloading. Snowflake is rarely the only endpoint of your data.
Reverse ETL is a pattern only needed if you ingest data into a single data warehouse or data lake like Snowflake with a dumb pipeline (Kafka, ETL tool, Zero ETL, or any other code). Apache Kafka allows you to avoid Revere ETL. And it makes the architecture more performance, scalable and flexible. Sometimes Reverse ETL cannot be avoided for organizations or historical reasons. That’s fine. But don’t design an enterprise architecture where you ingest data just to reverse it later. Most times, Reverse ETL is an anti-pattern.
What is your point of view on integrating patterns for Snowflake? How do you integrate it into an enterprise architecture? What are your experiences and opinions? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.