One of the greatest wishes of companies is end-to-end visibility in their operational and analytical workflows. Where does data come from? Where does it go? To whom am I giving access to? How can I track data quality issues? The capability to follow the data flow to answer these questions is called data lineage. This blog post explores market trends, efforts to provide an open standard with OpenLineage, and how data governance solutions from vendors such as IBM, Google, Confluent and Collibra help fulfil the enterprise-wide data governance needs of most companies, including data streaming technologies such as Apache Kafka and Flink.
What is Data Governance?
Data governance refers to the overall management of the availability, usability, integrity, and security of data used in an organization. It involves establishing processes, roles, policies, standards, and metrics to ensure that data is properly managed throughout its lifecycle. Data governance aims to ensure that data is accurate, consistent, secure, and compliant with regulatory requirements and organizational policies. It encompasses activities such as data quality management, data security, metadata management, and compliance with data-related regulations and standards.
What is the Business Value of Data Governance?
The business value of data governance is significant and multifaceted:
- Improved Data Quality: Data governance ensures that data is accurate, consistent, and reliable, leading to better decision-making, reduced errors, and improved operational efficiency.
- Enhanced Regulatory Compliance: By establishing policies and procedures for data management and ensuring compliance with regulations such as GDPR, HIPAA, and CCPA, data governance helps mitigate risks associated with non-compliance, including penalties and reputational damage.
- Increased Trust and Confidence: Effective data governance instills trust and confidence in data among stakeholders. It leads to greater adoption of data-driven decision-making and improved collaboration across departments.
- Cost Reduction: By reducing data redundancy, eliminating data inconsistencies, and optimizing data storage and maintenance processes, data governance helps organizations minimize costs associated with data management and compliance.
- Better Risk Management: Data governance enables organizations to identify, assess, and mitigate risks associated with data management, security, privacy, and compliance, reducing the likelihood and impact of data-related incidents.
- Support for Business Initiatives: Data governance provides a foundation for strategic initiatives such as digital transformation, data analytics, and AI/ML projects by ensuring that data is available, accessible, and reliable for analysis and decision-making.
- Competitive Advantage: Organizations with robust data governance practices can leverage data more effectively to gain insights, innovate, and respond to market changes quickly, giving them a competitive edge in their industry.
Overall, data governance contributes to improved data quality, compliance, trust, cost efficiency, risk management, and competitiveness, ultimately driving better business outcomes and value creation.
What is Data Lineage?
Data lineage refers to the ability to trace the complete lifecycle of data, from its origin through every transformation and movement across different systems and processes. It provides a detailed understanding of how data is created, modified, and consumed within an organization’s data ecosystem, including information about its source, transformations applied, and destinations.
Data Lineage is an essential component of Data Governance: Understanding data lineage helps organizations ensure data quality, compliance with regulations, and adherence to internal policies by providing visibility into data flows and transformations.
Data Lineage is NOT Event Tracing!
Event tracing and data lineage a are different concepts that serve distinct purposes in the realm of data management:
Data Lineage:
- Data lineage refers to the ability to track and visualize the complete lifecycle of data, from its origin through every transformation and movement across different systems and processes.
- It provides a detailed understanding of how data is created, modified, and consumed within an organization’s data ecosystem, including information about its source, transformations applied, and destinations.
- Data lineage focuses on the flow of data and metadata, helping organizations ensure data quality, compliance, and trustworthiness by providing visibility into data flows and transformations.
Event Tracing:
- Event tracing, also known as distributed tracing, is a technique used in distributed systems to monitor and debug the flow of individual requests or events as they traverse through various components and services.
- It involves instrumenting applications to generate trace data, which contains information about the path and timing of events as they propagate across different nodes and services.
- Event tracing is primarily used for performance monitoring, troubleshooting, and root cause analysis in complex distributed systems, helping organizations identify bottlenecks, latency issues, and errors in request processing.
In summary, data lineage focuses on the lifecycle of data within an organization’s data ecosystem, while event tracing is more concerned with monitoring the flow of individual events or requests through distributed systems for troubleshooting and performance analysis.
Here is an example in payments processing: Data lineage would track the path of payment data from initiation to settlement, detailing each step and transformation it undergoes. Meanwhile, event tracing would monitor individual events within the payment system in real-time, capturing the sequence and outcome of actions, such as authentication checks and transaction approvals.
What is the Standard ‘OpenLineage’?
Open Lineage is an open-source project that aims to standardize metadata management for data lineage. It provides a framework for capturing, storing, and sharing metadata related to the lineage of data as it moves through various stages of processing within an organization’s data infrastructure. By providing a common format and APIs for expressing and accessing lineage information, Open Lineage enables interoperability between different data processing systems and tools, facilitating data governance, compliance, and data quality efforts.
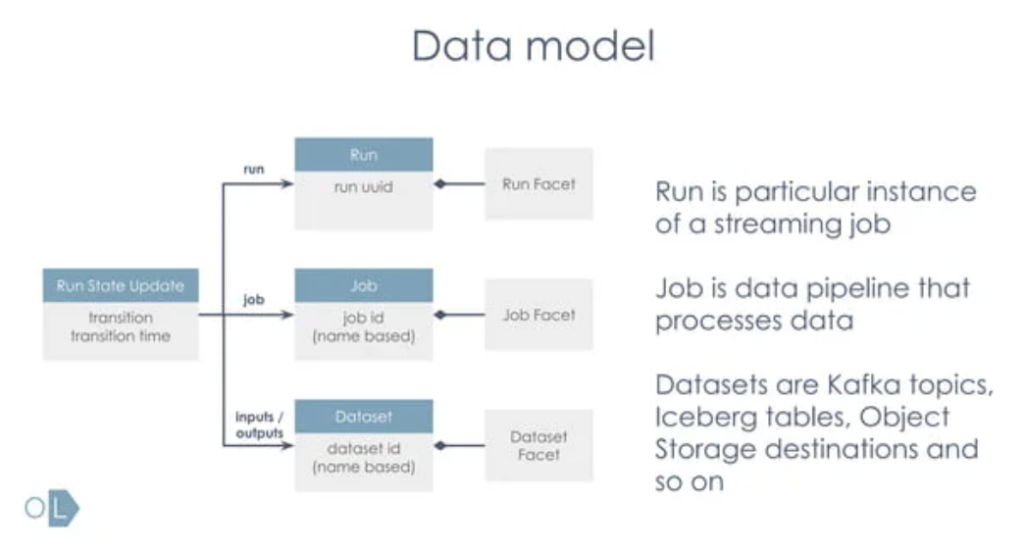
OpenLineage is an open platform for the collection and analysis of data lineage. It includes an open standard for lineage data collection, integration libraries for the most common tools, and a metadata repository/reference implementation (Marquez). Many frameworks and tools already support producers/consumers:

Data Governance for Data Streaming (like Apache Kafka and Flink)
Data streaming involves the real-time processing and movement of data through its distributed messaging platform. This enables organizations to efficiently ingest, process, and analyze large volumes of data from various sources. By decoupling data producers and consumers, a data streaming platform provides a scalable and fault-tolerant solution for building real-time data pipelines to support use cases such as real-time analytics, event-driven architectures, and data integration.
The de facto standard for data streaming is Apache Kafka, used by over 100,000 organizations. Kafka is not just used for big data, it also provides support for transactional workloads.
Data Governance Differences with Data Streaming Compared to Data Lake and Data Warehouse?
Implementing data governance and lineage with data streaming presents several differences and challenges compared to data lakes and data warehouses:
- Real-Time Nature: Data streaming involves the processing of data in real-time when it is generated, whereas data lakes and data warehouses typically deal with batch processing of historical data. This real-time nature of data streaming requires governance processes and controls that can operate at the speed of streaming data ingestion, processing, and analysis.
- Dynamic Data Flow: Data streaming environments are characterized by dynamic and continuous data flows, with data being ingested, processed, and analyzed in near-real-time. This dynamic nature requires data governance mechanisms that can adapt to changing data sources, schemas, and processing pipelines in real-time, ensuring that governance policies are applied consistently across the entire streaming data ecosystem.
- Granular Data Lineage: In data streaming, data lineage needs to be tracked at a more granular level compared to data lakes and data warehouses. This is because streaming data often undergoes multiple transformations and enrichments as it moves through streaming pipelines. In some cases, the lineage of each individual data record must be traced to ensure data quality, compliance, and accountability.
- Immediate Actionability: Data streaming environments often require immediate actionability of data governance policies and controls to address issues such as data quality issues, security breaches, or compliance violations in real-time. This necessitates the automation of governance processes and the integration of governance controls directly into streaming data processing pipelines, enabling timely detection, notification, and remediation of governance issues.
- Scalability and Resilience: Data streaming platforms like Apache Kafka and Apache Flink are designed for scalability and resilience to handle both, high volumes of data and transactional workloads with critical SLAs. The platform must ensure continuous stream processing even in the face of failures or disruptions. Data governance mechanisms in streaming environments need to be similarly scalable and resilient to keep pace with the scale and speed of streaming data processing, ensuring consistent governance enforcement across distributed and resilient streaming infrastructure.
- Metadata Management Challenges: Data streaming introduces unique challenges for metadata management, as metadata needs to be captured and managed in real-time to provide visibility into streaming data pipelines, schema evolution, and data lineage. This requires specialized tools and techniques for capturing, storing, and querying metadata in streaming environments, enabling stakeholders to understand and analyze the streaming data ecosystem effectively.
In summary, implementing data governance with data streaming requires addressing the unique challenges posed by the real-time nature, dynamic data flow, granular data lineage, immediate actionability, scalability, resilience, and metadata management requirements of streaming data environments. This involves adopting specialized governance processes, controls, tools, and techniques tailored to the characteristics and requirements of data streaming platforms like Apache Kafka and Apache Flink.
Schemas and Data Contracts for Streaming Data
The foundation of data governance for streaming data are schemas and data contracts. Confluent Schema Registry is available on GitHub. It became the de facto standard for ensuring data quality and governance in Kafka projects across all industries. Not just for Confluent projects, but also in the broader community leveraging open source technologies. Schema Registry is available under the Confluent Community License that allows deployment in production scenarios with no licensing costs.
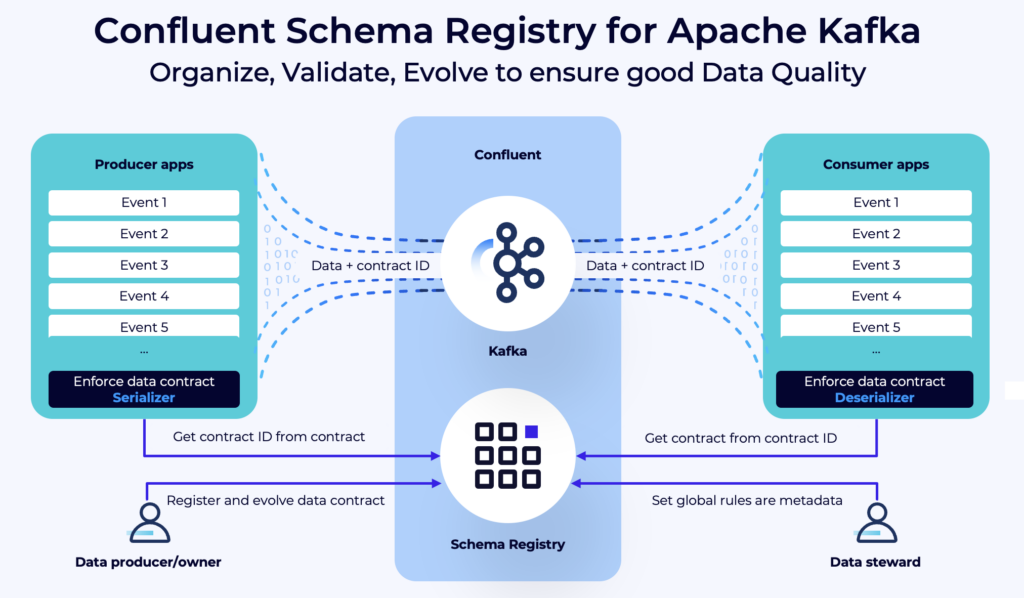
For more details, check out my article “Policy Enforcement and Data Quality for Apache Kafka with Schema Registry“. And here are two great case studies for financial services companies leveraging schemas and group-wide API contracts across the organization for data governance:
- Raiffeisenbank International (RBI): Enterprise-wide data mesh across countries with data streaming.
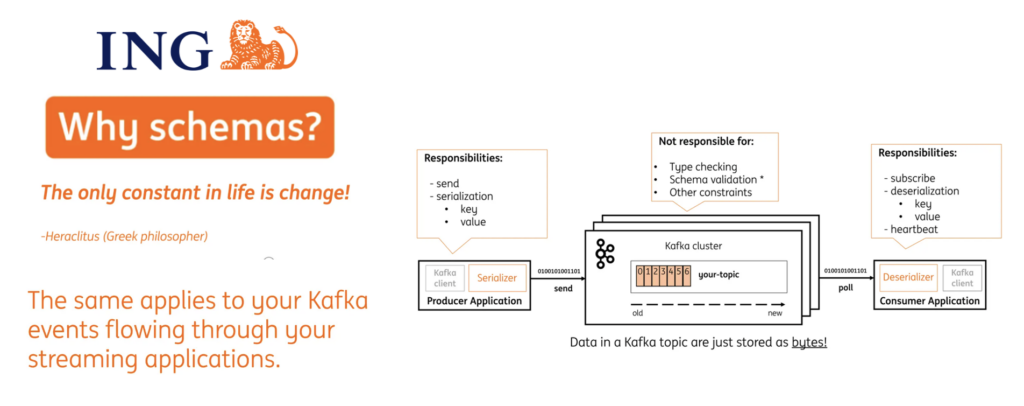
- ING Bank: Schemas in the data streaming enterprise architecture to evolve data contracts
Example: Confluent’s Stream Data Governance Suite for Kafka and Flink
Confluent Cloud is an excellent example of a data governance solution for data streaming. The fully-managed data streaming platform provides capabilities such as
- Data Catalog
- Data Lineage
- Stream Sharing
- Data Portal
The Data Portal combines the capabilities in an intuitive user interface to discover, explore, access and use streaming data products:
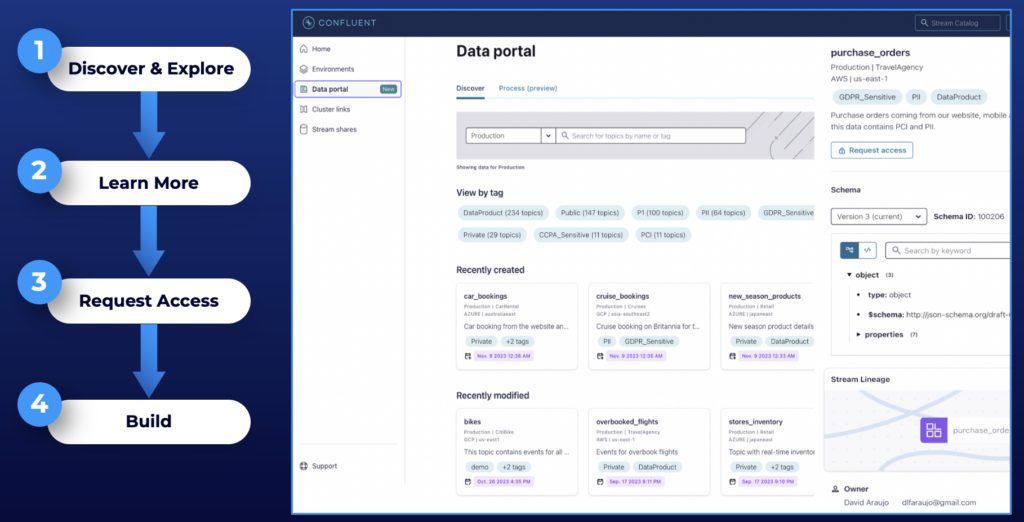
All information and functionality are available in the UI for humans and as an API for integration scenarios.
If you want to learn more about data streaming and data governance in a fun way, check out the free comic ebook “The Data Streaming Revolution: The Force of Kafka + Flink Awakens“:

Data Lineage for Streaming Data
Being a core fundament of data governance, data streaming projects require good data lineage for visibility and governance. Today’s market mainly provides two options: Custom projects or buying a commercial product/cloud service. But the market develops. Open standards emerge for data lineage, and integrate data streaming into its implementations.
Let’s explore an example of a commercial solution and an open standard for streaming data lineage:
- Cloud service: Data Lineage as part of Confluent Cloud
- Open standard: OpenLineage’s integration with Apache Flink and Marquez
Data Lineage in Confluent Cloud for Kafka and Flink
To move forward with updates to critical applications or answer questions on important subjects like data regulation and compliance, teams need an easy means of comprehending the big picture journey of data in motion. Confluent Cloud provides a solution deeply integrated with Kafka and Flink as part of the fully managed SaaS offering.
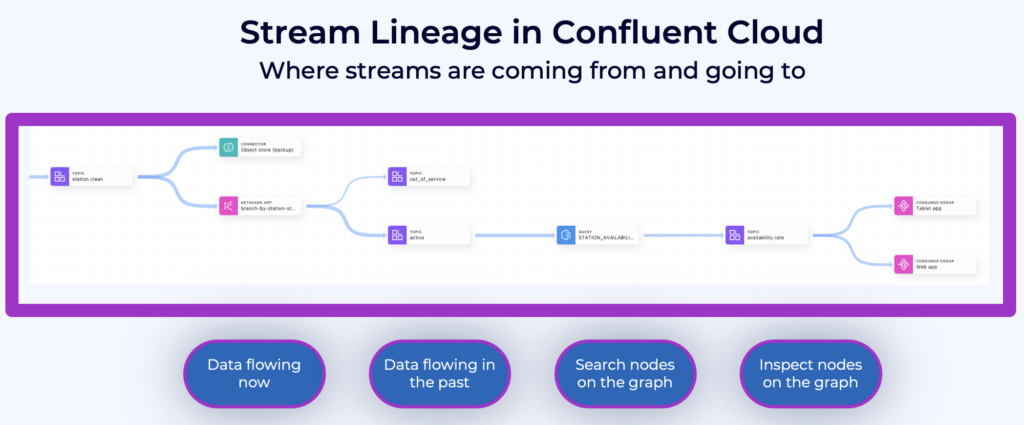
Stream lineage provides a graphical UI of event streams and data relationships with both a bird’s eye view and drill-down magnification for answering questions like:
- Where did data come from?
- Where is it going?
- Where, when, and how was it transformed?
Answers to questions like these allow developers to trust the data they’ve found, and gain the visibility needed to make sure their changes won’t cause any negative or unexpected downstream impact. Developers can learn and decide quickly with live metrics and metadata inspection embedded directly within lineage graphs.
The Confluent documentation goes into much more detail, including examples, tutorials, free cloud credits, etc. Most of the above description is also copied from there.
OpenLineage for Stream Processing with Apache Flink
In recent months, stream processing has gained the particular focus of the OpenLineage community, as described in a dedicated talk at Kafka Summit 2024 in London.
Many useful features for stream processing completed or begun in OpenLineage’s implementation, including:
- A seamless OpenLineage and Apache Flink integration
- Support for streaming jobs in data catalogs like Marquez, manta, atlan
- Progress on a built-in lineage API within the Flink codebase
Here is a screenshot from the live demo of the Kafka Summit talk that shows data lineage across Kafka Topics, Flink applications, and other databases with the reference implementation of OpenLineage (Marquez):
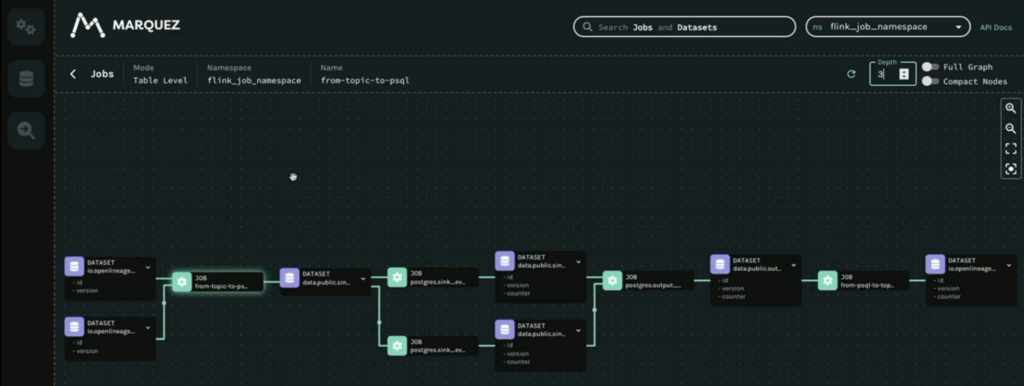
The OpenLineage Flink integration is in the early stage with limitations, like no support for Flink SQL or Table API yet. But this is an important initiative. Cross-platform lineage enables a holistic overview of data flow and its dependencies within organizations. This must include stream processing (which often runs the most critical workloads in an enterprise).
The Need for Enterprise-Wide Data Governance and Data Lineage
Data Governance, including Data Lineage, is an enterprise-wide challenge. OpenLineage is an excellent approach for an open standard to integrate with various data platforms like data streaming platform, data lake, data warehouse, lake house, and any other business application.
However, we are still early on this journey. Most companies (have to) build custom solutions today for enterprise-wide governance and lineage of data across various platforms. Short term, most companies leverage purpose-built data governance and lineage features from cloud products like Confluent, Databricks and Snowflake. This makes sense as it creates visibility in the data flows and improves data quality.
Enterprise-wide data governance needs to integrate with all the different data platforms. Today, most companies have built their own solutions – if they have anything at all today (most don’t yet)… Dedicated enterprise governance suites like Collibra or Microsoft Purview get adopted more and more to solve these challenges. And software/cloud vendors like Confluent integrate their purpose-built data lineage and governance into these platforms. Either just via open APIs or via direct and certified integrations.
Balancing Standardization and Innovation with Open Standards and Cloud Services
OpenLineage is a great community initiative to standardize the integration between data platforms and data governance. Hopefully, vendors will adopt such open standards in the future. Today, it is an early stage and you will probably integrate via open APIs or certified (proprietary) connectors.
Balancing standardization and innovation is always a trade-off: Finding the right balance between standardization and innovation entails simplicity, flexibility, and diligent review processes, with a focus on addressing real-world pain points and fostering community-driven extensions.
If you want to learn more about open standards for data governance, please watch this expert panel for data lineage where Accenture and Confluent welcomed experts from Open Lineage, Collibra, Google, IBM / Mantra, IBM / Egeria, Atlan, and Confluent (actually me).

How do you implement data governance and lineage? Do you already leverage OpenLineage or other standards? Or are you investing in commercial products? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.






