How do you prevent hallucinations from large language models (LLMs) in GenAI applications? LLMs need real-time, contextualized, and trustworthy data to generate the most reliable outputs. This blog post explains how RAG and a data streaming platform with Apache Kafka and Flink make that possible. A lightboard video shows how to build a context-specific real-time RAG architecture. Also, learn how the travel agency Expedia leverages data streaming with Generative AI using conversational chatbots to improve the customer experience and reduce the cost of service agents.

What is Retrieval Augmented Generation (RAG) in GenAI?
Generative AI (GenAI) refers to artificial intelligence (AI) systems that can create new content, such as text, images, music, or code, often mimicking human creativity. These systems use advanced machine learning techniques, particularly deep learning models like neural networks, to generate data that resembles the training data they were fed. Popular examples include language models like GPT-3 for text generation and DALL-E for image creation.
Large Language Models like ChatGPT use lots of public data, are very expensive to train, and do not provide domain-specific context. Training own models is not an option for most companies because of limitations in cost and expertise.
Retrieval Augmented Generation (RAG) is a technique in Generative AI to solve this problem. RAG enhances the performance of language models by integrating information retrieval mechanisms into the generation process. This approach aims to combine the strengths of information retrieval systems and generative models to produce more accurate and contextually relevant outputs.
Pinecone created an excellent diagram that explains RAG and shows the relation to an embedding model and vector database:
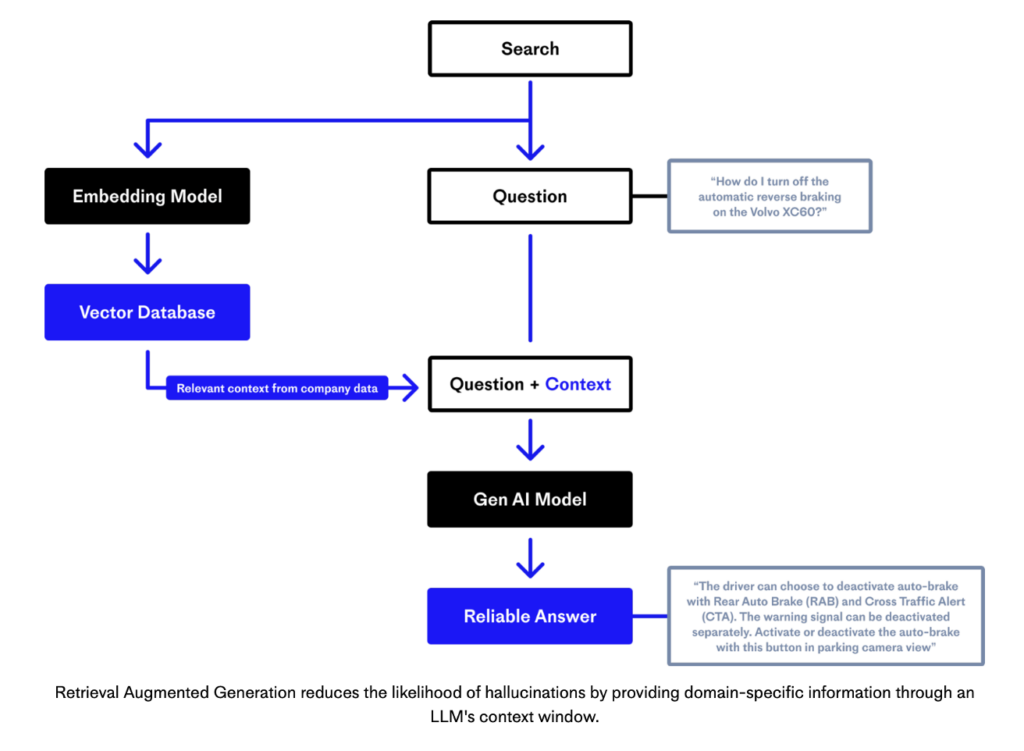
Benefits of Retrieval Augmented Generation
RAG brings various benefits to the GenAI enterprise architecture:
- Access to External Information: By retrieving relevant documents from a vast vector database, RAG allows the generative model to leverage up-to-date and domain-specific information that it may not have been trained on.
- Reduced Hallucinations: Generative models can sometimes produce confident but incorrect answers (hallucinations). By grounding responses in retrieved documents, RAG reduces the likelihood of such errors.
- Domain-Specific Applications: RAG can be tailored to specific domains by curating the retrieval database with domain-specific documents, enhancing the model’s performance in specialized areas such as medicine, law, finance or travel.
However, one of the most significant problems still exists: the missing right context and up-to-date information…
How does Data Streaming with Apache Kafka and Flink Help in the RAG Architecture?
RAG is obviously crucial in enterprises where data privacy, up-to-date context, and the data integration with transactional and analytical systems like an order management system, booking platform or payment fraud engine must be consistent, scalable and in real-time.
An event-driven architecture is the foundation of data streaming with Kafka and Flink:
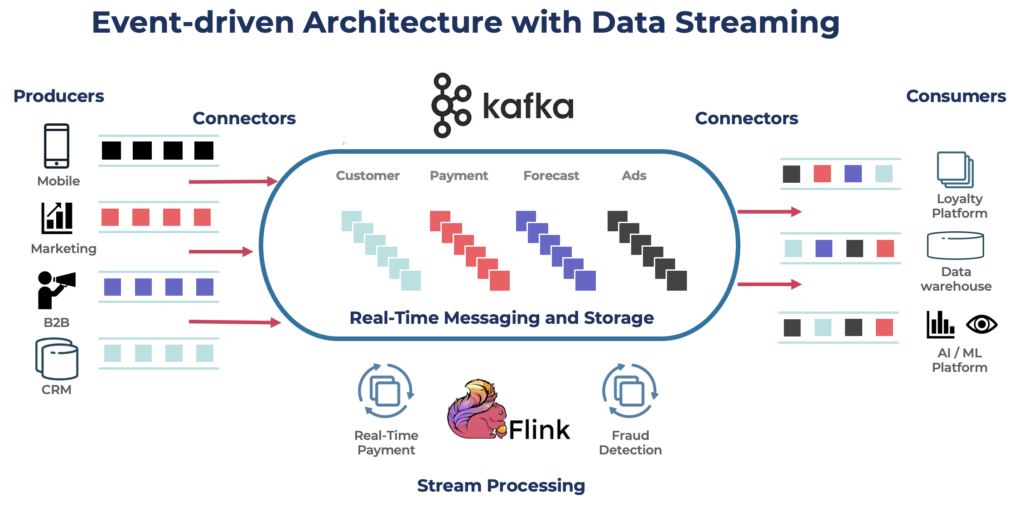
Apache Kafka and Apache Flink play a crucial role in the Retrieval Augmented Generation (RAG) architecture by ensuring real-time data flow and processing, which enhances the system’s ability to retrieve and generate up-to-date and contextually relevant information.
Here’s how Kafka and Flink contribute to the RAG architecture:
1. Real-Time Data Ingestion and Processing
Data Ingestion: Kafka acts as a high-throughput, low-latency messaging system that ingests real-time data from various data sources, such as databases, APIs, sensors, or user interactions.
Event Streaming: Kafka streams the ingested data, ensuring that the data is available in real-time to downstream systems. This is critical for applications that require immediate access to the latest information.
Stream Processing: Flink processes the incoming data streams in real-time. It can perform complex transformations, aggregations, and enrichments on the data as it flows through the system.
Low Latency: Flink’s ability to handle stateful computations with low latency ensures that the processed data is quickly available for retrieval operations.
2. Enhanced Data Retrieval
Real-Time Updates: By using Kafka and Flink, the retrieval component of RAG can access the most current data. This is crucial for generating responses that are not only accurate but also timely.
Dynamic Indexing: As new data arrives, Flink can update the retrieval index in real-time, ensuring that the latest information is always retrievable in a vector database.
3. Scalability and Reliability
Scalable Architecture: Kafka’s distributed architecture allows it to handle large volumes of data, making it suitable for applications with high throughput requirements. Flink’s scalable stream processing capabilities ensure it can process and analyze large data streams efficiently. Cloud-native implementations or cloud services take over the operations and elastic scale.
Fault Tolerance: Kafka provides built-in fault tolerance by replicating data across multiple nodes, ensuring data durability and availability, even in the case of node failures. Flink offers state recovery and exactly-once processing semantics, ensuring reliable and consistent data processing.
4. Contextual Enrichment
Contextual Data Processing: Flink can enrich the raw data with additional context before the generative model uses it. For instance, Flink can join incoming data streams with historical data or external datasets to provide a richer context for retrieval operations.
Feature Extraction: Flink can extract features from the data streams that help improving the relevance of the retrieved documents or passages.
5. Integration and Flexibility
Seamless Integration: Kafka and Flink integrate well with model servers (e.g., for model embeddings) and storage systems (e.g., vector data bases for sematic search). This makes it easy to incorporate the right information and context into the RAG architecture.
Modular Design: The use of Kafka and Flink allows for a modular design where different components (data ingestion, processing, retrieval, generation) can be developed, scaled, and maintained independently.
Lightboard Video: RAG with Data Streaming
The following ten-minute lightboard video is an excellent interactive explanation for building a RAG architecture with embedding model, vector database, Kafka and Flink to ensure up-to-date and context-specific prompts into the LLM:
You are currently viewing a placeholder content from Default. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
Expedia: Generative AI in the Travel Industry
Expedia is an online travel agency that provides booking services for flights, hotels, car rentals, vacation packages, and other travel-related services. The IT architecture is built around data streaming for many years already, including the integration of transactional and analytical systems.
When Covid hit, Expedia had to innovate fast to handle all the support traffic spikes regarding flight rebookings, cancellations, and refunds. The project team trained a domain-specific conversational chatbot (long before ChatGPT and the term GenAI existed) and integrated it into the business process.

Here are some of the impressive business outcomes:
- Quick time to market with innovative new technology to solve business problems
- 60%+ of travelers are self-servicing in chat after the rollout
- 40%+ saved in variable agent costs by enabling self-service
Kafka and Flink Provide Real-Time Context for RAG in a GenAI Architecture
By leveraging Apache Kafka and Apache Flink, the RAG architecture can handle real-time data ingestion, processing, and retrieval efficiently. This ensures that the generative model has access to the most current and contextually rich information, resulting in more accurate and relevant responses. The scalability, fault tolerance, and flexibility offered by Kafka and Flink make them ideal components for enhancing the capabilities of RAG systems.
If you want to learn more about data streaming with GenAI, read these articles:
- Apache Kafka as Mission Critical Data Fabric for GenAI
- GenAI Demo with Kafka, Flink, LangChain and OpenAI
- Apache Kafka + Vector Database + LLM = Real-Time GenAI
How do you build a RAG architecture? Do you already leveraging Kafka and Flink for it? Or what technologies and architectures do you use? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.





