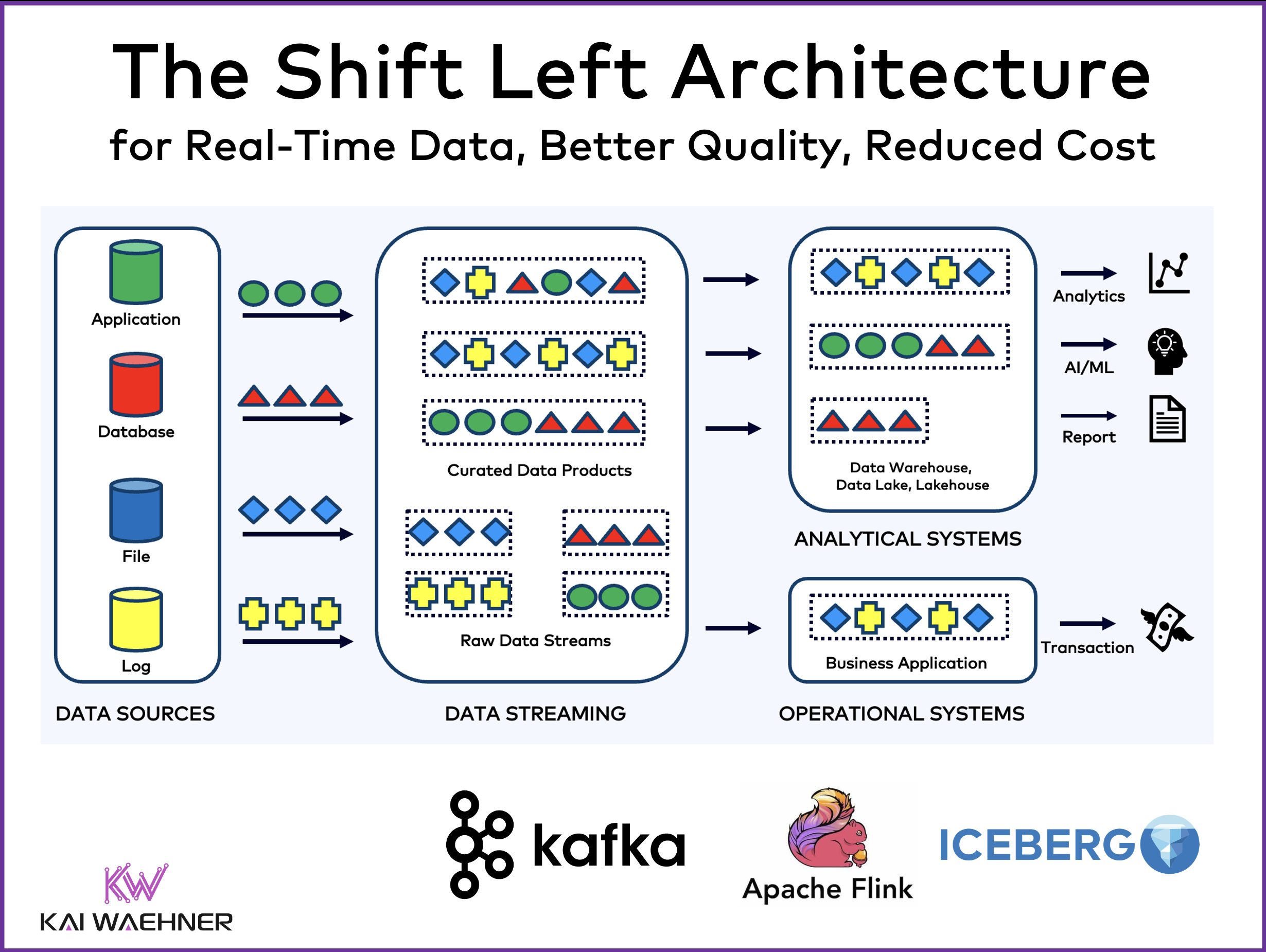
Data integration is a hard challenge in every enterprise. Batch processing and Reverse ETL are common practices in a data warehouse, data lake or lakehouse. Data inconsistency, high compute cost, and stale information are the consequences. This blog post introduces a new design pattern to solve these problems: The Shift Left Architecture enables a data mesh with real-time data products to unify transactional and analytical workloads with Apache Kafka, Flink and Iceberg. Consistent information is handled with streaming processing or ingested into Snowflake, Databricks, Google BigQuery, or any other analytics / AI platform to increase flexibility, reduce cost and enable a data-driven company culture with faster time-to-market building innovative software applications.
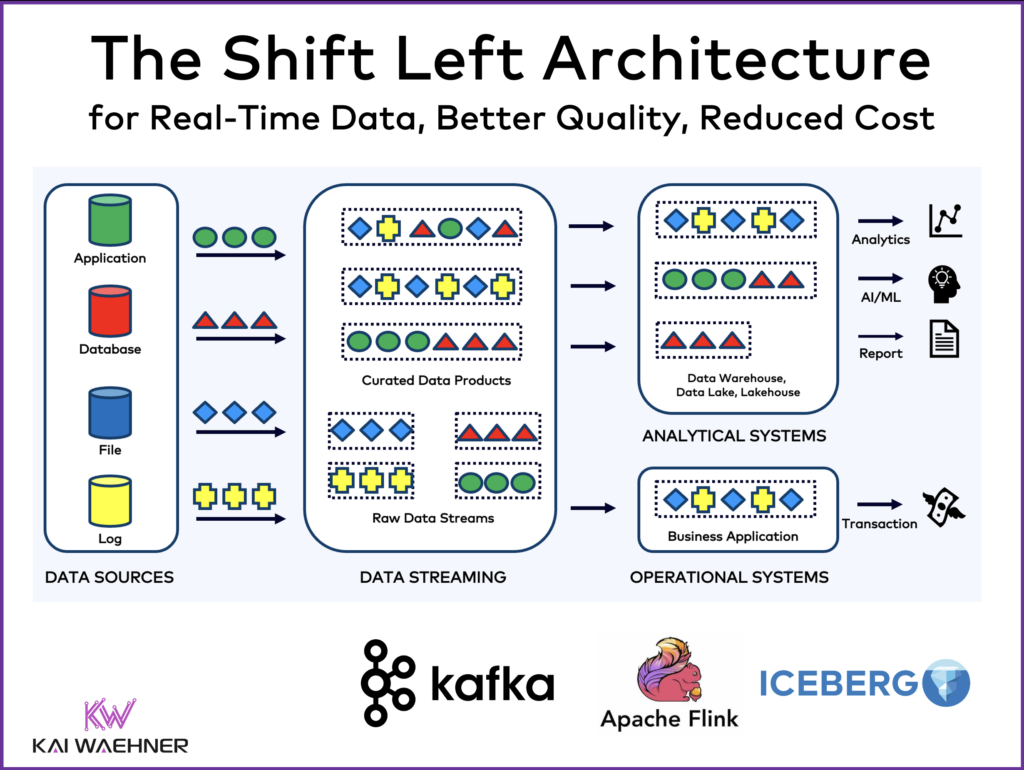
Data Products – The Foundation of a Data Mesh
A data product is a crucial concept in the context of a data mesh that represents a shift from traditional centralized data management to a decentralized approach.
McKinsey finds that “when companies instead manage data like a consumer product—be it digital or physical—they can realize near-term value from their data investments and pave the way for quickly getting more value tomorrow. Creating reusable data products and patterns for piecing together data technologies enables companies to derive value from data today and tomorrow”:
According to McKinsey, the benefits of the data product approach can be significant:
- New business use cases can be delivered as much as 90 percent faster.
- The total cost of ownership, including technology, development, and maintenance, can decline by 30 percent.
- The risk and data-governance burden can be reduced.
Data Product from a Technical Perspective
Here’s what a data product entails in a data mesh from a technical perspective:
- Decentralized Ownership: Each data product is owned by a specific domain team. Applications are truly decoupled.
- Sourced from Operational and Analytical Systems: Data products include information from any data source, including the most critical systems and analytics/reporting platforms.
- Self-contained and Discoverable: A data product includes not only the raw data but also the associated metadata, documentation, and APIs.
- Standardized Interfaces: Data products adhere to standardized interfaces and protocols, ensuring that they can be easily accessed and utilized by other data products and consumers within the data mesh.
- Data Quality: Most use cases benefit from real-time data. A data product ensures data consistency across real-time and batch applications.
- Value-Driven: The creation and maintenance of data products are driven by business value.
In essence, a data product in a data mesh framework transforms data into a managed, high-quality asset that is easily accessible and usable across an organization, fostering a more agile and scalable data ecosystem.
Anti-Pattern: Batch Processing and Reverse ETL
The “Modern” Data Stack leverages traditional ETL tools or data streaming for ingestion into a data lake, data warehouse or lakehouse. The consequence is a spaghetti architecture with various integration tools for batch and real-time workloads mixing analytical and operational technologies:
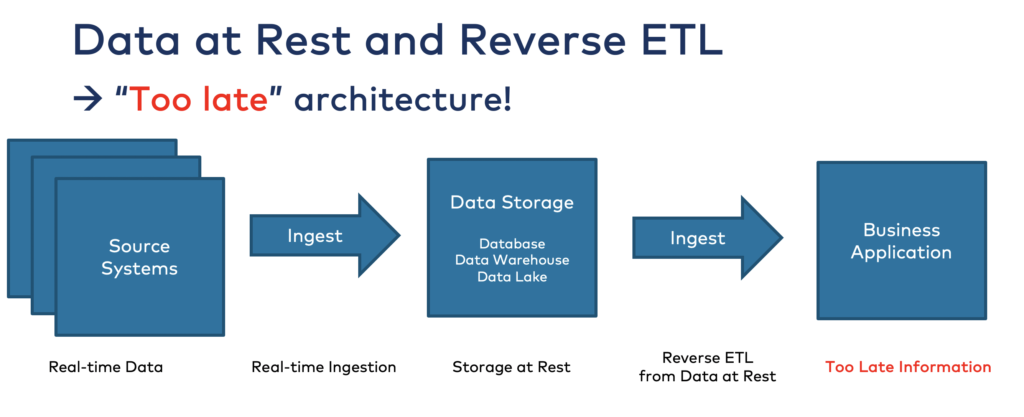
Reverse ETL is required to get information out of the data lake into operational applications and other analytical tools. As I have written about it previously, the combination of data lakes and Reverse ETL is an anti-pattern for the enterprise architecture largely due to the economic and organizational inefficiencies Reverse ETL creates. Event-driven data products enable a much simpler and more cost-efficient architecture.
One key reason for the need of batch processing and Reverse ETL patterns is the common use of the Lambda architecture: A data processing architecture that handles real-time and batch processing separately using different layers. This still widely exists in enterprise architectures. Not just for big data use cases like Hadoop/Spark and Kafka, but also for the integration with transactional systems like file-based legacy monoliths or Oracle databases.
Contrary, the Kappa Architecture handles both real-time and batch processing using a single technology stack. Learn more about “Kappa replacing Lambda Architecture” in its own article. TL;DR: The Kappa architecture is possible by bringing even legacy technologies into an event-driven architecture using a data streaming platform. Change Data Capture (CDC) is one of the most common helpers for this.
Traditional ELT in the Data Lake, Data Warehouse, Lakehouse
It seems like nobody does data warehouse anymore today. Everyone talks about a lakehouse merging data warehouse and data lake. Whatever term you use or prefer… The integration process these days looks like the following:
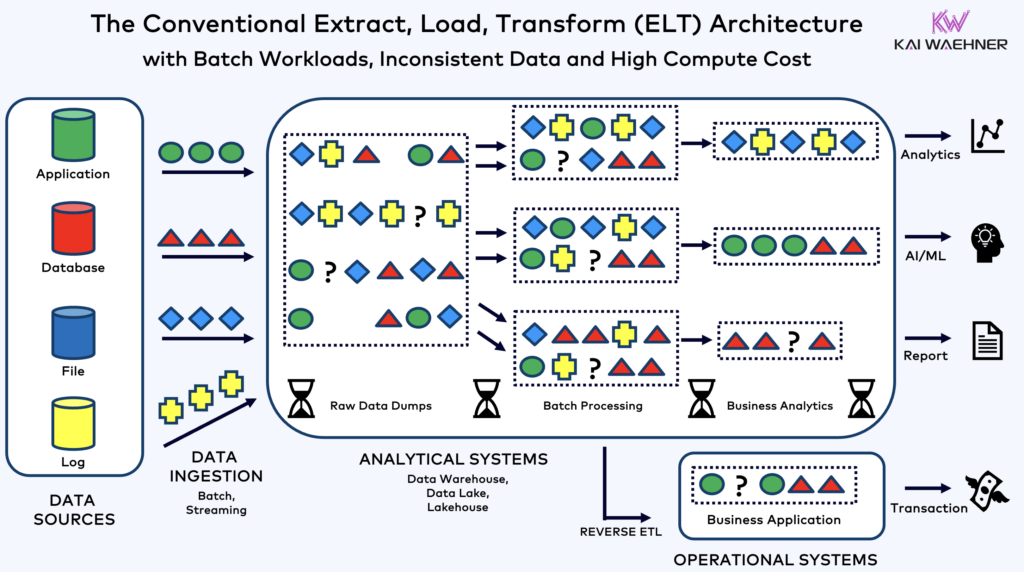
Just ingesting all the raw data into a data warehouse / data lake / lakehouse has several challenges:
- Slower Updates: The longer the data pipeline and the more tools are used, the slower the update of the data product.
- Longer Time-to-Market: Development efforts are repeated because each business unit needs to do the same or similar processing steps again instead of consuming from a curated data product.
- Increased Cost: The cash cow of analytics platforms charge is compute, not storage. The more your business units use DBT, the better for the analytics SaaS provider.
- Repeating Efforts: Most enterprises have multiple analytics platforms, including different data warehouses, data lakes, and AI platforms. ELT means doing the same processing again, again, and again.
- Data Inconsistency: Reverse ETL, Zero ETL, and other integration patterns make sure that your analytical and especially operational applications see inconsistent information. You cannot connect a real-time consumer or mobile app API to a batch layer and expect consistent results.
Data Integration, Zero ETL and Reverse ETL with Kafka, Snowflake, Databricks, BigQuery, etc.
These disadvantages are real! I have not met a single customer in the past months who disagreed and told me these challenges do not exist. To learn more, check out my blog series about data streaming with Apache Kafka and analytics with Snowflake:
- Snowflake Integration Patterns: Zero ETL and Reverse ETL vs. Apache Kafka
- Snowflake Data Integration Options for Apache Kafka (including Iceberg)
- Apache Kafka + Flink + Snowflake: Cost Efficient Analytics and Data Governance
The blog series can be applied to any other analytics engine. It is a worthwhile read, no matter if you use Snowflake, Databricks, Google BigQuery, or a combination of several analytics and AI platforms.
The solution for this data mess creating data inconsistency, outdated information, and ever-growing cost is the Shift Left Architecture…
Shift Left to Data Streaming for Operational AND Analytical Data Products
The Shift Left Architecture enables consistent information from reliable, scalable data products, reduces the compute cost, and allows much faster time-to-market for operational and analytical applications with any kind of technology (Java, Python, iPaaS, Lakehouse, SaaS, “you-name-it”) and communication paradigm (real-time, batch, request-response API):
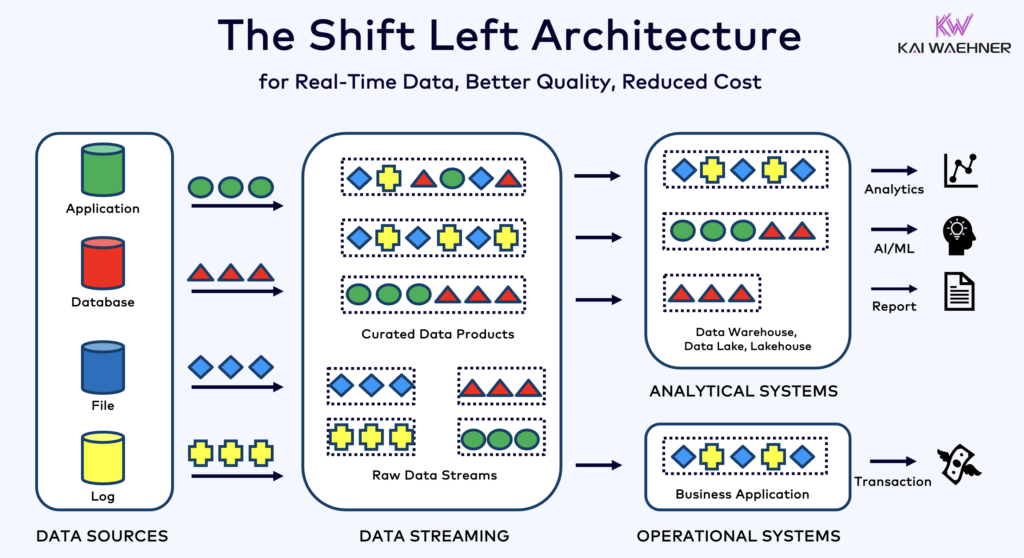
Shifting the data processing to the data streaming platform enables:
- Capture and stream data continuously when the event is created
- Create data contracts for downstream compatibility and promotion of trust with any application or analytics / AI platform
- Continuously cleanse, curate and quality check data upstream with data contracts and policy enforcement
- Shape data into multiple contexts on-the-fly to maximize reusability (and still allow downstream consumers to choose between raw and curated data products)
- Build trustworthy data products that are instantly valuable, reusable and consistent for any transactional and analytical consumer (no matter if consumed in real-time or later via batch or request-response API)
While shifting to the left with some workloads, it is crucial to understand that developers/data engineers/data scientists can usually still use their favourite interface like SQL or a programming language such as Java or Python.
Shift Left Architecture with Apache Kafka, Flink and Iceberg
Data Streaming is the core fundament of the Shift Left Architecture to enable reliable, scalable real-time data products with good data quality. The following architecture shows how Apache Kafka and Flink connect any data source, curate data sets (aka stream processing / Streaming ETL) and share the processed events with any operational or analytical data sink:
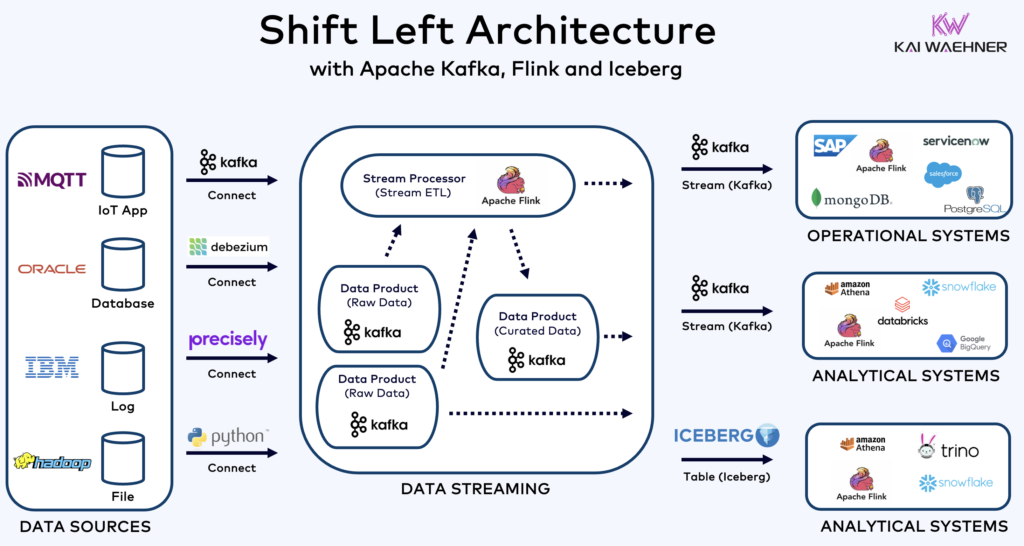
The architecture shows an Apache Iceberg table as alternative consumer. Apache Iceberg is an open table format designed for managing large-scale datasets in a highly performant and reliable way, providing ACID transactions, schema evolution, and partitioning capabilities. It optimizes data storage and query performance, making it ideal for data lakes and complex analytical workflows. Iceberg evolves to the de facto standard with support from most major vendors in the cloud and data management space, including AWS, Azure, GCP, Snowflake, Confluent, and many more coming (like Databricks after its acquisition of Tabular).
From the data streaming perspective, the Iceberg table is just a button click away from the Kafka Topic and its Schema (using Confluent’s Tableflow – I am sure other vendors will follow soon with own solutions). The big advantage of Iceberg is that data needs to be stored only once (typically in a cost-efficient and scalable object store like Amazon S3). Each downstream application can consume the data with its own technology without any need for additional coding or connectors. This includes data lakehouses like Snowflake or Databricks AND data streaming engines like Apache Flink.
Video: Shift Left Architecture
I summarized the above architectures and examples for the Shift Left Architecture in a short ten minute video if you prefer listening to content:

By loading the video, you agree to YouTube’s privacy policy.
Learn more
Apache Iceberg – The New De Facto Standard for Lakehouse Table Format?
Apache Iceberg is such a huge topic and a real game changer for enterprise architectures, end users and cloud vendors. I will write another dedicated blog, including interesting topics such as:
- Confluent’s product strategy to embed Iceberg tables into its data streaming platform
- Snowflake’s open source Iceberg project Polaris
- Databricks’ acquisition of Tabular (the company behind Apache Iceberg) and the relation to Delta Lake and open sourcing its Unity Catalog
- The (expected) future of table format standardization, catalog wars, and other additional solutions like Apache Hudi or Apache XTable for omni-directional interoperability across lakehouse table formats.
Stay tuned and subscribe to my newsletter to receive new articles.
Business Value of the Shift Left Architecture
Apache Kafka is the de facto standard for data streaming building a Kappa Architecture. The Data Streaming Landscape shows various open source technologies and cloud vendors. Data Streaming is a new software category. Forrester published “The Forrester Wave™: Streaming Data Platforms, Q4 2023“. The leaders are Microsoft, Google and Confluent, followed by Oracle, Amazon, Cloudera, and a few others.
Building data products more left in the enterprise architecture with a data streaming platform and technologies such as Kafka and Flink creates huge business value:
- Cost Reduction: Reducing the compute cost in one or even multiple data platforms (data lake, data warehouse, lakehouse, AI platform, etc.).
- Less Development Effort: Streaming ETL, data curation and data quality control already executed instantly (and only once) after the event creation.
- Faster Time to Market: Focus on new business logic instead of doing repeated ETL jobs.
- Flexibility: Best of breed approach for choosing the best and/or most cost-efficient technology per use case.
- Innovation: Business units can choose any programming language, tool or SaaS to do real-time or batch consumption from data products to try and fail or scale fast.
The unification of transactional and analytical workloads is finally possible to enable good data quality, faster time to market for innovation and reduced cost of the entire data pipeline. Data consistency matters across all applications and databases… A Kafka Topic with a data contract (= Schema with policies) brings data consistency out of the box!
How does your data architecture look like today? Does the Shift Left Architecture make sense to you? What is your strategy to get there? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.






