Organizations start their data streaming adoption with a single Apache Kafka cluster to deploy the first use cases. The need for group-wide data governance and security but different SLAs, latency, and infrastructure requirements introduce new Kafka clusters. Multiple Kafka clusters are the norm, not an exception. Use cases include hybrid integration, aggregation, migration, and disaster recovery. This blog post explores real-world success stories and cluster strategies for different Kafka deployments across industries.

Apache Kafka – The De Facto Standard for Event-Driven Architectures and Data Streaming
Apache Kafka is an open-source, distributed event streaming platform designed for high-throughput, low-latency data processing. It allows you to publish, subscribe to, store, and process streams of records in real time.
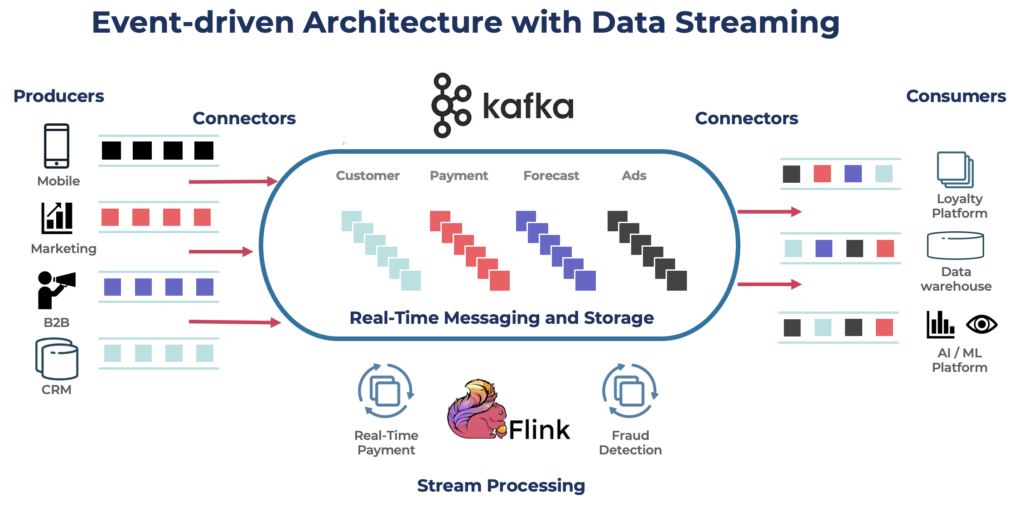
Kafka serves as a popular choice for building real-time data pipelines and streaming applications. The Kafka protocol became the de facto standard for event streaming across various frameworks, solutions, and cloud services. It supports operational and analytical workloads with features like persistent storage, scalability, and fault tolerance. Kafka includes components like Kafka Connect for integration and Kafka Streams for stream processing, making it a versatile tool for various data-driven use cases.
While Kafka is famous for real-time use cases, many projects leverage the data streaming platform for data consistency across the entire enterprise architecture, including databases, data lakes, legacy systems, Open APIs, and cloud-native applications.
Different Apache Kafka Cluster Types
Kafka is a distributed system. A production setup usually requires at least four brokers. Hence, most people automatically assume that all you need is a single distributed cluster you scale up when you add throughput and use cases. This is not wrong in the beginning. But…
One Kafka cluster is NOT the right answer for every use case. Various characteristics influence the architecture of a Kafka cluster:
- Availability: Zero downtime? 99.99% uptime SLA? Non-critical analytics?
- Latency: End-to-end processing in <100ms (including processing)? 10-minute end-to-end data warehouse pipeline? Time travel for re-processing historical events?
- Cost: Value vs. cost? Total Cost of Ownership (TCO) matters! For instance, in the public cloud, networking can be up to 80% of the total Kafka cost!
- Security and Data Privacy: Data privacy (PCI data, GDPR, etc.)? Data governance and compliance? End-to-end encryption on the attribute level? Bring your own key? Public access and data sharing? Air-gapped edge environment?
- Throughput and Data Size: Critical transactions (typically low volume)? Big data feeds (clickstream, IoT sensors, security logs, etc.)?
Related topics like on-premise vs. public cloud, regional vs. global, and many other requirements also affect the Kafka architecture.
Apache Kafka Cluster Strategies and Architectures
A single Kafka cluster is often the right starting point for your data streaming journey. It can onboard multiple use cases from different business domains and process gigabytes per second (if operated and scaled the right way). However, depending on your project requirements, you need an enterprise architecture with multiple Kafka clusters. Here are a few common examples:
- Hybrid Architecture: Data integration and uni- or bi-directional data synchronization between multiple data centers. Often, connectivity between an on-premise data center and a public cloud service provider. Offloading from legacy into cloud analytics is one of the most common scenarios. But command & control communication is also possible, i.e., sending decisions/recommendations/transactions into a regional environment (e.g., storing a payment or order from a mobile app in the mainframe).
- Multi-Region / Multi-Cloud: Data replication for compliance, cost, or data privacy reasons. Data sharing usually only includes a fraction of the events, not all Kafka Topics. Healthcare is one of many industries that goes this direction.
- Disaster Recovery: Replication of critical data in active-active or active-passive mode between different data centers or cloud regions. Includes strategies and tooling for fail-over and fallback mechanisms in the case of a disaster to guarantee business continuity and compliance.
- Aggregation: Regional clusters for local processing (e.g., pre-processing, streaming ETL, stream processing business applications) and replication of curated data to the big data center or cloud. Retail stores are an excellent example.
- Migration: IT modernization with a migration from on-premise into the cloud or from self-managed open source into a fully managed SaaS. Such migrations can be done with zero downtime or data loss while the business continues during the cut-over.
- Edge (Disconnected / Air-Gapped): Security, cost, or latency require edge deployments, e.g. in a factory or retail store. Some industries deploy in safety-critical environments with unidirectional hardware gateway and data diode.
- Single Broker: Not resilient, but sufficient for scenarios like embedding a Kafka broker into a machine or on an Industrial PC (IPC) and replicating aggregated data into a large cloud analytics Kafka cluster. One nice example is the installation of data streaming (including integration and processing) on a computer of a soldier on the battlefield.
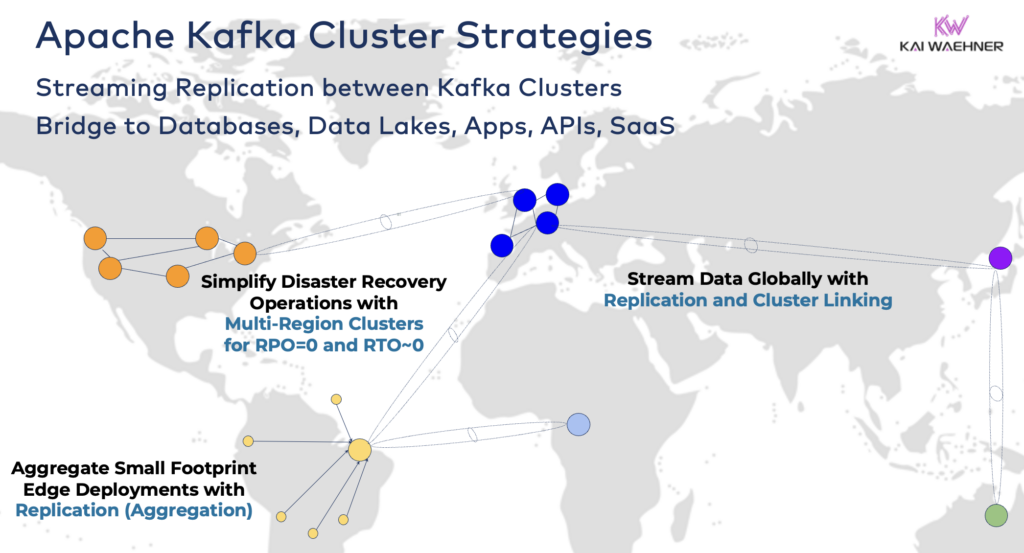
Bridging Hybrid Kafka Clusters
These options can be combined. For instance, a single broker at the edge typically replicates some curated data to a remote data center. And hybrid clusters have such different architectures depending on how they are bridged: connections over public internet, private link, VPC peering, and transit gateway, etc.
Having seen the development of Confluent Cloud over the years, I totally underestimated how much engineering time needs to be spent on security and connectivity. However, missing security bridges are the main blocker for the adoption of a Kafka cloud service. So, there is no way around providing various security bridges between Kafka clusters beyond just public internet.
There are even use cases where organizations need to replicate data from the data center to the cloud but the cloud service is NOT allowed to initiative the connection. Confluent built a specific feature “source-initiated link” for such security requirements where the source (i.e., the on-premise Kafka cluster) always initiates the connection – even though the cloud Kafka clusters is consuming the data:
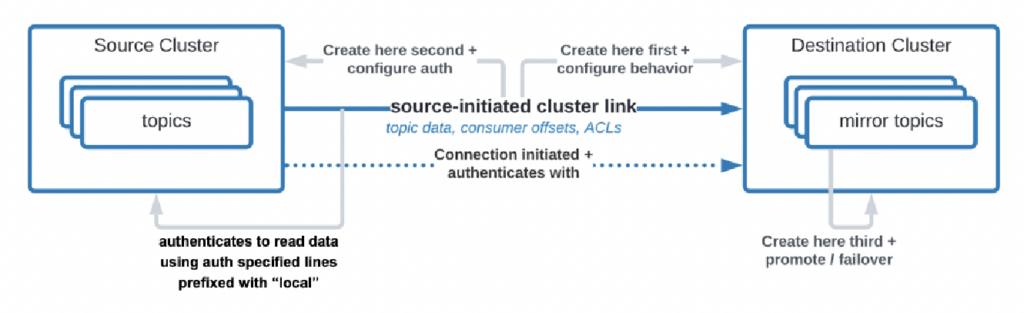
As you see, it gets complex quickly. Find the right experts to help you from the beginning; not after you already deployed the first clusters and applications.
A long time ago, I already described in a detailed presentation of the architecture patterns for distributed, hybrid, edge, and global Apache Kafka deployments. Look at that slide deck and video recording for more details about the deployment options and trade-offs.
RPO vs. RTO = Data Loss vs. Downtime
RPO and RTO are two critical KPIs you need to discuss before deciding for a Kafka cluster strategy:
- RPO (Recovery Point Objective) is the maximum acceptable amount of data loss measured in time, indicating how frequently backups should occur to minimize data loss.
- RTO (Recovery Time Objective) is the maximum acceptable duration of time it takes to restore business operations after a disruption. Together, they help organizations plan their data backup and disaster recovery strategies to balance cost and operational impact.
While people often start with the goal of RPO = 0 and RTO = 0, they quickly realize how hard (but not impossible) it is to get this. You need to decide how much data are you okay to lose in a disaster? You need a disaster recovery plan if disaster strikes. The legal and compliance teams will have to tell you if it is okay to lose a few data sets in case of disaster or not. These any many other challenges need to be discussed when evaluating your Kafka cluster strategy.
The replication between Kafka clusters with tools like MIrrorMaker or Cluster Linking is asynchronous and RPO > 0. Only a stretched Kafka cluster provides RPO = 0.
Stretched Kafka Cluster – Zero Data Loss with Synchronous Replication across Data Centers
Most deployments with multiple Kafka clusters use asynchronous replication across data centers or clouds via tools like MirrorMaker or Confluent Cluster Linking. This is good enough for most use cases. But in case of a disaster, you lose a few messages. The RPO is > 0.
A stretched Kafka cluster deploys Kafka brokers of ONE SINGLE CLUSTER across three data centers. The replication is synchronous (as this is how Kafka replicates data within one cluster) and guarantees zero data loss (RPO = 0) – even in the case of a disaster!
Why shouldn’t you always do stretched clusters?
- Low latency (<~50ms) and stable connection required between data centers
- Three (!) data centers are needed, two is not enough as a majority (quorum) must acknowledge writes and reads to ensure the system’s reliability
- Hard to set up, operate, and monitor – much harder than a cluster running in one data center
- Cost vs. value is not worth it in many use cases – during a real disaster, most organizations and use cases have bigger problems than losing a few messages (even if it is critical data like a payment or order).
To be clear: In the public cloud, a region usually has three data centers (= availability zones). Hence, in the cloud, it depends on your SLAs if one cloud region counts as a stretched cluster or not. Most SaaS Kafka offerings deploy in a stretched cluster here. However, many compliance scenarios do NOT see a Kafka cluster in one cloud region as good enough for guaranteeing SLAs and business continuity if a disaster strikes.
Confluent built a dedicated product to solve (some of) these challenges: Multi-Region Clusters (MRC). It provides capabilities to do synchronous and asynchrounous replication within a stretched Kafka cluster.
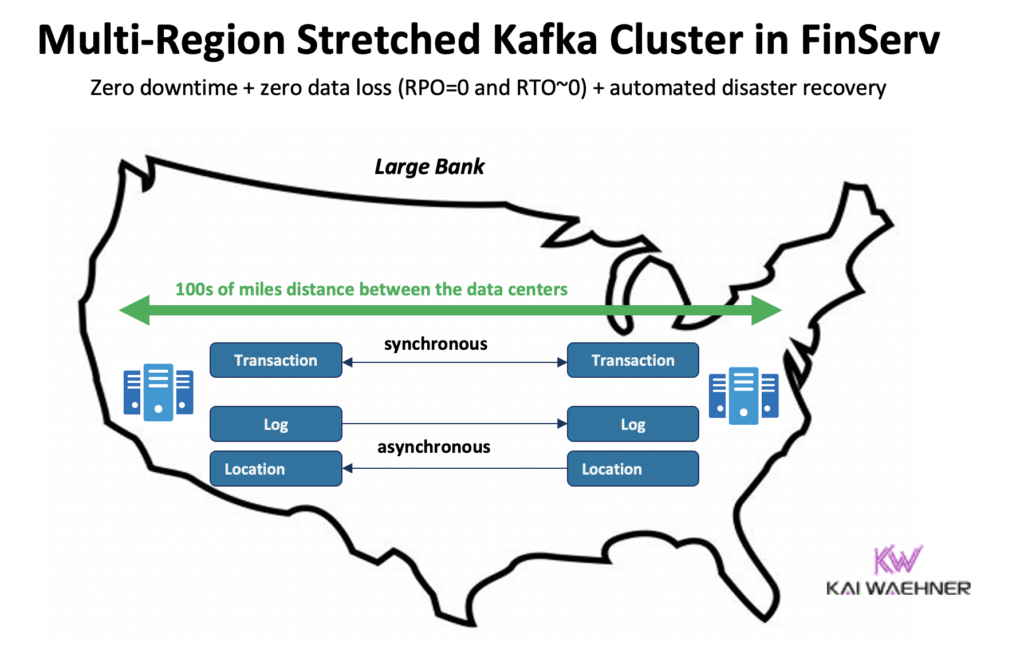
For example, in a financial services scenario, MRC replicates low-volume critical transactions synchronously, but high-volume logs asynchronously:
- handles ‘Payment’ transactions enter from us-east and us-west with fully synchronous replication
- ‘Log’ and ‘Location’ information in the same cluster use async – optimized for latency
- Automated disaster recovery (zero downtime, zero data loss)
More details about stretched Kafka clusters vs. active-active / active-passive replication between two Kafka clusters in my global Kafka presentation.
Pricing of Kafka Cloud Offerings (vs. Self-Managed)
The above sections explain why you need to consider different Kafka architectures depending on your project requirements. Self-managed Kafka clusters can be configured the way you need. In the public cloud, fully managed offerings look different (the same way as any other fully managed SaaS). Pricing is different because SaaS vendors need to configure reasonable limits. The vendor has to provide specific SLAs.
The data streaming landscape includes various Kafka cloud offerings. Here is an example of Confluent’s current cloud offerings, including multi-tenant and dedicated environments with different SLAs, security features, and cost models.
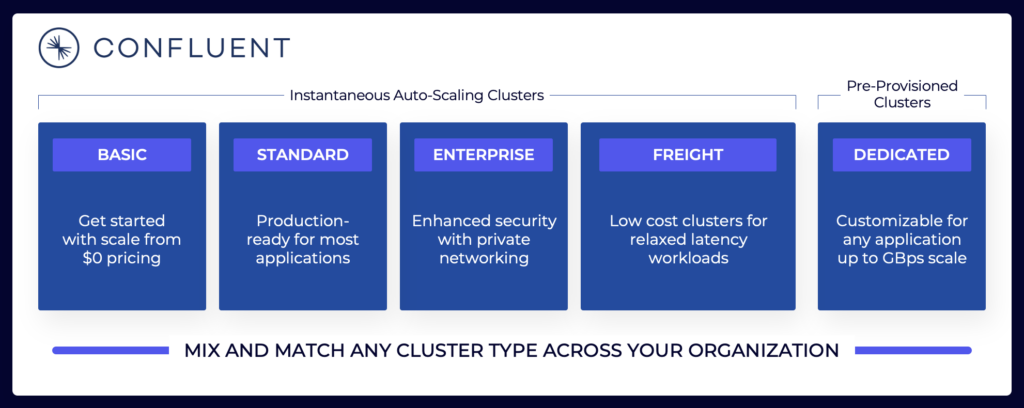
Make sure to evaluate and understand the various cluster types from different vendors available in the public cloud, including TCO, provided uptime SLAs, replication costs across regions or cloud providers, and so on. The gaps and limitations are often intentionally hidden in the details.
For instance, if you use Amazon Managed Streaming for Apache Kafka (MSK), you should be aware that the terms and conditions tell you that “The service commitment does not apply to any unavailability, suspension or termination … caused by the underlying Apache Kafka or Apache Zookeeper engine software that leads to request failures”.
But pricing and support SLAs are just one critical piece of such a comparison. There are lots of “build vs. buy” decisions you have to make as part of evaluating a data streaming platform, as I pointed out in my detailed article comparing Confluent to Amazon MSK Serverless.
Kafka Storage – Tiered Storage and Iceberg Table Format to Store Data Only Once
Apache Kafka added Tiered Storage to separate compute and storage. The capability enables more scalable, reliable, and cost-efficient enterprise architectures. Tiered Storage for Kafka enables a new Kafka cluster type: Storing Petabytes of data in the Kafka commit log in a cost-efficient way (like in your data lake) with timestamps and guaranteed ordering to travel back in time for re-processing historical data. KOR Financial is a nice example of using Apache Kafka as a database for long-term persistence.
Kafka enables a Shift Left Architecture to store data only once for operational and analytical datasets:
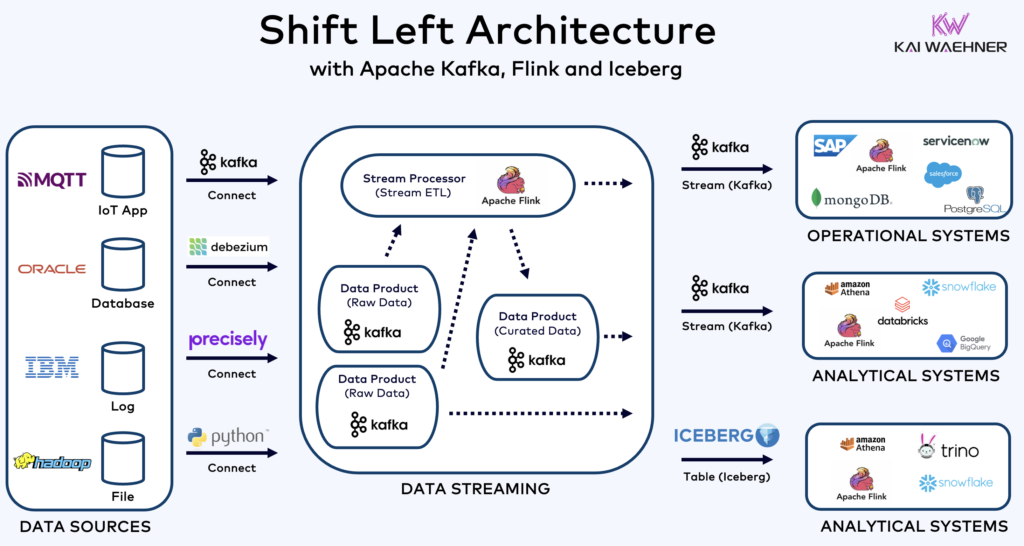
With this in mind, think again about the use cases I described above for multiple Kafka clusters. Should you still replicate data in batch at rest in the database, data lake, or lakehouse from one data center or cloud region to another? No. You should synchronize data in real-time, store the data once (usually in an object store like Amazon S3), and then connect all analytical engines like Snowflake, Databricks, Amazon Athena, Google Cloud BigQuery, and so on to this standard table format.
Learn more about the unification of operational and analytical data in my article “Apache Iceberg – The Open Table Format for Lakehouse AND Data Streaming“.
Real-World Success Stories for Multiple Kafka Clusters
Most organizations have multiple Kafka clusters. This section explores four success stories across different industries:
- Paypal (Financial Services) – US: Instant payments, fraud prevention.
- JioCinema (Telco/Media) – APAC: Data integration, clickstream analytics, advertisement, personalization.
- Audi (Automotive/Manufacturing) – EMEA: Connected cars with critical and analytical requirements.
- New Relic (Software/Cloud) – US: Observability and application performance management (APM) across the world.
Paypal – Separation by Security Zone
PayPal is a digital payment platform that allows users to send and receive money online securely and conveniently around the world in real time. This requires a scalable, secure and compliant Kafka infrastructure.
During the 2022 Black Friday, Kafka traffic volume peaked at about 1.3 trillion messages daily! At present, PayPal has 85+ Kafka clusters, and every holiday season they flex up their Kafka infrastructure to handle the traffic surge. The Kafka platform continues to seamlessly scale to support this traffic growth without any impact on their business.
Today, PayPal’s Kafka fleet consists of over 1,500 brokers that host over 20,000 topics. The events are replicated among the clusters, offering 99.99% availability.
Kafka cluster deployments are separated into different security zones within a data center:
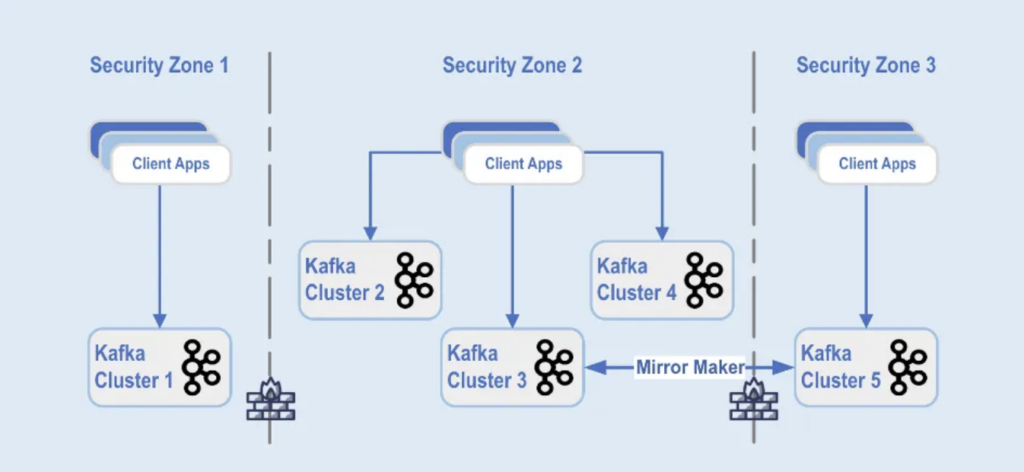
The Kafka clusters are deployed across these security zones, based on data classification and business requirements. Real-time replication with tools such as MirrorMaker (in this example, running on Kafka Connect infrastructure) or Confluent Cluster Linking (using a simpler and less error-prone approach directly using the Kafka protocol for replication) is used to mirror the data across the data centers, which helps with disaster recovery and to achieve inter-security zone communication.
JioCinema – Separation by Use Case and SLA
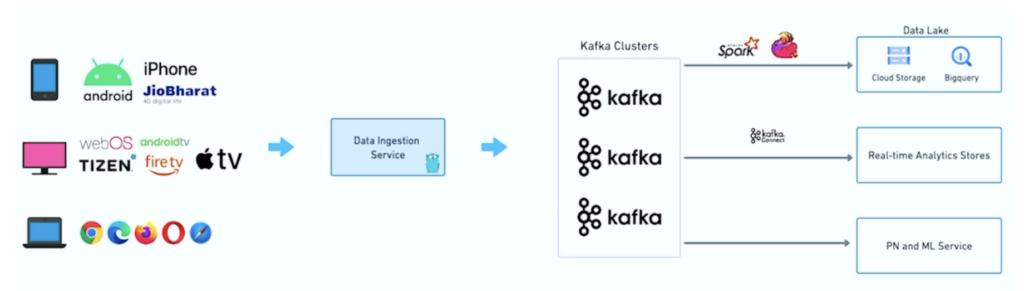
- Inter Service Communication
- Clickstream / Analytics
- Ad Tracker
- Machine Learning and Personalization
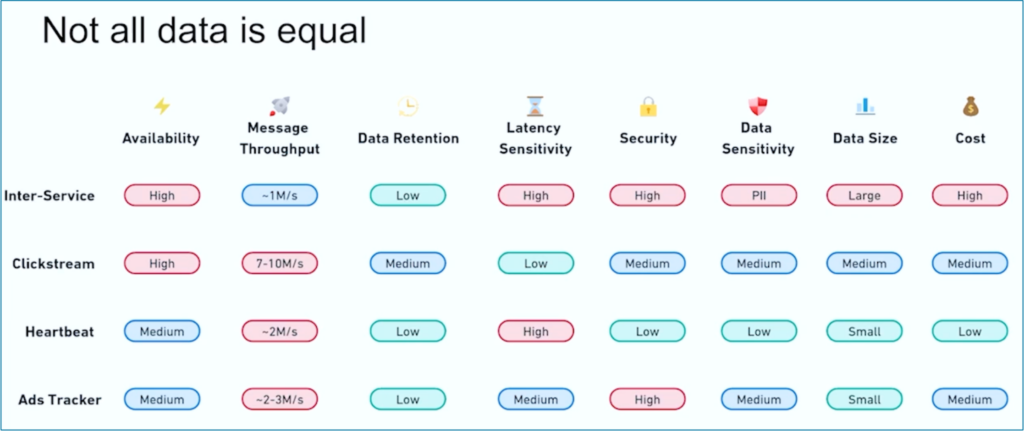
Kushal Khandelwal, Head of Data Platform, Analytics, and Consumption at JioCinema, explained that not all data is equal and the priorities and SLAs differ per use case:
Data streaming is a journey. Like so many other organizations worldwide, JioCinema started with one large Kafka cluster using 1000+ Kafka Topics and 100,000+ Kafka Partitions for various use cases. Over time, a separation of concerns regarding use cases and SLAs developed into multiple Kafka clusters:
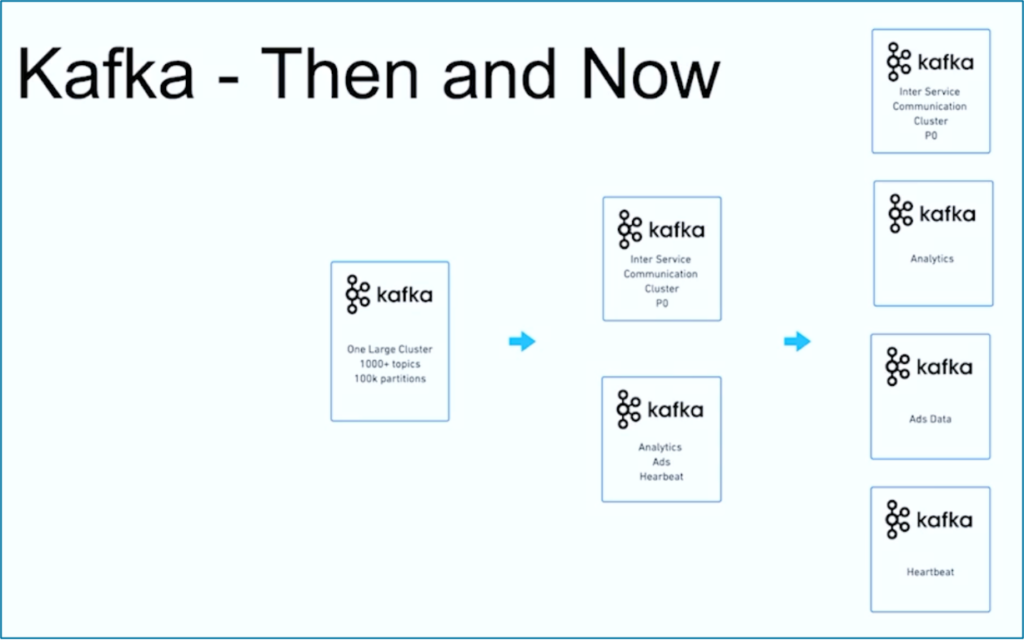
The success story of JioCinema shows the common evolution of a data streaming organization. Let’s now explore another example where two very different Kafka clusters were deployed from the beginning for one use case.
Audi – Operations vs. Analytics for Connected Cars
The car manufacturer Audi provides connected cars featuring advanced technology that integrates internet connectivity and intelligent systems. Audi’s cars enable real-time navigation, remote diagnostics, and enhanced in-car entertainment. These vehicles are equipped with Audi Connect services. Features include emergency calls, online traffic information, and integration with smart home devices, to enhance convenience and safety for drivers.
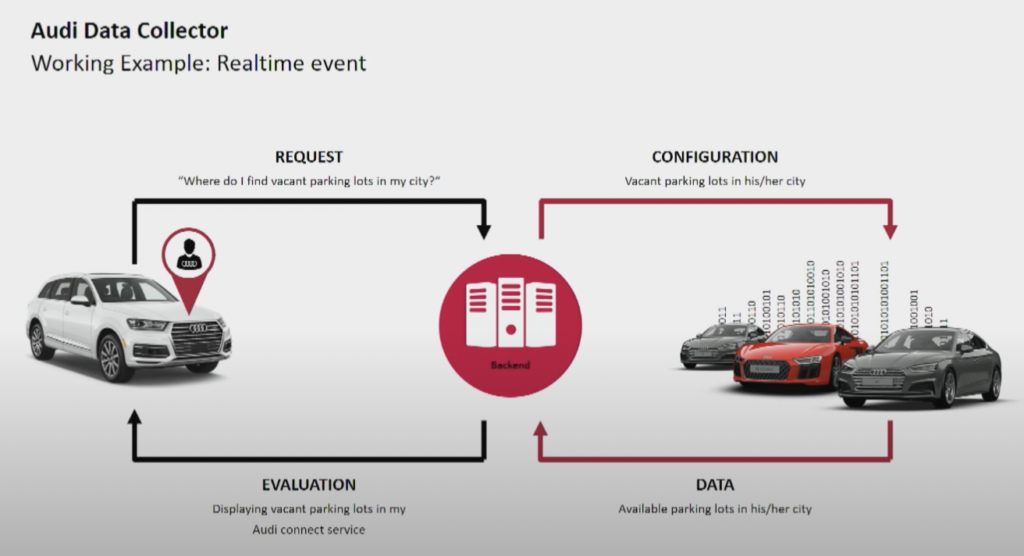
Audi presented their connected car architecture in the keynote of Kafka Summit in 2018. The Audi enterprise architecture relies on two Kafka clusters with very different SLAs and use cases.
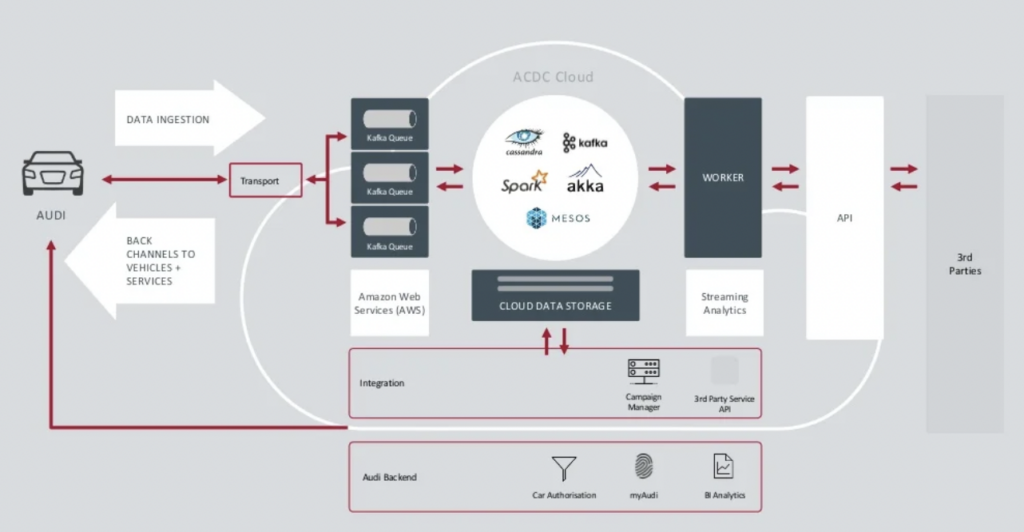
The Data Ingestion Kafka cluster is very critical. It needs to run 24/7 at scale. It provides last-mile connectivity to millions of cars using Kafka and MQTT. Backchannels from the IT side to the vehicle help with service communication and over-the-air updates (OTA).
ACDC Cloud is the analytics Kafka cluster of Audi’s connected car architecture. The cluster is the foundation of many analytical workloads. These process enormous volumes of IoT and log data at scale with batch processing frameworks, like Apache Spark.
This architecture was already presented in 2018. Audi’s slogan “Progress through Technology” shows how the company applied new technology for innovation long before most car manufacturers deployed similar scenarios. All sensor data from the connected cars is processed in real time and stored for historical analysis and reporting.
New Relic – Worldwide Multi-Cloud Observability
New Relic is a cloud-based observability platform that provides real-time performance monitoring and analytics for applications and infrastructure to customers around the world.
Andrew Hartnett, VP of Software Engineering, at New Relic explains how data streaming is crucial for the entire business model of New Relic:
“Kafka is our central nervous system. It is a part of everything that we do. Most services across 110 different engineering teams with hundreds of services touch Kafka in some way, shape, or form in our company, so it really is mission-critical. What we were looking for is the ability to grow, and Confluent Cloud provided that.”
“New Relic is multi-cloud. We want to be where our customers are. We want to be in those same environments, in those same regions, and we wanted to have our Kafka there with us.” says Artnett in a Confluent case study.
Multiple Kafka Clusters are the Norm; Not an Exception!
Event-driven architectures and stream processing have existed for decades. The adoption grows with open source frameworks like Apache Kafka and Flink in combination with fully managed cloud services. More and more organizations struggle with their Kafka scale. Enterprise-wide data governance, center of excellence, automation of deployment and operations, and enterprise architecture best practices help to successfully provide data streaming with multiple Kafka clusters for independent or collaborating business domains.
Multiple Kafka clusters are the norm, not an exception. Use cases such as hybrid integration, disaster recovery, migration or aggregation enable real-time data streaming everywhere with the needed SLAs.
How does your enterprise architecture look like? How many Kafka clusters do you have? And how do you decide about data governance, separation of concerns, multi-tenancy, security, and similar challenges in your data streaming organization? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.