Multiple Apache Kafka clusters are the norm; not an exception anymore. Hybrid integration and multi-cloud replication for migration or disaster recovery are common use cases. This blog post explores a real-world success story from financial services around the transition of a large traditional bank from on-premise data centers into the public cloud for multi-cloud data sharing between AWS and Azure.
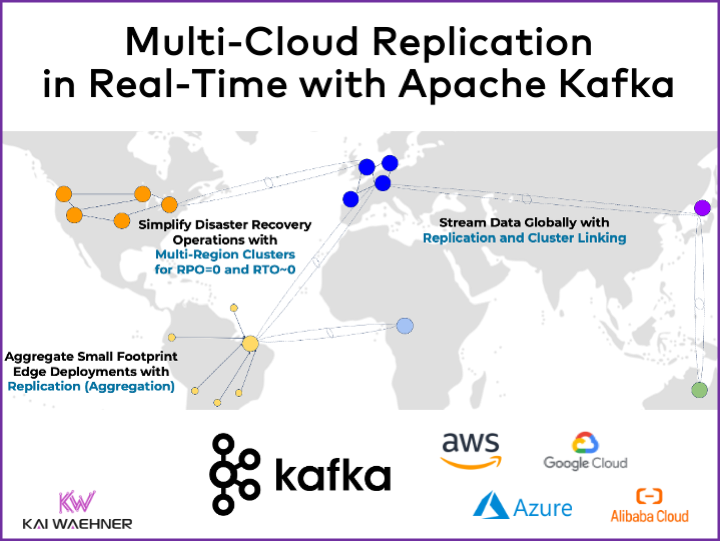
What is Multi-Cloud and How Does Apache Kafka Help?
Multi-cloud refers to the use of multiple cloud computing services from different providers in a single heterogeneous IT environment. This approach enhances flexibility, performance, and reliability while avoiding vendor lock-in.
Here are the key benefits of multi-cloud:
- Avoidance of Vendor Lock-In: By utilizing multiple cloud providers, organizations can avoid dependency on a single vendor, reducing the risk associated with vendor-specific outages and price changes.
- Optimization of Performance and Cost: Different cloud providers offer varying strengths, pricing models, and geographic availability. Multi-cloud strategies enable organizations to choose the best provider for each workload to optimize performance and cost.
- Enhanced Redundancy and Resilience: Multi-cloud setups can provide higher availability and disaster recovery capabilities by distributing workloads across multiple cloud environments, thus reducing the impact of localized outages.
- Regulatory and Compliance Benefits: Some industries and regions have specific regulatory requirements that may be easier to meet using a multi-cloud approach, ensuring data residency and compliance.
The real-time capabilities of Apache Kafka are a perfect match for multi-cloud architectures. Information is replicated and synchronized directly after the creation of an event. Apache Kafka’s combination of high throughput, low latency, durability provides strong data consistency guarantees across multiple cloud providers like AWS, Azure, GCP and Alibaba; no matter if the data sources or data sinks are real time, batch or API-driven request
One Apache Kafka Cluster Does NOT Fit All Use Cases
Organizations require multiple Kafka cluster strategies for various use cases: Hybrid integration, aggregation, migration and disaster recovery. I explored the architecture options and trade-offs in a dedicated blog post: “Apache Kafka Cluster Type Deployment Strategies“.

Multi-cloud is a special case with even higher challenges regarding security, cost, and latency. Nevertheless, all larger organizations have multi-cloud infrastructure and integration needs. Let’s explore the multi-cloud journey of fidelity investments and how data streaming with Apache Kafka helps.
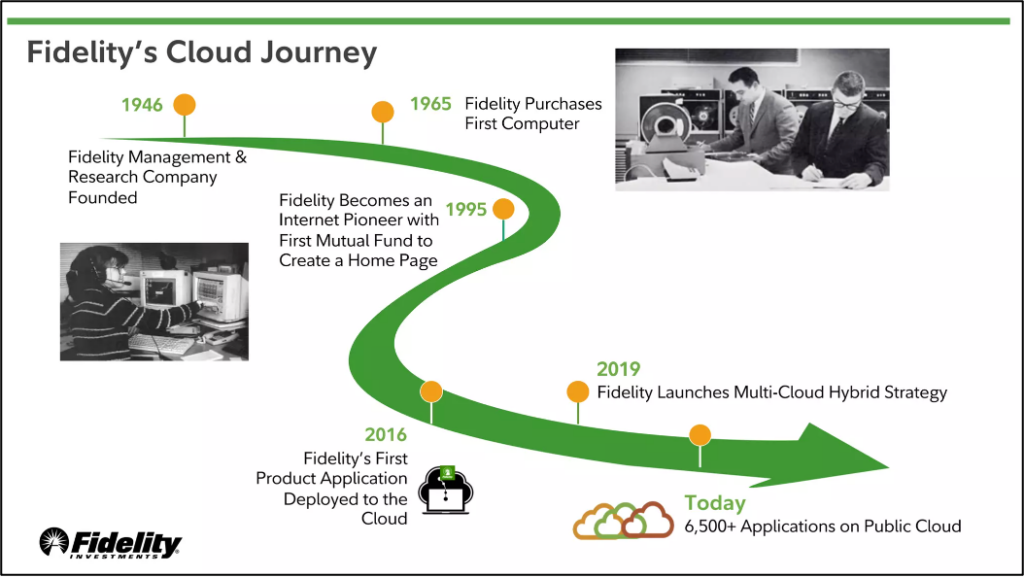
Fidelity’s Hybrid Cloud Data Streaming Journey
Fidelity Investments is a leading financial services company that provides a wide range of investment management, retirement planning, brokerage, and wealth management services to individuals and institutions. Founded in 1946, Fidelity has grown to become one of the largest asset managers in the world, with trillions of dollars in assets under management. The company is known for its comprehensive research tools, innovative technology platforms, and commitment to customer service, helping clients achieve their financial goals.
Fidelity Investments presented at Kafka Summit events about their data streaming journey transitioning from on-premise to hybrid cloud infrastructure.
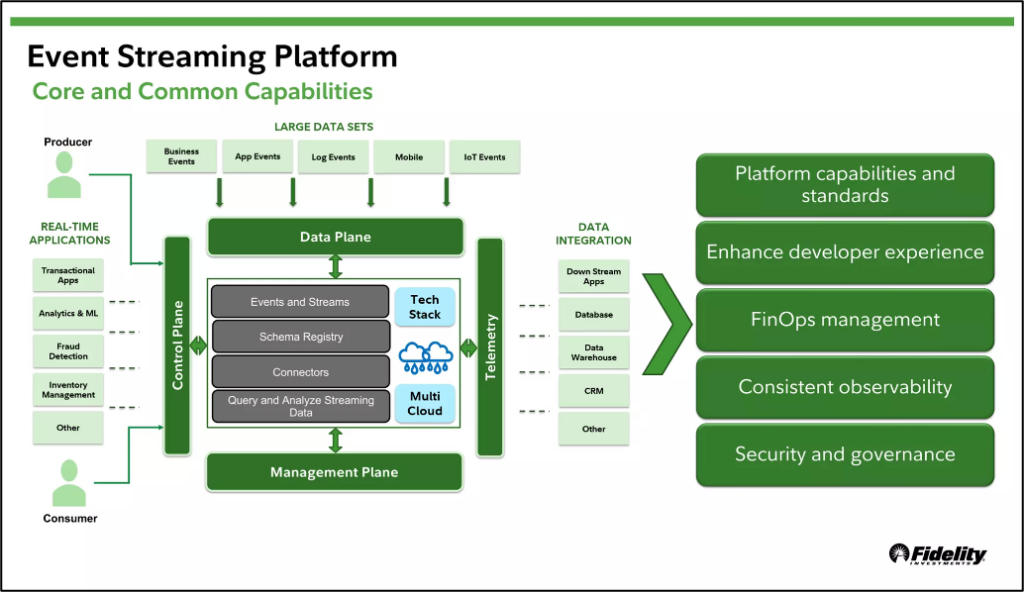
Fidelity’s Event Streaming Platform
Fidelity Investments built a streaming platform that hosts business application events for event driven architectures and integration with other business applications through events and streams.
A few impressive numbers about from Fidelity’s event streaming platform infrastructure (presented at Kafka Summit London in 2023):
- 4 years in public cloud
- 16k+ producer and consumer applications
- 6B+ events per day
- 72+ self-service APIs
- 300+ observability metrics
One of the first critical use cases was the integration and offloading from IBM z Systems mainframe via IBM MQ, Kafka Connect (deployed on the mainframe) and Confluent Platform.
For architectures and best practices around mainframe modernization, check out my article “Mainframe Integration, Offloading and Replacement with Apache Kafka“.
Fidelity’s Cloud Journey: From Point-to-Point to Decoupling Applications with Kafka and Cluster Linking between AWS and Azure
The Kafka Summit talk “Multi-Cloud Data Sharing: Make the Data Move for you Across CSPs using Cluster Linking” explored Fidelity Investment’s transition to the cloud.
Fidelity Investments designed its multi-cloud event streaming platform to enable applications residing in different cloud service providers to seamlessly share data between them.
BEFORE: Point-to-Point Multi-Cloud Replication
Many architects call this the spaghetti integration architecture. All applications do a point-to-point connection to each other application:
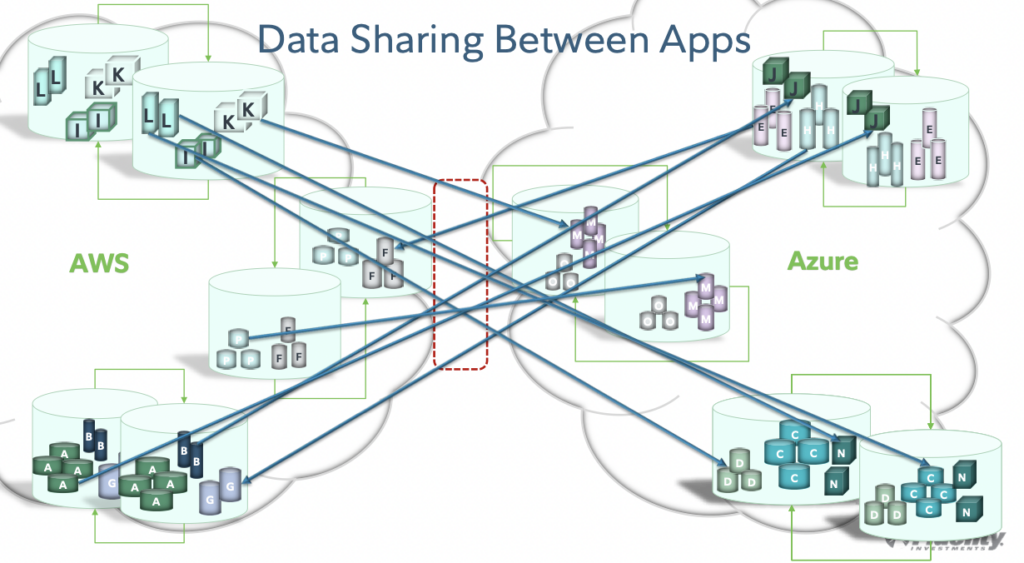
This setup is costly, error-prone and hard to maintain or innovate.
AFTER: Apache Kafka and Cluster Linking for Real-Time Data Sharing and Decoupled Applications
One of Apache Kafka’s unique values is truly decoupling between applications. The event-based durable commit log guarantees data consistency but also allows choosing the right technology or API in each business unit.
Replication between the Kafka clusters running in different cloud infrastructures and regions on AWS and Azure is implemented with Confluent Cluster Linking.
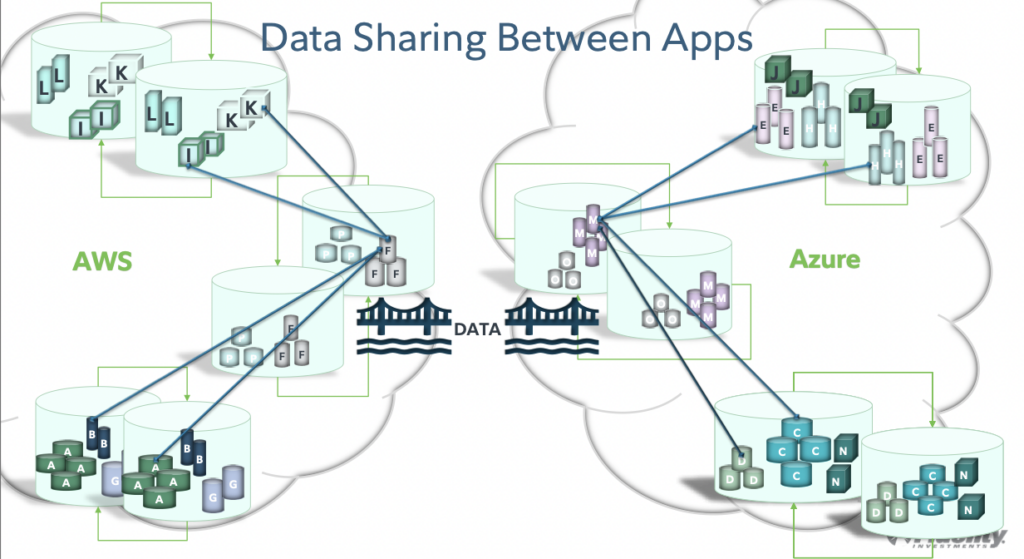
Confluent Cluster Linking plays a crucial role in this design for real-time replication between Kafka clusters. It uses the Kafka protocol for replication to provide all the benefits of Kafka and no needed infrastructure and operations overhead with tools like MirrorMaker. Using the Kafka protocol for multi-cloud replication also affects, i.e., reduces the network cost significantly because it avoids many translations and compression tasks required by MirrorMaker.
Fidelity’s Multi-Cloud Requirements: Data Ownership, Data Contracts and Self-Service API
Besides reliable real-time replication across multi-cloud environments, Fidelity Investments’ other important aspects include for the multi-cloud Kafka enterprise architecture include:
- Data ownership in a multi-cloud environment
- Schema Registry to provide common data contracts (often called data products in a data mesh architecture) across Kafka clusters in different cloud providers
- Self-service management API plane allowing teams to manage their multi-cloud topic replications with as little as a single configuration change.
Transition to Cloud with Data Streaming Across Industries
Multi-cloud use cases include data integration, migration, aggregation and disaster recovery scenarios. Here are a few real-world examples from the financial services, healthcare and telecom sector:
- Raiffeisen Bank International: A bank transformation across 12 countries
- Erste Bank: Data Streaming not because of real-time, but data consistency across hybrid cloud
- Bayer: Migration to hybrid multi-cloud data streaming
- British Telecom (BT): Hybrid multi-cloud data streaming architecture for proactive service management
Even if you do not plan multi-cloud infrastructure because focusing on a single service provider across regions, you can be sure: The next merger and acquisition (M&A) comes for sure… 🙂 Multi-cloud scenarios are not an exception, but the norm in larger organizations.
Do you already deploy across multiple cloud providers? What are the use cases? How do you efficiently and reliably integrate these environments? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.





