Data streaming is a new software category. It has grown from niche adoption to becoming a fundamental part of modern data architecture. With real-time data processing transforming industries, the ecosystem of tools, platforms, and services has evolved significantly. This blog post explores the data streaming landscape of 2025, analyzing key players, trends, and market dynamics shaping this space.
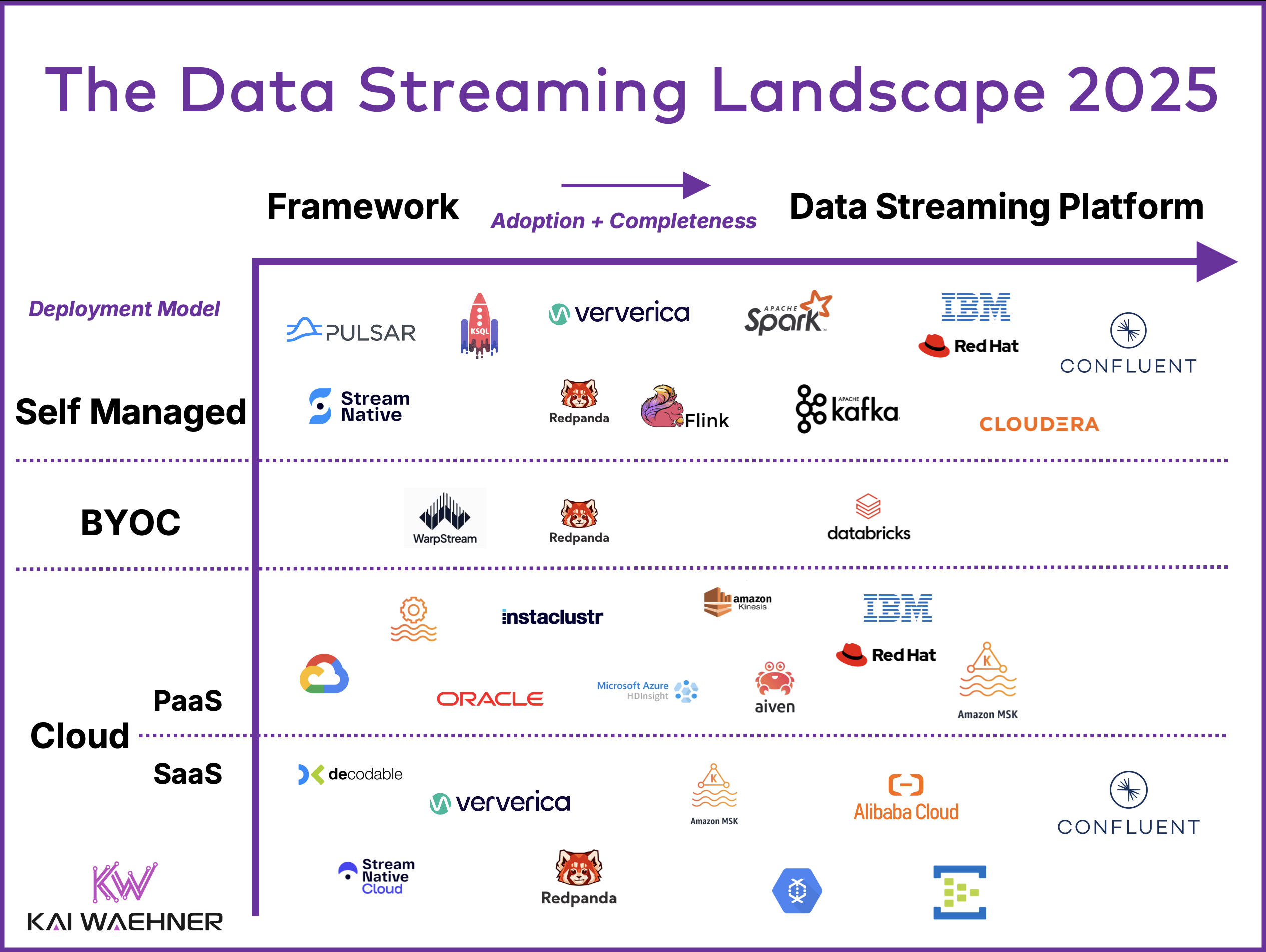
The data streaming landscape of 2025 categorizes solutions by their adoption and completeness as fully-featured data streaming platforms, as well as their deployment models, which range from self-managed setups to BYOC (Bring Your Own Cloud) and fully managed cloud services like PaaS and SaaS. While Apache Kafka remains the backbone of this ecosystem, the landscape also includes stream processing engines like Apache Flink and competitive technologies such as Pulsar and Redpanda that are built on the Kafka protocol.
This blog also explores the latest market trends and provides an outlook for 2025 and beyond, highlighting potential new entrants and evolving use cases. By the end, you’ll gain a clear understanding of the data streaming platform landscape and its trajectory in the years to come.
Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download by free ebook about data streaming use cases and industry-specific success stories.
Data Streaming in 2025: The Rise of a New Software Category
Real-time data beats slow data. That’s true across almost all use cases in any industry. Event-driven applications powered by data streaming continuously process data from any data source. This approach increases the business value as the overall goal by increasing revenue, reducing cost, reducing risk, or improving the customer experience. And the event-driven architecture ensures a future-ready architecture.
Even top researchers and advisory firms such as Forrester, Gartner, and IDG recognize data streaming as a new software category. In December 2023, Forrester released “The Forrester Wave™: Streaming Data Platforms, Q4 2023,” highlighting Microsoft, Google, and Confluent as leaders, followed by Oracle, Amazon, and Cloudera.
Data Streaming is NOT just another data integration tool. Plenty of software categories and related data platforms exist to process and analyze data. I explored in a few dedicated series how data streaming. differs:
- Data Warehouse vs. Data Lake vs. Data Streaming – Friends, Enemies, Frenemies?
- Data Streaming vs. ETL and Reverse ETL
- Data Streaming and Lakehouse(s) – A Match Made in Heaven
The Business Value of Data Streaming
A new software category opens use cases and adds business value across all industries:
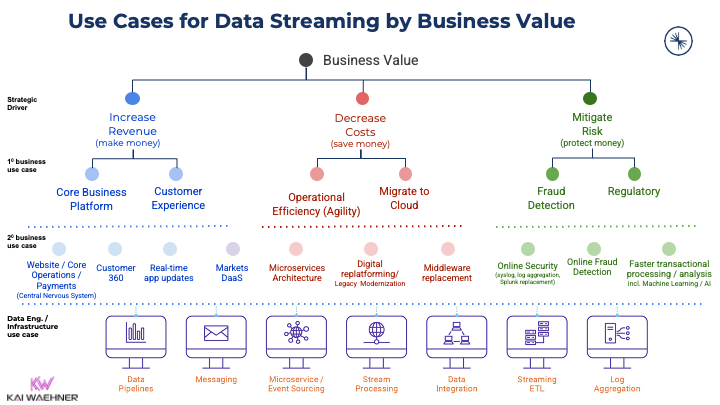
Adding business value is crucial for any enterprise. With so many potential use cases, it is no surprise that more and more software vendors add Kafka support to their products.
Search my blog for your favorite industry to find plenty of case studies and architectures. Or read about use cases for Apache Kafka across industries to get started.
The Data Streaming Landscape of 2025
Data Streaming is a separate software category of data platforms. Many software vendors built their entire businesses around this category. Several mature players in the data market added support for data streaming in their platforms or cloud service ecosystem. Various SaaS startups have emerged in this category in the last few years.
It all began with the open-source framework Apache Kafka, and today, the Kafka protocol is widely adopted across various implementations, including proprietary ones. What truly matters now is leveraging the capabilities of a complete data streaming platform—one that is fully compatible with the Kafka protocol. This includes built-in features like connectors, stream processing, security, data governance, and the elimination of self-management, reducing risks and operational effort.
The Kafka Protocol is the De Facto Standard of Data Streaming
Most software vendors use Kafka (or its protocol) at the core of their data streaming platforms. Apache Kafka has become the de facto standard for data streaming.

Additionally, “benchmarketing” (i.e., picking a sweet spot or niche scenario where you perform better than your competitor) is the favorite marketing technique to “prove” differentiators to the real Apache Kafka. Some vendors also present misleading cost-efficiency comparisons by excluding critical cloud costs such as data transfer or storage, giving an incomplete picture of the true expenses.
Apache Kafka vs. Data Streaming Platform
Many still use Kafka merely as a dumb ingestion pipeline, overlooking its potential to power sophisticated, real-time data streaming use cases. One reason is that Kafka alone lacks the full capabilities of a comprehensive data streaming platform.
A complete solution requires more than “just” Kafka. Apache Flink is becoming the de facto standard for stream processing. Data integration capabilities (connectors, clients, APIs), data governance, security, and critical 24/7 SLAs and support are important for many data streaming projects.
The Data Streaming Landscape 2025 summarizes the current status of relevant products and cloud services, focusing on deployment models and the adoption/completeness of the data streaming platforms.
Data Streaming Vendors and Categories for the 2025 Landscape
The data streaming landscape changed this year. As most solutions evolve, I do not distinguish anymore between Kafka, non-Kafka, and stream processing as categories. Instead, I look at the adoption and completeness to assess the maturity of a data streaming solution from an open-source framework to a complete platform.
The deployment models also changed in the 2025 landscape. Instead of categorizing it into Self Managed, Partially Managed, and Fully Managed, I sort as follows: Self Managed, Bring Your Own Cloud (BYOC), and Cloud. The Cloud category is separated into PaaS (Platform as a Service) and SaaS (Software as a Service) to indicate that many Kafka cloud offerings are still NOT fully managed!
Please note: Intentionally, this data streaming landscape is not a complete list of frameworks, cloud services, or vendors. It is also not an official research. There is no statistical evidence. You might miss your favorite technology in this diagram. Then I did not see it in my conversations with customers, prospects, partners, analysts, or the broader data streaming community.
Also, note that I focus on general data streaming infrastructure. Brilliant solutions exist for using and analyzing streaming data for specific scenarios, like time-series databases, machine learning engines, observability platforms, or purpose-built IoT solutions. These are usually complementary, often connected out of the box via a Kafka connector, or even built on top of a data streaming platform (invisible for the end user).
Adoption and Completeness of Data Streaming (X-Axis)
Data streaming is adopted more and more across all industries. The concept is not new. In “The Past, Present and Future of Stream Processing“, I explored how the data streaming journey started decades ago with research and the first purpose-built proprietary products for specific use cases like stock trading.
Open source stream processing frameworks emerged during the big data and Hadoop era to make at least the ingestion layer a bit more real-time. Is anyone still remembering (or even still using) Apache Storm? 🙂
Today, most enterprises are realizing the value of data streaming for both analytical and operational use cases across industries. The cloud has brought a transformative shift, enabling businesses to start streaming and processing data with just a click, using fully managed SaaS solutions and intuitive UIs. Complete data streaming platforms now offer many built-in features that users previously had to develop themselves, including connectors, encryption, access control, governance, data sharing, and more.
Capabilities of a Complete Data Streaming Platform
Data streaming vendors are on the way to building a complete Data Streaming Platform (DSP). Capabilities include:
- Messaging (“Streaming”): Transfer messages in real-time and persist for durability, decoupling, and slow consumers (near real-time, batch, API, file).
- Data Integration: Connect to any legacy and cloud-native sources and sinks.
- Stream Processing: Correlate events with stateless and stateful transformation or business logic.
- Data Governance: Ensure security, observability, data sovereignty, and compliance.
- Developer Tooling: Enable flexibility for different personas such as software engineers, data scientists, and business analysts by providing different APIs (such as Java, Python, SQL, REST/HTTP), graphical user interfaces, and dashboards.
- Operations Tooling and SaaS: Ease infrastructure management on premise respectively take over the entire operations burden in the public cloud with serverless offerings.
- Uptime SLAs and Support: Provide the required guarantees and expertise for critical use cases.
Evolution from Open Source Adoption to a Data Streaming Organization
Modern data streaming is not just about adopting a product; it’s about transforming the way organizations operate and derive value from their data. Hence, the adoption goes beyond product features:
- From open source and self-operations to enterprise-grade products and SaaS.
- From human scale to automated, serverless elasticity with consumption-based pricing.
- From dumb ingestion pipes to complex data pipelines and business applications.
- From analytical workloads to critical transactional (and analytical) use cases.
- From a single data streaming cluster to a powerful edge, hybrid, and multi-cloud architecture, including integration, migration, aggregation, and disaster recovery scenarios.
- From wild adoption across business units with uncontrolled growth using various frameworks, cloud services, and integration tools to a center of excellence (CoE) with a strategic approach with standards, best practices, and knowledge sharing in an internal community.
- From effortful and complex human management to enterprise-wide data governance, automation, and self-service APIs.
Data Streaming Deployment Models: Self-Managed vs. BYOC vs. Cloud (Y-Axis)
Different data streaming categories exist regarding the deployment model:
- Self-Managed: Operate nodes like Kafka Broker, Kafka Connect, and Schema Registry by yourself with your favorite scripts and tools. This can be on-premise or in the public cloud in your VPC. Reduce the operations burden via a cloud-native platform (usually Kubernetes) and related operator tools that automate operations tasks like rolling upgrades or rebalancing Kafka Partitions.
- Bring Your Own Cloud (BYOC): Allow organizations to host Kafka within their own cloud VPC. BYOC combines some of the benefits of cloud flexibility with enhanced security and control, while it outsources most of Kafka’s management to specialized vendors. The data plane is still customer-managed, but in contrast to self-managed Kafka, the customer does not need to worry about the complexity under the hood (like rebalancing, rolling upgrades, backups) – that is what cloud-native object storage and other magic code of the BYOC control plane service take over.
- Cloud (PaaS or SaaS): Both PaaS and SaaS solutions operate within the cloud provider’s VPC. Fully managed SaaS for data streaming takes overall operational responsibilities, including scaling, failover handling, upgrades, and performance tuning, allowing users to focus solely on integration and business logic. In contrast, partially managed PaaS reduces the operational burden by automating certain tasks like rolling upgrades and rebalancing, but still requires some level of user involvement in managing the infrastructure. Fully Managed SaaS typically provides critical SLAs for support and uptime while partially managed PaaS cannot provide such guarantees.
Most organizations prefer SaaS for data streaming when business and technical requirements allow, as it minimizes operational complexity and maximizes scalability. Other deployment models are chosen when specific constraints or needs require them.
The Evolution of BYOC Kafka Cloud Services
Cloud and On-Premise deployment options are typically well understood, but BYOC (Bring Your Own Cloud) often requires more explanation due to its unique operating model and varying implementations across vendors.
In last year’s data streaming landscape 2024, I wrote the following about BYOC for Kafka:
“I do NOT believe in this approach as too many questions and challenges exist with BYOC regarding security, support, and SLAs in the case of P1 and P2 tickets and outages. Hence, I put this in the category of self-managed. That is what it is, even though the vendor touches your infrastructure. In the end, it is your risk because you have to and want to control your environment.”
This statement made sense because BYOC vendors at that time required access to the customer VPC and offered a shared support model. While this is still true for some BYOC solutions, my mind changed with the innovation of BYOC by one emerging vendor: WarpStream.
WarpStream’s BYOC Operating Model with Stateless Agents in the Customer VPC
WarpStream published a new operating model for BYOC: The customer only deploys stateless agents in its VPC and provides an object storage bucket to store the data. The control plane and metadata store are fully managed by the vendor as SaaS and the vendor takes over all the complexity.
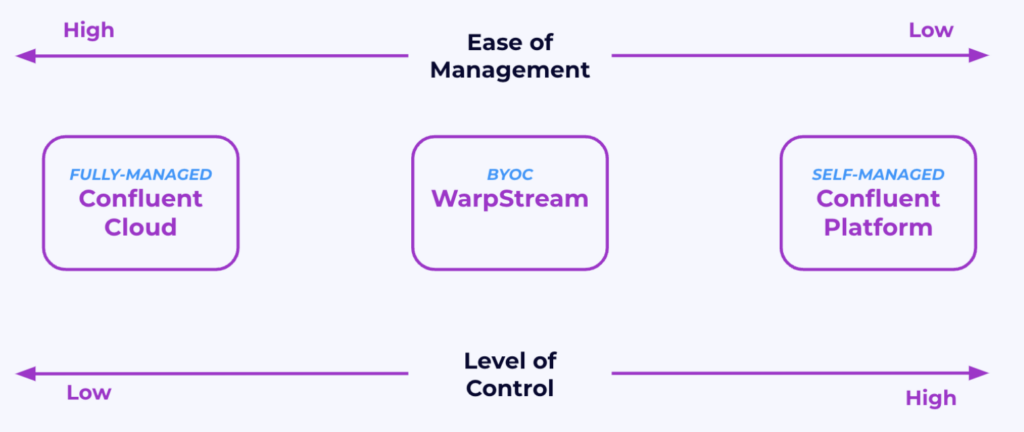
With this innovation, BYOC is now a worthwhile third deployment option besides a self-managed and fully managed data streaming platform. It brings several benefits:
- No access is needed by the BYOC cloud vendor to the customer VPC. The data plane (i.e., the “brokers” in the customer VPC) is stateless. The metadata/consensus is in the control plane (i.e., the cloud service in the WarpStream VPC).
- The architecture solves sovereignty challenges and is a great fit for security and compliance requirements.
- The cost of the BYOC offering is cheaper than self-managed Apache Kafka because it is built with cloud-native concepts and technologies in mind (e.g., zero disks and zero interzone networking fees, leveraging cloud object storage such as Amazon S3, Azure Blog Storage, or Google Cloud Storage).
- The stateless architecture in the customer VPC makes autoscaling and elasticity very easy to implement/configure.
When to use BYOC?
WarpStream introduced an innovative share-nothing operating model that makes BYOC practical, secure, and cost-efficient. With that being said, I still recommend only looking at BYOC options for Apache Kafka in the public cloud if a fully managed and serverless data streaming platform does NOT work for you because of cost, security, or compliance reasons! When it comes to simplicity and ease of operation, nothing beats a fully managed cloud service.
And please keep in mind that NOT every BYOC cloud service provides these characteristics and benefits. Make sure to make a proper evaluation of your favorite solutions. For more details, look at my blog post: “Deployment Options for Apache Kafka: Self-Managed, Fully-Managed / Serverless and BYOC (Bring Your Own Cloud)“.
Changes in the Data Streaming Landscape from 2024 to 2025
My goal is NOT a growing landscape with tens or even hundreds of vendors and cloud services. Plenty of these pictures exist. Instead, I focus on a few technologies, vendors, and cloud offerings that I see in the field, with adoption by the broader open-source and cloud community.
I already discussed the important conceptual changes in the data streaming landscape:
- Deployment Model: From self-managed, partially managed, and fully managed to self-managed, BYOC and cloud.
- Streaming Categories: From different streaming categories to a single category for all data streaming platforms sorted by adoption and completeness.
Additionally, every year I modified the list of solutions compared to the data streaming landscape 2024 published one year ago.
Additions to the Data Streaming Landscape 2025
The following data streaming services were added:
- Alibaba (Cloud): Confluent Data Streaming Service on Alibaba Cloud is an OEM partnership between Alibaba Cloud and Confluent to offer a fully managed SaaS in Mainland China. The service was announced end of 2021 and sees more and more traction in Asia. Alibaba is the contractor and first-level support for the end user.
- Google Managed Service for Kafka (Cloud): Google announced this Kafka PaaS recently. The strategy looks very similar to Amazon’s MSK. Even the shortcut is the same: MSK. I explored when (not) to choose Google’s Kafka cloud service after the announcement. The service is still in preview, but available to a huge customer base already.
- Oracle Streaming with Apache Kafka (Cloud): A partially managed Apache Kafka PaaS on Oracle Cloud Infrastructure (OCI). The service is in early access, but available to a huge customer base already.
- WarpStream (BYOC): WarpStream was acquired by Confluent. It is still included with its logo as Confluent continues to keep the brand and solution separated (at least for now).
Removals from the Data Streaming Landscape 2025
There are NO REMOVALS this year, BUT I was close to removing two technologies:
- Apache Pulsar and StreamNative: I was close to removing Apache Pulsar as I see zero traction in the market. Around 2020, Pulsar had some traction but focused too much on Kafka FUD instead of building a vibrant community. While Kafka simplified its architecture (ZooKeeper removal), Pulsar still includes three distributed systems (ZooKeeper or alternatives like etcd, BookKeeper, and Pulsar Broker). It also pivots to the Kafka protocol trying to get some more traction again. But it seems to be too late.
- ksqlDB (formerly called KSQL): The product is feature complete. While it is still supported by Confluent, it will not get any new features. ksqlDB is still a great piece of software for some (!) Kafka-native stream processing projects but might be removed in the future. Confluent co-founder and Kafka co-creator Jay Kreps commented on X (former Twitter): “Confluent went through a set of experiments in this area. What we learned is that for *platform* layers you want a clean separation. We learned this the hard way: our source available stream processing layer KSQL, lost to open-source Apache Flink. We pivoted to Flink.“
Vendor Overview for Data Streaming Platforms
All vendors of the landscape do some kind of data streaming. However, the offerings differ a lot in adoption, completeness, and vision. And many solutions are not available everywhere but only in one public cloud or only as self-managed. For detailed product information and experiences, the vendor websites and other blogs/conference talks are the best and most up-to-date resources. The following is just a summary to get an overview.
Before we do the deep dive, here again, the entire data streaming landscape for 2025:
Self-Managed Data Streaming with Open Source and Proprietary Products

The following list describes the open-source frameworks and proprietary products for self-managed data streaming deployments (in order of adoption and completeness):
- Apache Pulsar: A competitor to Apache Kafka. Similar story and use cases, but different architecture. Kafka is a single distributed cluster – after removing the ZooKeeper dependency in 2022. Pulsar is three (!) distributed clusters: Pulsar brokers, ZooKeeper, and BookKeeper. Pulsar vs. Kafka explored the differences. And Kafka catches up to some missing features like Queues for Kafka.
- StreamNative: The primary vendor behind Apache Pulsar. Not much market traction.
- ksqlDB (usually called KSQL, even after Confluent’s rebranding): An abstraction layer on top of Kafka Streams to provide stream processing with streaming SQL. Hence, also Kafka-native. It comes with a Confluent Community License and is free to use. Sweet spot: Streaming ETL.
- Redpanda: Implements the Kafka protocol with C++. Trying out different market strategies to define Redpanda as an alternative to a Kafka-native offering. Still in the early stage in the maturity curve. Adding tons of (immature) product features in parallel to find the right market fit in a growing Kafka market. Recently acquired Benthos to provide connectivity to data sources and sinks (similar to Kafka Connect).
- Ververica: Well-known Flink company. Acquired by Chinese tech giant Alibaba in 2019. Not much traction in Europe and the US. Sweet spot: Flink in Mainland China.
- Apache Flink: Becoming the de facto standard for stream processing. Open-source implementation. Provides advanced features including a powerful scalable compute engine, freedom of choice for developers between SQL, Java, and Python, APIs for Complex Event Processing (CEP), and unified APIs for stream and batch workloads.
- Spark Streaming: The streaming part of the open-source big data processing framework Apache Spark. The enormous installed base of Spark clusters in enterprises broadens adoption thanks to solutions from Cloudera, Databricks, and the cloud service providers. Sweet spot: Analytics in (micro)batches with data stored at rest in the data lake/lakehouse.
- Apache Kafka: The de facto standard for data streaming. Open-source implementation with a vast community. Almost all vendors rely on (parts of) this project. Often underestimated: Kafka includes data integration and stream processing capabilities with Kafka Connect and Kafka Streams, making even the open-source Apache download already more powerful than many other data streaming frameworks and products.
- IBM / Red Hat AMQ Streams: Provides Kafka as self-managed Kafka on Kubernetes via OpenShift. Kafka is part of the integration portfolio that includes other open-source frameworks like Apache Camel. Sweet spot: Existing IBM customers.
- Cloudera: Provides Kafka, Flink, and other open-source data and analytics frameworks as a self-managed offering. The main strategy is offering one product with a vast combination of many open-source frameworks that can be deployed on any infrastructure. Sweet spot: Analytics.
- Confluent Platform: Focuses on a complete data streaming platform including Kafka and Flink, and various advanced data streaming capabilities for operations, integration, governance, and security. Sweet spot: Unifying operational and analytical workloads, and combination with the fully managed cloud service.
Data Streaming with Bring Your Own Cloud (BYOC)

BYOC is an emerging category and is mainly used for specific challenges such as strict data security and compliance requirements. The following vendors provide dedicated BYOC offerings for data streaming (in order of adoption and completeness)
- WarpStream (Confluent): A new entrant into the data streaming market. The cloud service is a Kafka-compatible data streaming platform built directly on top of S3. Innovated the BYOC model to enable secure and cost-effective data streaming for workloads that don’t have strong latency requirements.
- Redpanda: The first BYOC offering on the market for data streaming. The biggest concern is the shared responsibility model of this solution because the vendor requires access to the customer VPC for operations and support. This is against the key principles of BYOC regarding security and compliance and why organizations (have to) look for BYOC instead of SaaS solutions.
- Databricks: Cloud-based data platform that provides a collaborative environment for data engineering, data science, and machine learning, built on top of Apache Spark. Data Streaming is enabled by Spark Streaming and focuses mainly on analytical workloads that are optimized from batch to near real-time.
Partially Managed Data Streaming Cloud Platforms (PaaS)

Here is an overview of relevant PaaS data streaming cloud services (in order of adoption and completeness):
- Google Cloud Managed Service for Apache Kafka (MSK): Initially branded as Google Managed Kafka for BigQuery (likely for a better marketing push), the service enables data ingestion into lakehouses on GCP such as Google BigQuery.
- Amazon Managed Service for Apache Flink (MSF): A partially managed service by AWS that allows customers to transform and analyze streaming data in real-time with Apache Flink. It still provides some (costly) gaps for auto-scaling and is not truly serverless. Supports all Flink interfaces, i.e., SQL, Java, and Python. And non-Kafka connectors, too. Only available on AWS.
- Oracle OCI Streaming with Apache Kafka: The service is still in early access, but available to a huge customer base already on Oracle’s cloud infrastructure.
- Microsoft Azure HDInsight. A piece of Azure’s Hadoop infrastructure. Not intended for other use cases beyond data ingestion for batch analytics.
- Instaclustr: Partially managed Kafka cloud offerings across cloud providers. The product portfolios offer various hosted services of open-source technologies. Instaclustr also offers a (semi-)managed offering for on-premise infrastructure.
- Amazon Kinesis: Data ingestion into AWS data stores. Mature product for a specific problem. Only available on AWS.
- Aiven: Partially managed Kafka cloud offerings across cloud providers. The product portfolios offer various hosted services of open-source technologies.
- IBM / Red Hat AMQ Streams: Provides Kafka as a partially managed cloud offering on OpenShift (through Red Hat). Sweet spot: Existing IBM customers.
- Amazon Managed Service for Apache Kafka (MSK): AWS has hundreds of cloud services, and Kafka is part of that broad spectrum. MSK is only available in public AWS cloud regions; not on Outposts, Local Zones, Wavelength, etc. MSK is likely the largest partially managed Kafka service across all clouds. It evolved with new features like support for Kafka Connect and Tiered Storage. But lacks connectivity outside the AWS ecosystem and a data governance narrative.
Fully Managed Data Streaming Cloud Services (SaaS)

Here is an overview of relevant SaaS data streaming cloud services (in order of adoption and completeness):
- Decodable: A relatively new cloud service for Apache Flink in the early stage. Huge potential if it is combined with existing Kafka infrastructures in enterprises. But also provides pre-built connectors for non-Kafka systems. Main Opportunity: Combination with another cloud vendor that only does Kafka or other messaging/streaming without stream processing capabilities.
- StreamNative Cloud: The primary vendor behind Apache Pulsar. Offers self-managed and fully managed solutions. StreamNative Cloud for Kafka is still in a very early stage of maturity, not sure if it will ever strengthen.
- Ververica: Stream processing as a service powered by Apache Flink on all major cloud providers. Huge potential if it is combined with existing Kafka infrastructures in enterprises. Main Opportunity: Combination with another cloud vendor that only does Kafka or other messaging/streaming without stream processing capabilities.
- Redpanda Cloud: Redpanda provides its data streaming as a serverless offering. Not much information is available on the website about this part of the vendor’s product portfolio.
- Amazon MSK Serverless: Different functionalities and limitations than Amazon MSK. MSK Serverless still does not get much traction because of its limitations. Both MSK offerings exclude Kafka support in their SLAs (please read the terms and conditions).
- Google Cloud DataFlow: Fully managed service for executing Apache Beam pipelines within the Google Cloud Platform ecosystem. Mature product for a specific problem. Only available on GCP.
- Azure Event Hubs: A mature, fully managed cloud service. The service does one thing, and that is done very well: Data ingestion via the Kafka protocol. Hence, it is not a complete streaming platform but is more comparable to Amazon Kinesis or Google Cloud PubSub. The limited compatibility with the Kafka protocol and the high cost of the service for higher throughput are the two major blockers that come up regularly in conversations.
- Confluent Cloud: A complete data streaming platform including Kafka and Flink as a fully managed offering. In addition to deep integration, the platform provides connectivity, security, data governance, self-service portal, disaster recovery tooling, and much more to be the most complete DSP on all major public clouds.
Potential for the Data Streaming Landscape 2026
Data streaming is a journey. So is the development of event streaming platforms and cloud services. Several established software and cloud vendors might get more traction with their data streaming offerings. And some startups might grow significantly. The following shows a few technologies that might evolve and see growing adoption in 2025:
- New startups around the Kafka protocol emerge. The list of new frameworks and cloud services is growing every quarter. A few names I saw in some social network posts (but not much beyond in the real world): AutoMQ, S2, Astradot, Bufstream, Responsive, tansu, Tektite, Upstash. While some focus on the messaging/streaming part, others focus on a particular piece such as building database capabilities.
- Streaming databases like Materialize or RisingWave might become a new software category. My feeling: Very early stage of the hype cycle. We will see in 2025 if and where this technology gets more broadly adopted and what the use cases are. It is hard to answer how these will compete with emerging real-time analytics databases like Apache Druid, Apache Pinot, ClickHouse, Timeplus, Tinybird, et al. I know there are differences, but the broader community and companies need to a) understand these differences and b) find business problems for it.
- Stream Processing SaaS startups emerge: Quix and Bytewax provide stream processing with Python. Quix now also offers a hosted offering based on Kafka Streams; as does Responsive. DeltaStream provides Apache Flink as SaaS. And many more startups emerge these days. Let’s see which of these gets traction in the market with an innovative product and business model.
- Traditional data management vendors like MongoDB or Snowflake try to get deeper into the data streaming business. I am still a fan of separation of concerns; so I think these should keep their sweet spot and (only) provide streaming ingestion and CDC as use cases, but not (try to) compete with data streaming vendors.
Fun fact: The business model of almost all emerging startups is fully managed cloud services, not selling licenses for on-premise deployments. Many are based on open-source or open-core, and others only provide a proprietary implementation.
Although they are not aiming to be full data streaming platforms (and thus are not part of the platform landscape), other complementary tools are gaining momentum in the data streaming ecosystem. For instance, Conduktor is developing a proxy for Kafka clusters, and Lenses, though relatively quiet since its acquisition by Celonis, has recently introduced updates to its user-friendly management and developer tools. These tools address gaps that some data streaming platforms leave unfilled.
Data Streaming: A Journey, Not a Sprint
Data streaming isn’t a sprint—it’s a journey! Adopting event-driven architectures with technologies like Apache Kafka or Apache Flink requires rethinking how applications are designed, developed, deployed, and monitored. Modern data strategies involve legacy integration, cloud-native microservices, and data sharing across hybrid and multi-cloud environments.
The data streaming landscape in 2025 highlights the emergence of a new software category, though it’s still in its early stages. Building such a category takes time. In discussions with customers, partners, and the community, a common sentiment emerges: “We understand the value but are just starting with the first data streaming pipelines and have a long-term plan to implement advanced stream processing and build a strategic data streaming organization.”
The Forrester Wave: Streaming Data Platforms, Q4 2023, and other industry reports from Gartner and IDG signal that this category is progressing through the hype cycle.
Last but not least, check out my Top Data Streaming Trends for 2025 to understand how the data streaming landscape fits into emerging trends:
- Democratization of Kafka: Apache Kafka has transitioned from a specialized tool to a foundational platform in modern data infrastructure.
- Kafka Protocol as the Standard: Vendors adopt the Kafka protocol over the framework, enabling flexibility with compatibility and performance trade-offs.
- BYOC Deployment Model: Bring Your Own Cloud gains traction for balancing security, compliance, and managed services.
- Flink Becomes the Standard for Stream Processing: Apache Flink rises as the premier framework for stream processing, building integration pipelines and business applications.
- Data Streaming for Real-Time Predictive AI and GenAI: Real-time model inference drives predictive and generative AI applications.
- Data Streaming Organizations: Companies unify real-time data strategies to standardize tools, governance, and collaboration.
Which are your favorite open-source frameworks or cloud services for data streaming? What are your most relevant and exciting trends around Apache Kafka and Flink in 2024 to set data in motion? What does your enterprise landscape for data streaming look like? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter. Make sure to download by free ebook about data streaming use cases and industry examples.






