Operational Technology (OT) has traditionally relied on legacy middleware to connect industrial systems, manage data flows, and integrate with enterprise IT. However, these monolithic, proprietary, and expensive middleware solutionsstruggle to keep up with real-time, scalable, and cloud-native architectures.
Just as mainframe offloading modernized enterprise IT, offloading and replacing legacy OT middleware is the next wave of digital transformation. Companies are shifting from vendor-locked, heavyweight OT middleware to real-time, event-driven architectures using Apache Kafka and Apache Flink—enabling cost efficiency, agility, and seamless edge-to-cloud integration.
This blog explores why and how organizations are replacing traditional OT middleware with data streaming, the benefits of this shift, and architectural patterns for hybrid and edge deployments.
Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases, including architectures and customer stories for hybrid IT/OT integration scenarios.
Why Replace Legacy OT Middleware?
Industrial environments have long relied on OT middleware like OSIsoft PI, proprietary SCADA systems, and industry-specific data buses. These solutions were designed for polling-based communication, siloed data storage, and batch integration. But today’s real-time, AI-driven, and cloud-native use cases demand more.
Challenges: Proprietary, Monolithic, Expensive
- High Costs – Licensing, maintenance, and scaling expenses grow exponentially.
- Proprietary & Rigid – Vendor lock-in restricts flexibility and data sharing.
- Batch & Polling-Based – Limited ability to process and act on real-time events.
- Complex Integration – Difficult to connect with cloud and modern IT systems.
- Limited Scalability – Not built for the massive data volumes of IoT and edge computing.
Just as PLCs are transitioning to virtual PLCs, eliminating hardware constraints and enabling software-defined industrial control, OT middleware is undergoing a similar shift. Moving from monolithic, proprietary middleware to event-driven, streaming architectures with Kafka and Flink allows organizations to scale dynamically, integrate seamlessly with IT, and process industrial data in real time—without vendor lock-in or infrastructure bottlenecks.
The Data Streaming Approach: Kafka & Flink as the Foundation for Modern OT Middleware
Data streaming is NOT a direct replacement for OT middleware, but it serves as the foundation for modernizing industrial data architectures. With Kafka and Flink, enterprises can offload or replace OT middleware to achieve real-time processing, edge-to-cloud integration, and open interoperability.
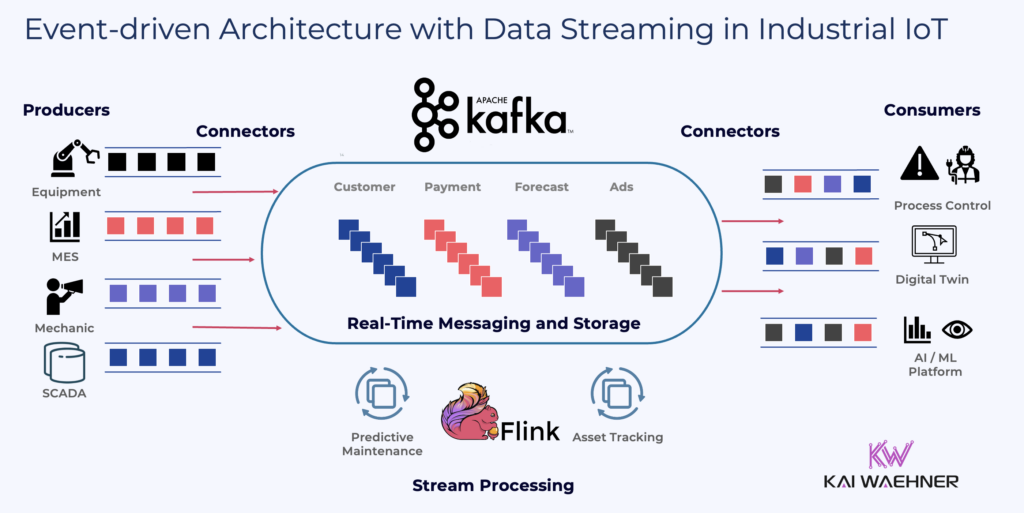
While Kafka and Flink provide real-time, scalable, and event-driven capabilities, last-mile integration with PLCs, sensors, and industrial equipment still requires OT-specific SDKs, open interfaces, or lightweight middleware. This includes support for MQTT, OPC UA or open-source solutions like Apache PLC4X to ensure seamless connectivity with OT systems.
Apache Kafka: The Backbone of Real-Time OT Data Streaming
Kafka acts as the central nervous system for industrial data to ensure low-latency, scalable, and fault-tolerant event streaming between OT and IT systems.
- Aggregates and normalizes OT data from sensors, PLCs, SCADA, and edge devices.
- Bridges OT and IT by integrating with ERP, MES, cloud analytics, and AI/ML platforms.
- Operates seamlessly in hybrid, multi-cloud, and edge environments, ensuring real-time data flow.
- Works with open OT standards like MQTT and OPC UA, reducing reliance on proprietary middleware solutions.
And just to be clear: Apache Kafka and similar technologies support “IT real-time” (meaning milliseconds of latency and sometimes latency spikes). This is NOT about hard real-time in the OT world for embedded systems or safety critical applications.
Apache Flink: The Real-Time Processing Engine for OT Data
Flink powers real-time analytics, complex event processing, and anomaly detection for streaming industrial data.
- Processes sensor data in real-time for predictive maintenance, energy optimization, and fault detection.
- Enables stateful stream processing, supporting event correlation, time-series aggregation, and trend analysis.
- Runs on edge devices, data centers, or cloud platforms, providing scalability and deployment flexibility.
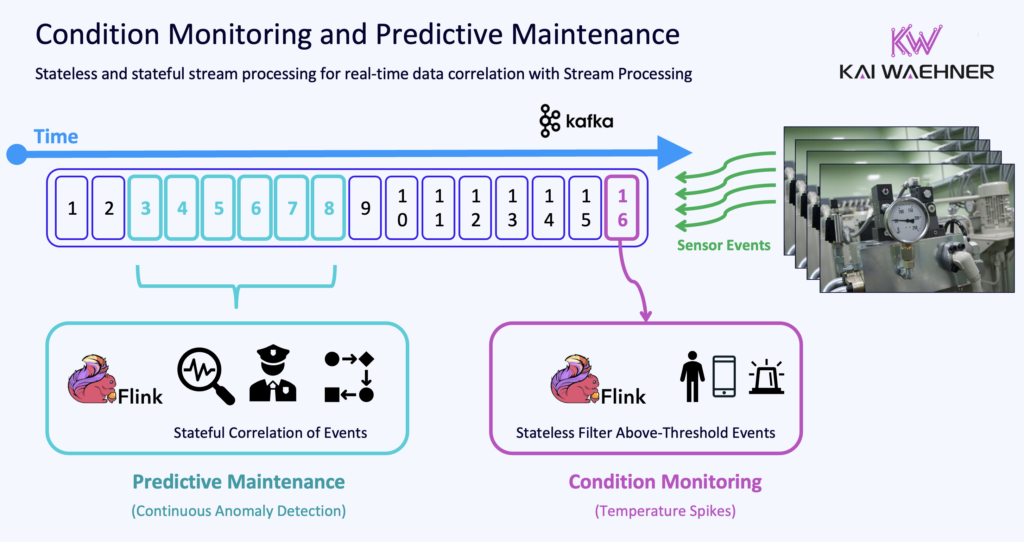
By leveraging Kafka and Flink, enterprises can process OT and IT data only once, ensuring a real-time, unified data architecture that eliminates redundant processing across separate systems. This approach enhances operational efficiency, reduces costs, and accelerates digital transformation while still integrating seamlessly with existing industrial protocols and interfaces.
Unifying Operational (OT) and Analytical (IT) Workloads
As industries modernize, a shift-left architecture approach ensures that operational data is not just consumed for real-time operational OT workloads but is also made available for transactional and analytical IT use cases—without unnecessary duplication or transformation overhead.
The Shift-Left Architecture: Bringing Advanced Analytics Closer to Industrial IoT
In traditional architectures, OT data is first collected, processed, and stored in proprietary or siloed middleware systems before being moved later to IT systems for analysis. This delayed, multi-step process leads to inefficiencies, including:
- High latency between data collection and actionable insights.
- Redundant data storage and transformations, increasing complexity and cost.
- Disjointed AI/ML pipelines, where models are trained on outdated, pre-processed data rather than real-time information.
A shift-left approach eliminates these inefficiencies by bringing analytics, AI/ML, and data science closer to the raw, real-time data streams from the OT environments.
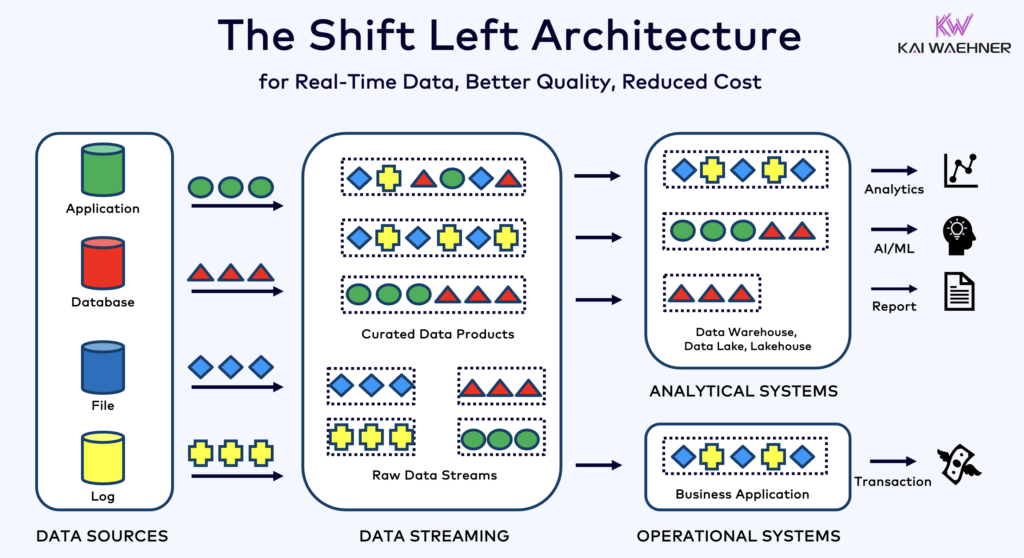
Instead of waiting for batch pipelines to extract and move data for analysis, a modern architecture integrates real-time streaming with open table formats to ensure immediate usability across both operational and analytical workloads.
Open Table Format with Apache Iceberg / Delta Lake for Unified Workloads and Single Storage Layer
By integrating open table formats like Apache Iceberg and Delta Lake, organizations can:
- Unify operational and analytical workloads to enable both real-time data streaming and batch analytics in a single architecture.
- Eliminate data silos, ensuring that OT and IT teams access the same high-quality, time-series data without duplication.
- Ensure schema evolution and ACID transactions to enable robust and flexible long-term data storage and retrieval.
- Enable real-time and historical analytics, allowing engineers, business users, and AI/ML models to query both fresh and historical data efficiently.
- Reduce the need for complex ETL pipelines, as data is written once and made available for multiple workloadssimultaneously. And no need to use the anti-pattern of Reverse ETL.
The Result: An Open, Cloud-Native, Future-Proof Data Historian for Industrial IoT
This open, hybrid OT/IT architecture allows organizations to maintain real-time industrial automation and monitoring with Kafka and Flink, while ensuring structured, queryable, and analytics-ready data with Iceberg or Delta Lake. The shift-left approach ensures that data streams remain useful beyond their initial OT function, powering AI-driven automation, predictive maintenance, and business intelligence in near real-time rather than relying on outdated and inconsistent batch processes.
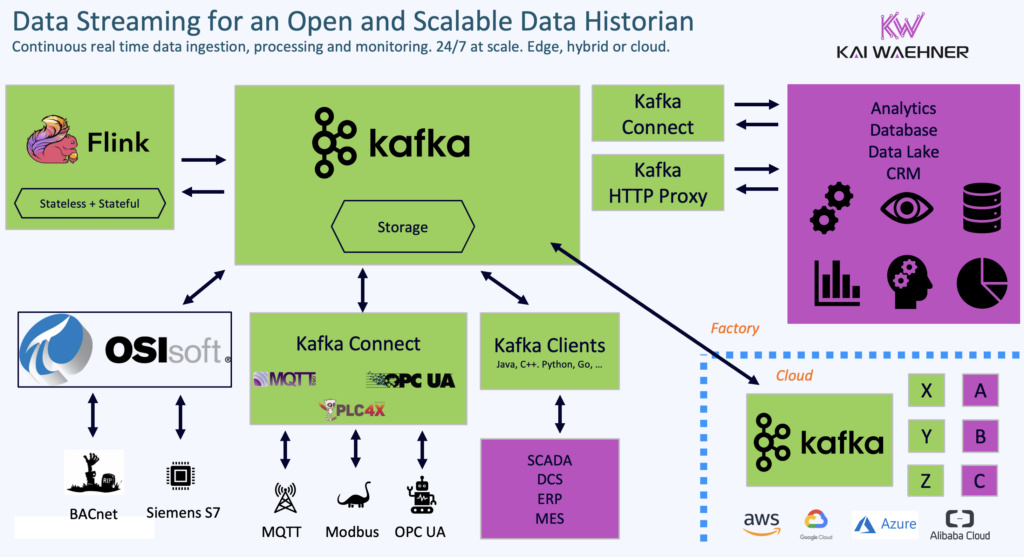
By adopting this unified, streaming-first architecture to build an open and cloud-native data historian, organizations can:
- Process data once and make it available for both real-time decisions and long-term analytics.
- Reduce costs and complexity by eliminating unnecessary data duplication and movement.
- Improve AI/ML effectiveness by feeding models with real-time, high-fidelity OT data.
- Ensure compliance and historical traceability without compromising real-time performance.
This approach future-proofs industrial data infrastructures, allowing enterprises to seamlessly integrate IT and OT, while supporting cloud, edge, and hybrid environments for maximum scalability and resilience.
Key Benefits of Offloading OT Middleware to Data Streaming
- Lower Costs – Reduce licensing fees and maintenance overhead.
- Real-Time Insights – No more waiting for batch updates; analyze events as they happen.
- One Unified Data Pipeline – Process data once and make it available for both OT and IT use cases.
- Edge and Hybrid Cloud Flexibility – Run analytics at the edge, on-premise, or in the cloud.
- Open Standards & Interoperability – Support MQTT, OPC UA, REST/HTTP, Kafka, and Flink, avoiding vendor lock-in.
- Scalability & Reliability – Handle massive sensor and machine data streams continuously without performance degradation.
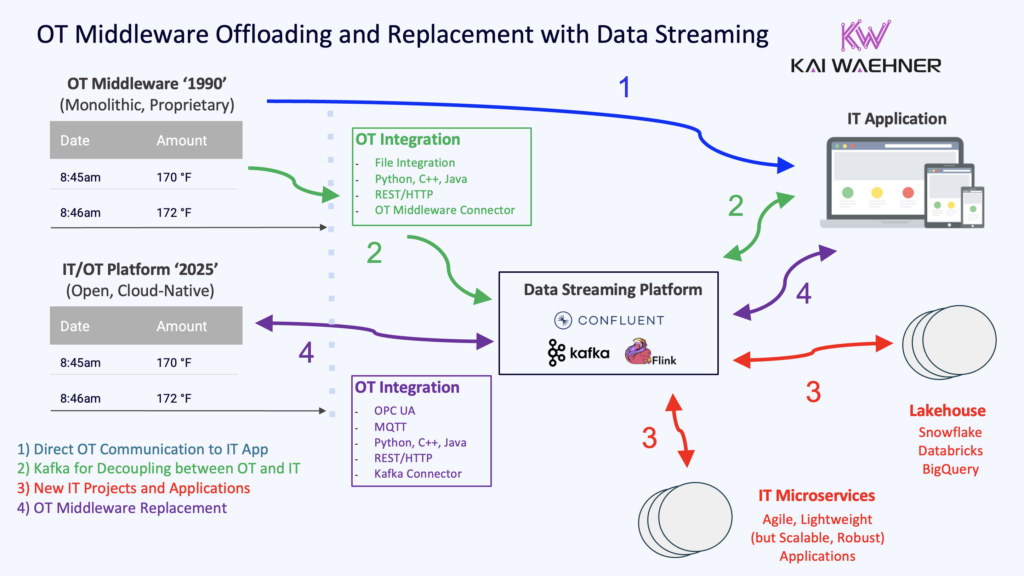
A Step-by-Step Approach: Offloading vs. Replacing OT Middleware with Data Streaming
Companies transitioning from legacy OT middleware have several strategies by leveraging data streaming as an integration and migration platform:
- Hybrid Data Processing
- Lift-and-Shift
- Full OT Middleware Replacement
1. Hybrid Data Streaming: Process Once for OT and IT
Why?
Traditional OT architectures often duplicate data processing across multiple siloed systems, leading to higher costs, slower insights, and operational inefficiencies. Many enterprises still process data inside expensive legacy OT middleware, only to extract and reprocess it again for IT, analytics, and cloud applications.
A hybrid approach using Kafka and Flink enables organizations to offload processing from legacy middleware while ensuring real-time, scalable, and cost-efficient data streaming across OT, IT, cloud, and edge environments.
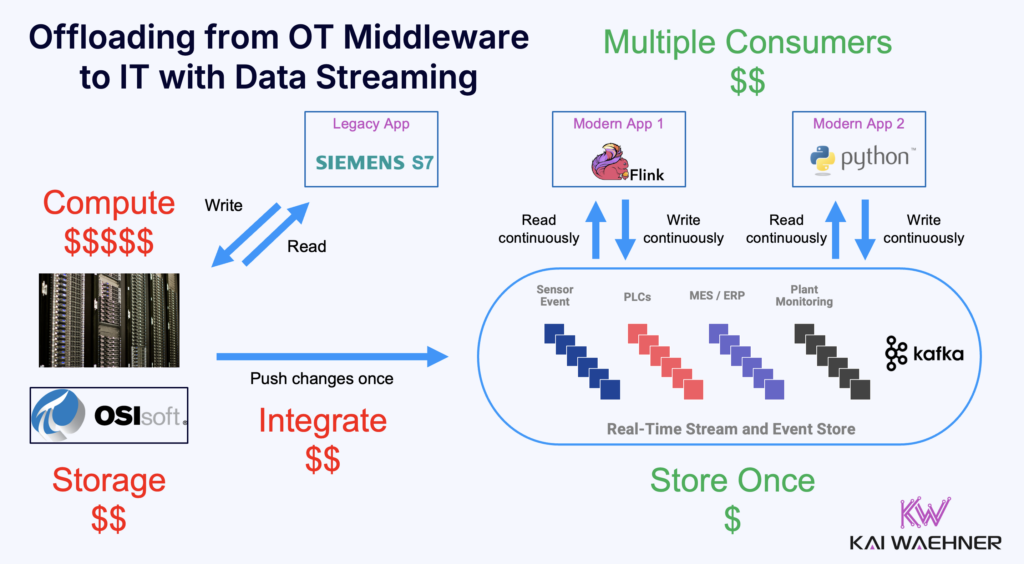
How?
Connect to the existing OT middleware via:
- A Kafka Connector (if available).
- HTTP APIs, OPC UA, or MQTT for data extraction.
- Custom integrations for proprietary OT protocols.
- Lightweight edge processing to pre-filter data before ingestion.
Use Kafka for real-time ingestion, ensuring all OT data is available in a scalable, event-driven pipeline.
Process data once with Flink to:
- Apply real-time transformations, aggregations, and filtering at scale.
- Perform predictive analytics and anomaly detection before storing or forwarding data.
- Enrich OT data with IT context (e.g., adding metadata from ERP or MES).
Distribute processed data to the right destinations, such as:
- Time-series databases for historical analysis and monitoring.
- Enterprise IT systems (ERP, MES, CMMS, BI tools) for decision-making.
- Cloud analytics and AI platforms for advanced insights.
- Edge and on-prem applications that need real-time operational intelligence.
Result?
- Eliminate redundant processing across OT and IT, reducing costs.
- Real-time data availability for analytics, automation, and AI-driven decision-making.
- Unified, event-driven architecture that integrates seamlessly with on-premise, edge, hybrid, and cloud environments.
- Flexibility to migrate OT workloads over time, without disrupting current operations.
By offloading costly data processing from legacy OT middleware, enterprises can modernize their industrial data infrastructure while maintaining interoperability, efficiency, and scalability.
2. Lift-and-Shift: Reduce Costs While Keeping Existing OT Integrations
Why?
Many enterprises rely on legacy OT middleware like OSIsoft PI, proprietary SCADA systems, or industry-specific data hubs for storing and processing industrial data. However, these solutions come with high licensing costs, limited scalability, and an inflexible architecture.
A lift-and-shift approach provides an immediate cost reduction by offloading data ingestion and storage to Apache Kafka while keeping existing integrations intact. This allows organizations to modernize their infrastructure without disrupting current operations.
How?
Use the Stranger Fig Design Pattern as a gradual modernization approach where new systems incrementally replace legacy components, reducing risk and ensuring a seamless transition:

“The most important reason to consider a strangler fig application over a cut-over rewrite is reduced risk.” Martin Fowler
Replace expensive OT middleware for ingestion and storage:
- Deploy Kafka as a scalable, real-time event backbone to collect and distribute data.
- Offload sensor, PLC, and SCADA data from OSIsoft PI, legacy brokers, or proprietary middleware.
- Maintain the connectivity with existing OT applications to prevent workflow disruption.
Streamline OT data processing:
- Store and distribute data in Kafka instead of proprietary, high-cost middleware storage.
- Leverage schema-based data governance to ensure compatibility across IT and OT systems.
- Reduce data duplication by ingesting once and distributing to all required systems.
Maintain existing IT and analytics integrations:
- Keep connections to ERP, MES, and BI platforms via Kafka connectors.
- Continue using existing dashboards and reports while transitioning to modern analytics platforms.
- Avoid vendor lock-in and enable future migration to cloud or hybrid solutions.
Result?
- Immediate cost savings by reducing reliance on expensive middleware storage and licensing fees.
- No disruption to existing workflows, ensuring continued operational efficiency.
- Scalable, future-ready architecture with the flexibility to expand to edge, cloud, or hybrid environments over time.
- Real-time data streaming capabilities, paving the way for predictive analytics, AI-driven automation, and IoT-driven optimizations.
A lift-and-shift approach serves as a stepping stone toward full OT modernization, allowing enterprises to gradually transition to a fully event-driven, real-time architecture.
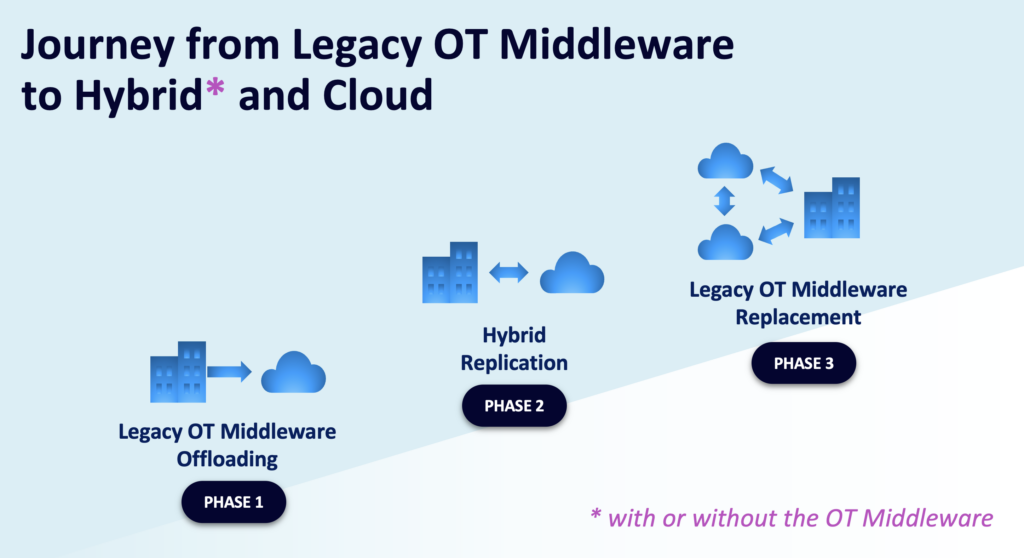
3. Full OT Middleware Replacement: Cloud-Native, Scalable, and Future-Proof
Why?
Legacy OT middleware systems were designed for on-premise, batch-based, and proprietary environments, making them expensive, inflexible, and difficult to scale. As industries embrace cloud-native architectures, edge computing, and real-time analytics, replacing traditional OT middleware with event-driven streaming platforms enables greater flexibility, cost efficiency, and real-time operational intelligence.
A full OT middleware replacement eliminates vendor lock-in, outdated integration methods, and high-maintenance costs while enabling scalable, event-driven data processing that works across edge, on-premise, and cloud environments.
How?
Use Kafka and Flink as the Core Data Streaming Platform
- Kafka replaces legacy data brokers and middleware storage by handling high-throughput event ingestion and real-time data distribution.
- Flink provides advanced real-time analytics, anomaly detection, and predictive maintenance capabilities.
- Process OT and IT data in real-time, eliminating batch-based limitations.
Replace Proprietary Connectors with Lightweight, Open Standards
- Deploy MQTT or OPC UA gateways to enable seamless communication with sensors, PLCs, SCADA, and industrial controllers.
- Eliminate complex, costly middleware like OSIsoft PI with low-latency, open-source integration.
- Leverage Apache PLC4X for industrial protocol connectivity, avoiding proprietary vendor constraints.
Adopt a Cloud-Native, Hybrid, or On-Premise Storage Strategy
- Store time-series data in scalable, purpose-built databases like InfluxDB or TimescaleDB.
- Enable real-time query capabilities for monitoring, analytics, and AI-driven automation.
- Ensure data availability across on-premise infrastructure, hybrid cloud, and multi-cloud deployments.
Modernize IT and Business Integrations
- Enable seamless OT-to-IT integration with ERP, MES, BI, and AI/ML platforms.
- Stream data directly into cloud-based analytics services, digital twins, and AI models.
- Build real-time dashboards and event-driven applications for operators, engineers, and business stakeholders.
Result?
- Fully event-driven and cloud-native OT architecture that eliminates legacy bottlenecks.
- Real-time data streaming and processing across all industrial environments.
- Scalability for high-throughput workloads, supporting edge, hybrid, and multi-cloud use cases.
- Lower operational costs and reduced maintenance overhead by replacing proprietary, heavyweight OT middleware.
- Future-ready, open, and extensible architecture built on Kafka, Flink, and industry-standard protocols.
By fully replacing OT middleware, organizations gain real-time visibility, predictive analytics, and scalable industrial automation, unlocking new business value while ensuring seamless IT/OT integration.
Helin is an excellent example for a cloud-native IT/OT data solution powered by Kafka and Flink to focus on real-time data integration and analytics, particularly in the context of industrial and operational environments. Its industry focus on maritime and energy sector, but this is relevant across all IIoT industries.
Why This Matters: The Future of OT is Real-Time & Open for Data Sharing
The next generation of OT architectures is being built on open standards, real-time streaming, and hybrid cloud.
- Most new industrial sensors, machines, and control systems are now designed with Kafka, MQTT, and OPC UA compatibility.
- Modern IT architectures demand event-driven data pipelines for AI, analytics, and automation.
- Edge and hybrid computing require scalable, fault-tolerant, real-time processing.
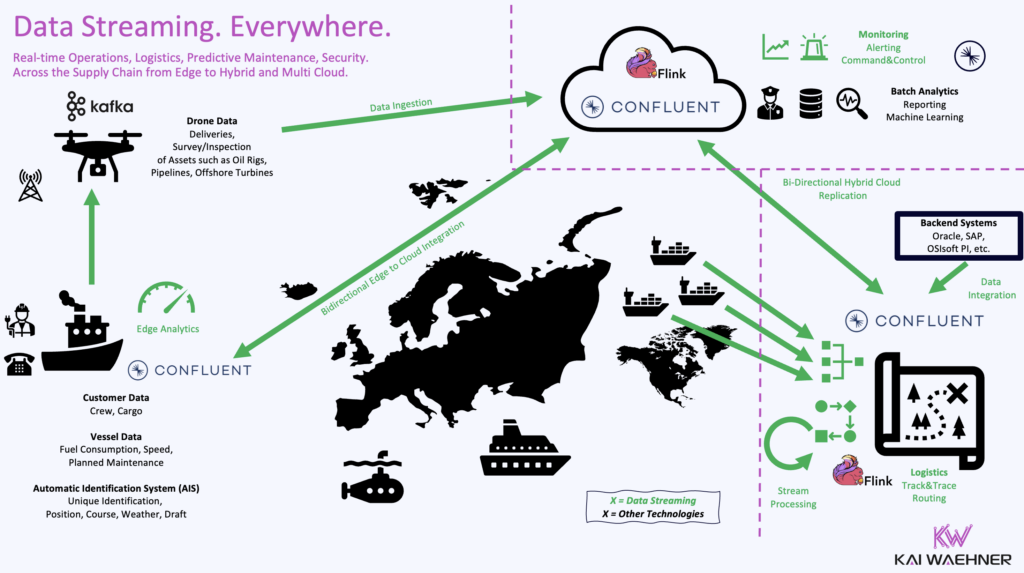
Use Kafka Cluster Linking for seamless bi-directional data replication and command&control, ensuring low-latency, high-availability data synchronization across on-premise, edge, and cloud environments.
Enable multi-region and hybrid edge to cloud architectures with real-time data mirroring to allow organizations to maintain data consistency across global deployments while ensuring business continuity and failover capabilities.
It’s Time to Move Beyond Legacy OT Middleware to Open Standards like MQTT, OPC-UA, Kafka
The days of expensive, proprietary, and rigid OT middleware are numbered (at least for new deployments). Industrial enterprises need real-time, scalable, and open architectures to meet the growing demands of automation, predictive maintenance, and industrial IoT. By embracing open IoT and data streaming technologies, companies can seamlessly bridge the gap between Operational Technology (OT) and IT, ensuring efficient, event-driven communication across industrial systems.
MQTT, OPC-UA and Apache Kafka are a match in heaven for industrial IoT:
- MQTT enables lightweight, publish-subscribe messaging for industrial sensors and edge devices.
- OPC-UA provides secure, interoperable communication between industrial control systems and modern applications.
- Kafka acts as the high-performance event backbone, allowing data from OT systems to be streamed, processed, and analyzed in real time.
Whether lifting and shifting, optimizing hybrid processing, or fully replacing legacy middleware, data streaming is the foundation for the next generation of OT and IT integration. With Kafka at the core, enterprises can decouple systems, enhance scalability, and unlock real-time analytics across the entire industrial landscape.
Stay ahead of the curve! Subscribe to my newsletter for insights into data streaming and connect with me on LinkedIn to continue the conversation. And make sure to download my free book about data streaming use cases and industry success stories.






