
Batch processing has long been the default approach for moving and transforming data in enterprise systems. It works on fixed schedules, processes data in large chunks, and often relies on complex chains of jobs that run overnight. While this was acceptable in the past, today’s digital businesses operate in real time—and can’t afford to wait hours for fresh insights. Delays, errors, and inconsistencies caused by batch workflows lead to poor decisions, missed opportunities, and growing operational costs. In this post, we’ll look at common issues with batch processing and show why data streaming is the modern alternative for fast, reliable, and scalable data infrastructure.

Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And download my free book about data streaming architectures and use cases to understand the benefits over batch processing.
The Issues of Batch Processing
While batch processing has powered data pipelines for decades, it introduces a range of problems that make it increasingly unfit for today’s real-time, scalable, and reliable data needs.

Adi Polak’s keynote about the issues of batch processing at Current in Austin, USA, inspired me to explore each point with a concrete example and how data streaming with technologies such as Apache Kafka and Flink helps.
Real-time Data Streaming Beats Slow Data and Batch Processing
Across industries, companies are modernizing their data infrastructure to react faster, reduce complexity, and deliver better outcomes. Whether it’s fraud detection in banking, personalized recommendations in retail, or vehicle telemetry in mobility services—real-time data has become essential.
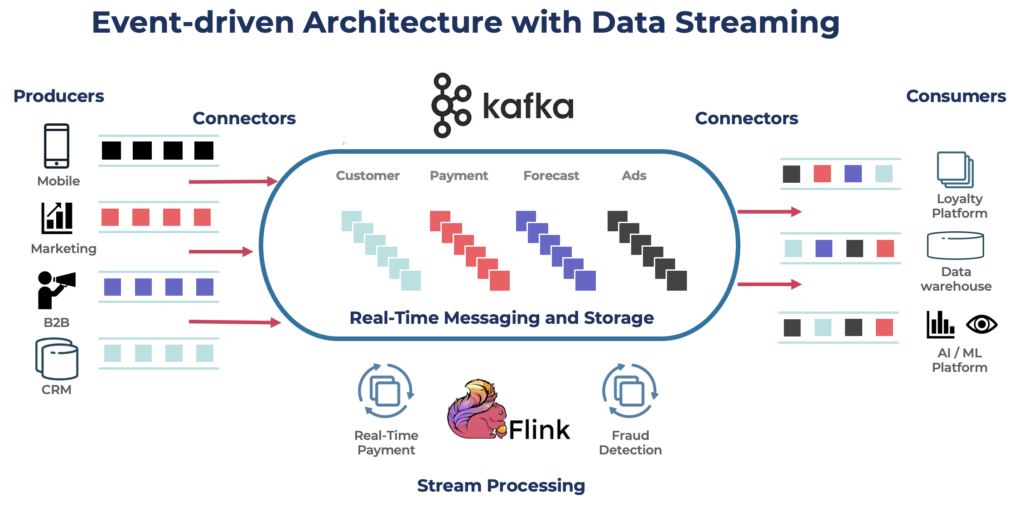
Let’s look at why batch processing falls short in today’s world, and how real-time data streaming changes the game. Each problem outlined below is grounded in real-world challenges seen across industries—from finance and manufacturing to retail and energy.
Corrupted Data and Null Values
Example: A bank’s end-of-day batch job fails because one transaction record has a corrupt timestamp.
In batch systems, a single bad record can poison the entire job. Often, that issue is only discovered hours later when reports are wrong or missing. In real-time streaming systems, bad data can be rejected or rerouted instantly without affecting valid records, leveraging enforcing contracts on the fly.
Thousands of Batch Jobs and Complexity
Example: A large logistics company runs 2,000+ daily batch jobs just to sync inventory and delivery status across regions.
Over time, batch pipelines become deeply entangled and hard to manage. Real-time pipelines are typically simpler and more modular, allowing teams to scale, test, and deploy independently.
Missing Data and Manual Backfilling
Example: A retailer’s point of sale (POS) system goes offline for several hours—sales data is missing from the batch and needs to be manually backfilled.
Batch systems struggle with late-arriving data. Real-time pipelines with built-in buffering and replay capabilities handle delays gracefully, without human intervention.
Data Inconsistencies and Data Copies
Example: A manufacturer reports conflicting production numbers from different analytics systems fed by separate batch jobs.
In batch architectures, multiple data copies lead to discrepancies. A data streaming platform provides a central source of truth via shared topics and schemas to ensure data consistency across real-time, batch and request-response applications.
Exactly-Once Not Guaranteed
Example: A telecom provider reruns a failed billing batch job and accidentally double-charges thousands of customers.
Without exactly-once guarantees, batch retries risk duplication. Real-time data streaming platforms support exactly-once semantics to ensure each record is processed once and only once.
Invalid and Incompatible Schemas
Example: An insurance company adds a new field to customer records, breaking downstream batch jobs that weren’t updated.
Batch systems often have poor schema enforcement. Real-time streaming with a schema registry and data contracts validates data at write time, catching errors early.
Compliance Challenges
Example: A user requests data deletion under GDPR. The data exists in dozens of batch outputs stored across systems.
Data subject requests are nearly impossible to fulfill accurately when data is copied across batch systems. In an event-driven architecture with data streaming, data is processed once, tracked with lineage, and deleted centrally.
Duplicated Data and Small Files
Example: A healthcare provider reruns a batch ETL job after a crash, resulting in duplicate patient records and thousands of tiny files in their data lake.
Data streaming prevents over-processing and file bloats by handling data continuously and appending to optimized storage formats.
High Latency and Outdated Information
Example: A rideshare platform calculates driver incentives daily, based on data that’s already 24 hours old.
By the time decisions are made, they’re irrelevant. Data streaming enables near-instant insights, powering real-time analytics, alerts, and user experiences.
Brittle Pipelines and Manual Fixes
Example: A retailer breaks their holiday sales reporting pipeline due to one minor schema change upstream.
Batch pipelines are fragile and tightly coupled. Real-time systems, with schema evolution support and observability, are more resilient and easier to debug.
Logically and Semantically Invalid Data
Example: A supermarket receives transactions with negative quantities—unnoticed until batch reconciliation fails.
Real-time systems allow inline validation and enrichment, preventing bad data from entering downstream systems.
Exhausted Deduplication and Inaccurate Results
Example: A news app batch-processes user clicks but fails to deduplicate properly, inflating ad metrics.
Deduplication across batch windows is error prone. Data streaming supports sophisticated, stateful deduplication logic in stream processing engines like Kafka Streams or Apache Flink.
Schema Evolution Compatibility Issues
Example: A SaaS company adds optional metadata to an event—but their batch pipeline breaks because downstream systems weren’t ready.
In data streaming, you evolve schemas safely with backward and forward compatibility—ensuring changes don’t break consumers.
Similar Yet Different Datasets
Example: Two teams at a FinTech startup build separate batch jobs for “transactions”, producing similar but subtly different datasets.
Data streaming architectures encourage shared schemas and centralized topics, reducing redundant logic and fragmentation.
Inaccurate Data
Example: A manufacturer bases production forecasts on batch-aggregated sensor data—too late to respond to real-time issues.
Batch introduces delay, distortion, and disconnect. Data streaming delivers accurate, granular, and current data for timely decision-making.
Data Streaming Is the New Standard to Avoid Batch Processing
The limitations of batch processing are no longer acceptable in a digital-first world. From inconsistent data and operational fragility to compliance risk and customer dissatisfaction—batch can’t keep up.
Data streaming isn’t just faster—it’s cleaner, smarter, and more sustainable.
Apache Kafka and Apache Flink make it possible to build a modern, real-time architecture that scales with your business, reduces complexity, and delivers immediate value.
Ready to Modernize?
If you’re exploring the shift from batch to real-time, check out my free book:
📘 The Ultimate Guide to Data Streaming

It’s packed with use cases, architecture patterns, and success stories across industries—designed to help you become a data streaming champion.
Let’s leave batch in the past—and move forward with streaming.
And connect with me on LinkedIn to discuss data streaming! Or join the data streaming community and stay informed about new blog posts by subscribing to my newsletter.
