
As technology landscapes evolve, software vendors must decide whether to specialize in a core area or offer a broad suite of services. Some companies take a highly focused approach, investing deeply in a specific technology, while others attempt to cover multiple use cases by integrating various tools and frameworks. Both strategies have trade-offs, but history has shown that specialization leads to deeper innovation, better performance, and stronger customer trust. This blog explores why focus matters in the context of data streaming software, the challenges of trying to do everything, and how companies that prioritize one thing—data streaming—can build best-in-class solutions that work everywhere.

Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases, including customer stories across all industries.
Specialization vs. Generalization: Why Data Streaming Requires a Focused Approach
Data streaming enables real-time processing of continuous data flows, allowing businesses to act instantly rather than relying on batch updates. This shift from traditional databases and APIs to event-driven architectures has become essential for modern IT landscapes.
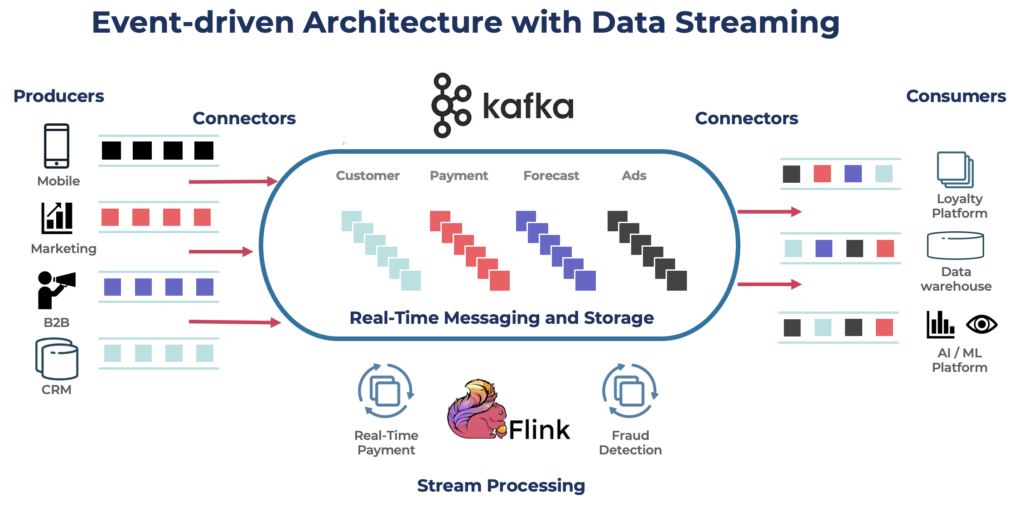
Data streaming is no longer just a technique—it is a new software category. The 2023 Forrester Wave for Streaming Data Platforms confirms its role as a core component of scalable, real-time architectures. Technologies like Apache Kafka and Apache Flink have become industry standards. They power cloud, hybrid, and on-premise environments for real-time data movement and analytics.
Businesses increasingly adopt streaming-first architectures, focusing on:
- Hybrid and multi-cloud streaming for real-time edge-to-cloud integration
- AI-driven analytics powered by continuous optimization and inference using machine learning models
- Streaming data contracts to ensure governance and reliability across the entire data pipeline
- Converging operational and analytical workloads to replace inefficient batch processing and Lambda architecture with multiple data pipelines
The Data Streaming Landscape
As data streaming becomes a core part of modern IT, businesses must choose the right approach: adopt a purpose-built data streaming platform or piece together multiple tools with limitations. Event-driven architectures demand scalability, low latency, cost efficiency, and strict SLAs to ensure real-time data processing meets business needs.
Some solutions may be “good enough” for specific use cases, but they often lack the performance, reliability, and flexibility required for large-scale, mission-critical applications.
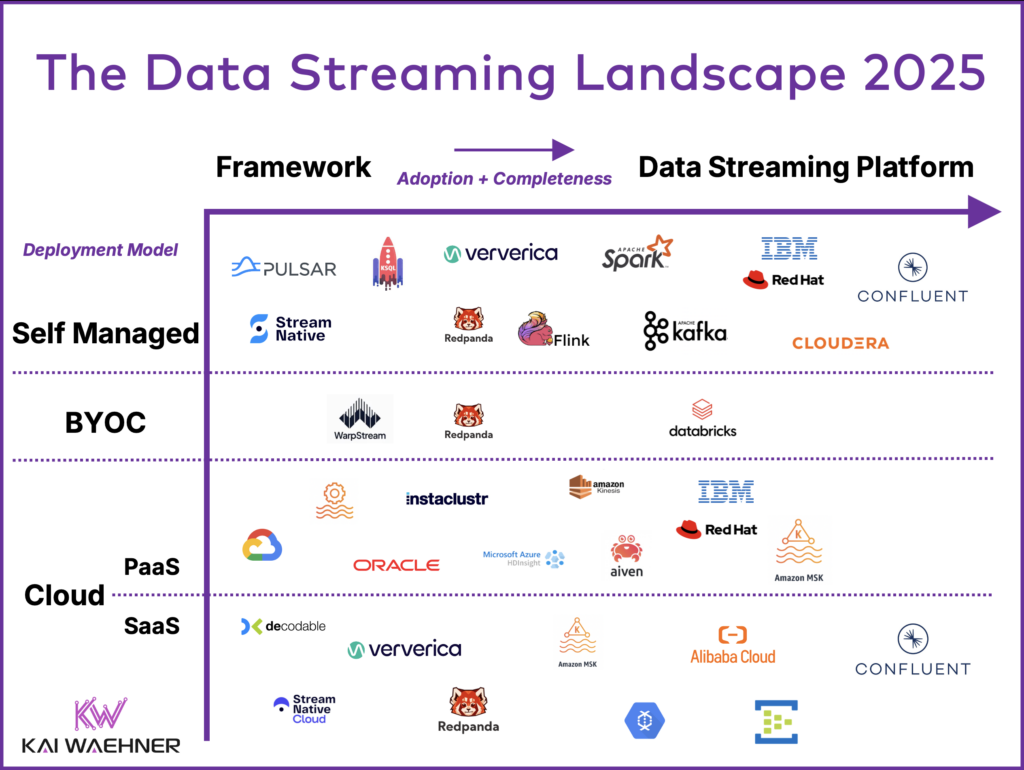
The Data Streaming Landscape highlights the differences—while some vendors provide basic capabilities, others offer a complete Data Streaming Platform (DSP)designed to handle complex, high-throughput workloads with enterprise-grade security, governance, and real-time analytics. Choosing the right platform is essential for staying competitive in an increasingly data-driven world.
The Challenge of Doing Everything
Many software vendors and cloud providers attempt to build a comprehensive technology stack, covering everything from data lakes and AI to real-time data streaming. While this offers customers flexibility, it often leads to overlapping services, inconsistent long-term investment, and complexity in adoption.
A few examples (from the perspective of data streaming solutions).
Amazon AWS: Multiple Data Streaming Services, Multiple Choices
AWS has built the most extensive cloud ecosystem, offering services for nearly every aspect of modern IT, including data lakes, AI, analytics, and real-time data streaming. While this breadth provides flexibility, it also leads to overlapping services, evolving strategies, and complexity in decision-making for customers, resulting in frequent solution ambiguity.
Amazon provides several options for real-time data streaming and event processing, each with different capabilities:
- Amazon SQS (Simple Queue Service): One of AWS’s oldest and most widely adopted messaging services. It’s reliable for basic decoupling and asynchronous workloads, but it lacks native support for real-time stream processing, ordering, replayability, and event-time semantics.
- Amazon Kinesis Data Streams: A managed service for real-time data ingestion and simple event processing, but lacks the full event streaming capabilities of a complete data streaming platform.
- Amazon MSK (Managed Streaming for Apache Kafka): A partially managed Kafka service that mainly focuses on Kafka infrastructure management. It leaves customers to handle critical operational support (MSK does NOT provide SLAs or support for Kafka itself) and misses capabilities such as stream processing, schema management, and governance.
- AWS Glue Streaming ETL: A stream processing service built for data transformations but not designed for high-throughput, real-time event streaming.
- Amazon Flink (formerly Kinesis Data Analytics): AWS’s attempt to offer a fully managed Apache Flink service for real-time event processing, competing directly with open-source Flink offerings.
Each of these services targets different real-time use cases, but they lack a unified, end-to-end data streaming platform. Customers must decide which combination of AWS services to use, increasing integration complexity, operational overhead, and costs.
Strategy Shift and Rebranding with Multiple Product Portfolios
AWS has introduced, rebranded, and developed its real-time streaming services over time:
- Kinesis Data Analytics was originally AWS’s solution for stream processing but was later rebranded as Amazon Flink, acknowledging Flink’s dominance in modern stream processing.
- MSK Serverless was introduced to simplify Kafka adoption but also introduces various additional product limitations and cost challenges.
- AWS Glue Streaming ETL overlaps with Flink’s capabilities, adding confusion about the best choice for real-time data transformations.
As AWS expands its cloud-native services, customers must navigate a complex mix of technologies—often requiring third-party solutions to fill gaps—while assessing whether AWS’s flexible but fragmented approach meets their real-time data streaming needs or if a specialized, fully integrated platform is a better fit.
Google Cloud: Multiple Approaches to Streaming Analytics
Google Cloud is known for its powerful analytics and AI/ML tools, but its strategy in real-time stream processing has been inconsistent:
Customers looking for stream processing in Google Cloud now have three competing services:
- Google Managed Service for Apache Kafka (Google MSK) (a managed Kafka offering). Google MSK is very early stage in the maturity curve and has many limitations.
- Google Dataflow (built on Apache Beam)
- Google Pub/Sub (event messaging)
- Apache Flink on Dataproc (a managed service)
While each of these services has its use cases, they introduce complexity for customers who must decide which option is best for their workloads.
BigQuery Flink was introduced to extend Google’s analytics capabilities into real-time processing but was later discontinued before exiting the preview.
Microsoft Azure: Shifting Strategies in Data Streaming
Microsoft Azure has taken multiple approaches to real-time data streaming and analytics, with an evolving strategy that integrates various tools and services.
- Azure Event Hubs has been a core event streaming service within Azure, designed for high-throughput data ingestion. It supports the Apache Kafka protocol (through Kafka version 3.0, so its feature set lags considerably), making it a flexible choice for (some) real-time workloads. However, it primarily focuses on event ingestion rather than event storage, data processing and integration–additional capabilities of a complete data streaming platform.
- Azure Stream Analytics was introduced as a serverless stream processing solution, allowing customers to analyze data in motion. Despite its capabilities, its adoption has remained limited, particularly as enterprises seek more scalable, open-source alternatives like Apache Flink.
- Microsoft Fabric is now positioned as an all-in-one data platform, integrating business intelligence, data engineering, real-time streaming, and AI. While this brings together multiple analytics tools, it also shifts the focus away from dedicated, specialized solutions like Stream Analytics.
While Microsoft Fabric aims to simplify enterprise data infrastructure, its broad scope means that customers must adapt to yet another new platform rather than continuing to rely on long-standing, specialized services. The combination of Azure Event Hubs, Stream Analytics, and Fabric presents multiple options for stream processing, but also introduces complexity, limitations and increased cost for a combined solution.
Microsoft’s approach highlights the challenge of balancing broad platform integration with long-term stability in real-time streaming technologies. Organizations using Azure must evaluate whether their streaming workloads require deep, specialized solutions or can fit within a broader, integrated analytics ecosystem.
I wrote an entire blog series to demystify what Microsoft Fabric really is.
Instaclustr: Too Many Technologies, Not Enough Depth
Instaclustr has positioned itself as a managed platform provider for a wide array of open-source technologies, including Apache Cassandra, Apache Kafka, Apache Spark, Apache ZooKeeper, OpenSearch, PostgreSQL, Redis, and more. While this broad portfolio offers customers choices, it reflects a horizontal expansion strategy that lacks deep specialization in any one domain.
For organizations seeking help with real-time data streaming, Instaclustr’s Kafka offering may appear to be a viable managed service. However, unlike purpose-built data streaming platforms, Instaclustr’s Kafka solution is just one of many services, with limited investment in stream processing, schema governance, or advanced event-driven architectures.
Because Instaclustr splits its engineering and support resources across so many technologies, customers often face challenges in:
- Getting deep technical expertise for Kafka-specific issues
- Relying on long-term roadmaps and support for evolving Kafka features
- Building integrated event streaming pipelines that require more than basic Kafka infrastructure
This generalist model may be appealing for companies looking for low-cost, basic managed services—but it falls short when mission-critical workloads demand real-time reliability, zero data loss, SLAs, and advanced stream processing capabilities. Without a singular focus, platforms like Instaclustr risk becoming jacks-of-all-trades but masters of none—especially in the demanding world of real-time data streaming.
Cloudera: A Broad Portfolio Without a Clear Focus
Cloudera has adopted a distinct strategy by incorporating various open-source frameworks into its platform, including:
- Apache Kafka (event streaming)
- Apache Flink (stream processing)
- Apache Iceberg (data lake table format)
- Apache Hadoop (big data storage and batch processing)
- Apache Hive (SQL querying)
- Apache Spark (batch and near real-time processing and analytics)
- Apache NiFi (data flow management)
- Apache HBase (NoSQL database)
- Apache Impala (real-time SQL engine)
- Apache Pulsar (event streaming, via a partnership with StreamNative)
While this provides flexibility, it also introduces significant complexity:
- Customers must determine which tools to use for specific workloads.
- Integration between different components is not always seamless.
- The broad scope makes it difficult to maintain deep expertise in each area.
Rather than focusing on one core area, Cloudera’s strategy appears to be adding whatever is trending in open source, which can create challenges in long-term support and roadmap clarity.
Splunk: Repeated Attempts at Data Streaming
Splunk, known for log analytics, has tried multiple times to enter the data streaming market:
Initially, Splunk built a proprietary streaming solution that never gained widespread adoption.
Later, Splunk acquired Streamlio to leverage Apache Pulsar as its streaming backbone.This Pulsar-based strategy ultimately failed, leading to a lack of a clear real-time streaming offering.
Splunk’s challenges highlight a key lesson: successful data streaming requires long-term investment and specialization, not just acquisitions or technology integrations.
Why a Focused Approach Works Better for Data Streaming
Some vendors take a more specialized approach, focusing on one core capability and doing it better than anyone else. For data streaming, Confluent became the leader in this space by focusing on improving the vision of a complete data streaming platform.
Confluent: Focused on Data Streaming, Built for Everywhere
At Confluent, the focus is clear: real-time data streaming. Unlike many other vendors and the cloud providers that offer fragmented or overlapping services, Confluent specializes in one thing and ensures it works everywhere:
- Cloud: Deploy across AWS, Azure, and Google Cloud with deep native integrations.
- On-Premise: Enterprise-grade deployments with full control over infrastructure.
- Edge Computing: Real-time streaming at the edge for IoT, manufacturing, and remote environments.
- Hybrid Cloud: Seamless data streaming across edge, on-prem, and cloud environments.
- Multi-Region: Built-in disaster recovery and globally distributed architectures.
More Than Just “The Kafka Company”
While Confluent is often recognized as “the Kafka company,” it has grown far beyond that. Today, Confluent is a complete data streaming platform, combining Apache Kafka for event streaming, Apache Flink for stream processing, and many additional components for data integration, governance and security to power critical workloads.
However, Confluent remains laser-focused on data streaming—it does NOT compete with BI, AI model training, search platforms, or databases. Instead, it integrates and partners with best-in-class solutions in these domains to ensure businesses can seamlessly connect, process, and analyze real-time data within their broader IT ecosystem.
The Right Data Streaming Platform for Every Use Case
Confluent is not just one product—it matches the specific needs, SLAs, and cost considerations of different streaming workloads:
- Fully Managed Cloud (SaaS)
- Dedicated and multi-tenant Enterprise Clusters: Low latency, strict SLAs for mission-critical workloads.
- Freight Clusters: Optimized for high-volume, relaxed latency requirements.
- Bring Your Own Cloud (BYOC)
- WarpStream: Bring Your Own Cloud for flexibility and cost efficiency.
- Self-Managed
- Confluent Platform: Deploy anywhere—customer cloud VPC, on-premise, at the edge, or across multi-region environments.
Confluent is built for organizations that require more than just “some” data streaming—it is for businesses that need a scalable, reliable, and deeply integrated event-driven architecture. Whether operating in a cloud, hybrid, or on-premise environment, Confluent ensures real-time data can be moved, processed, and analyzed seamlessly across the enterprise.
By focusing only on data streaming, Confluent ensures seamless integration with best-in-class solutions across both operational and analytical workloads. Instead of competing across multiple domains, Confluent partners with industry leaders to provide a best-of-breed architecture that avoids the trade-offs of an all-in-one compromise.
Deep Integrations Across Key Ecosystems
A purpose-built data streaming platform plays well with cloud providers and other data platforms. A few examples:
- Cloud Providers (AWS, Azure, Google Cloud): While all major cloud providers offer some data streaming capabilities, Confluent takes a different approach by deeply integrating into their ecosystems. Confluent’s managed services can be:
- Consumed via cloud credits through the cloud provider marketplace
- Integrated natively into cloud provider’s security and networking services
- Fully-managed out-of-the-box connectivity to cloud provider services like object storage, lakehouses, and databases
- MongoDB: A leader in NoSQL and operational workloads, MongoDB integrates with Confluent via Kafka-based change data capture (CDC), enabling real-time event streaming between transactional databases and event-driven applications.
- Databricks: A powerhouse in AI and analytics, Databricks integrates bi-directionally with Confluent via Kafka and Apache Spark, or object storage and the open table format from Iceberg / Delta Lake via Tableflow. This enables businesses to stream data for AI model training in Databricks and perform real-time model inference directly within the streaming platform.
Rather than attempting to own the entire data stack, Confluent specializes in data streaming and integrates seamlessly with the best cloud, AI, and database solutions.
Beyond the Leader: Specialized Vendors Shaping Data Streaming
Confluent is not alone in recognizing the power of focus. A handful of other vendors have also chosen to specialize in data streaming—each with their own vision, strengths, and approaches.
WarpStream, recently acquired by Confluent, is a Kafka-compatible infrastructure solution designed for Bring Your Own Cloud (BYOC) environments. It re-architects Kafka by running the protocol directly on cloud object storage like Amazon S3, removing the need for traditional brokers or persistent compute. This model dramatically reduces operational complexity and cost—especially for high-ingest, elastic workloads. While WarpStream is now part of the Confluent portfolio, it remains a distinct offering focused on lightweight, cost-efficient Kafka infrastructure.
StreamNative is the commercial steward of Apache Pulsar, aiming to provide a unified messaging and streaming platform. Built for multi-tenancy and geo-replication, it offers some architectural differentiators, particularly in use cases where separation of compute and storage is a must. However, adoption remains niche, and the surrounding ecosystem still lacks maturity and standardization.
Redpanda positions itself as a Kafka-compatible alternative with a focus on performance, especially in low-latency and resource-constrained environments. Its C++ foundation and single-binary architecture make it appealing for edge and latency-sensitive workloads. Yet, Redpanda still needs to mature in areas like stream processing, integrations, and ecosystem support to serve as a true platform.
AutoMQ re-architects Apache Kafka for the cloud by separating compute and storage using object storage like S3. It aims to simplify operations and reduce costs for high-throughput workloads. Though fully Kafka-compatible, AutoMQ concentrates on infrastructure optimization and currently lacks broader platform capabilities like governance, processing, or hybrid deployment support.
Bufstream is experimenting with lightweight approaches to real-time data movement using modern developer tooling and APIs. While promising in niche developer-first scenarios, it has yet to demonstrate scalability, production maturity, or a robust ecosystem around complex stream processing and governance.
Ververica focuses on stream processing with Apache Flink. It offers Ververica Platform to manage Flink deployments at scale, especially on Kubernetes. While it brings deep expertise in Flink operations, it does not provide a full data streaming platform and must be paired with other components, like Kafka for ingestion and delivery.
Great Ideas Are Born From Market Pressure
Each of these companies brings interesting ideas to the space. But building and scaling a complete, enterprise-grade data streaming platform is no small feat. It requires not just infrastructure, but capabilities for processing, governance, security, global scale, and integrations across complex environments.
That’s where Confluent continues to lead—by combining deep technical expertise, a relentless focus on one problem space, and the ability to deliver a full platform experience across cloud, on-prem, and hybrid deployments.
In the long run, the data streaming market will reward not just technical innovation, but consistency, trust, and end-to-end excellence. For now, the message is clear: specialization matters—but execution matters even more. Let’s see where the others go.
How Customers Benefit from Specialization
A well-defined focus provides several advantages for customers, ensuring they get the right tool for each job without the complexity of navigating overlapping services.
- Clarity in technology selection: No need to evaluate multiple competing services; purpose-built solutions ensure the right tool for each use case.
- Deep technical investment: Continuous innovation focused on solving specific challenges rather than spreading resources thin.
- Predictable long-term roadmap: Stability and reliability with no sudden service retirements or shifting priorities.
- Better performance and reliability: Architectures optimized for the right workloads through the deep experience in the software category.
- Seamless ecosystem integration: Works natively with leading cloud providers and other data platforms for a best-of-breed approach.
- Deployment flexibility: Not bound to a single environment like one cloud provider; businesses can run workloads on-premise, in any cloud, at the edge, or across hybrid environments.
Rather than adopting a broad but shallow set of solutions, businesses can achieve stronger outcomes by choosing vendors that specialize in one core competency and deliver it everywhere.
Why Deep Expertise Matters: Supporting 24/7, Mission-Critical Data Streaming
For mission-critical workloads—where downtime, data loss, and compliance failures are not an option—deep expertise is not just an advantage, it is a necessity.
Data streaming is a high-performance, real-time infrastructure that requires continuous reliability, strict SLAs, and rapid response to critical issues. When something goes wrong at the core of an event-driven architecture—whether in Apache Kafka, Apache Flink, or the surrounding ecosystem—only specialized vendors with proven expertise can ensure immediate, effective solutions.
The Challenge with Generalist Cloud Services
Many cloud providers offer some level of data streaming, but their approach is different from a dedicated data streaming platform. Take Amazon MSK as an example:
- Amazon MSK provides managed Kafka clusters, but does NOT offer Kafka support itself. If an issue arises deep within Kafka, customers are responsible for troubleshooting it—or must find external experts to resolve the problem.
- The terms and conditions of Amazon MSK explicitly exclude Kafka support, meaning that, for mission-critical applications requiring uptime guarantees, compliance, and regulatory alignment, MSK is not a viable choice.
- This lack of core Kafka support poses a serious risk for enterprises relying on event streaming for financial transactions, real-time analytics, AI inference, fraud detection, and other high-stakes applications.
For companies that cannot afford failure, a data streaming vendor with direct expertise in the underlying technology is essential.
Why Specialized Vendors Are Essential for Mission-Critical Workloads
A complete data streaming platform is much more than a hosted Kafka cluster or a managed Flink service. Specialized vendors like Confluent offer end-to-end operational expertise, covering:
- 24/7 Critical Support: Direct access to Kafka and Flink experts, ensuring immediate troubleshooting for core-level issues.
- Guaranteed SLAs: Strict uptime commitments, ensuring that mission-critical applications are always running.
- No Data Loss Architecture: Built-in replication, failover, and durability to prevent business-critical data loss.
- Security & Compliance: Encryption, access control, and governance features designed for regulated industries.
- Professional Services & Advisory: Best practices, architecture reviews, and operational guidance tailored for real-time streaming at scale.
This level of deep, continuous investment in operational excellence separates a general-purpose cloud service from a true data streaming platform.
The Power of Specialization: Deep Expertise Beats Broad Offerings
Software vendors will continue expanding their offerings, integrating new technologies, and launching new services. However, focus remains a key differentiator in delivering best-in-class solutions, especially for operational systems with critical SLAs—where low latency, 24/7 uptime, no data loss, and real-time reliability are non-negotiable.
For companies investing in strategic data architectures, choosing a vendor with deep expertise in one core technology—rather than one that spreads across multiple domains—ensures stability, predictable performance, and long-term success.
In a rapidly evolving technology landscape, clarity, specialization, and seamless integration are the foundations of lasting innovation. Businesses that prioritize proven, mission-critical solutions will be better equipped to handle the demands of real-time, event-driven architectures at scale.
How do you see the world of software? Better to specialize or become an allrounder? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter. And download my free book about data streaming use cases.






