Fraud Detection with Apache Kafka, KSQL and Apache Flink
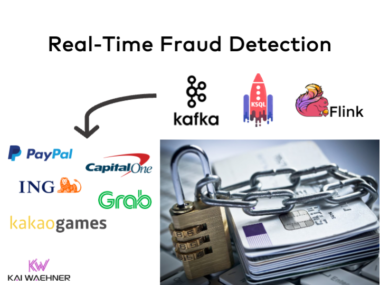
Fraud detection becomes increasingly challenging in a digital world across all industries. Real-time data processing with Apache Kafka became the de facto standard to correlate and prevent fraud continuously before it happens. This blog post explores case studies for fraud prevention from companies such as Paypal, Capital One, ING Bank, Grab, and Kakao Games that leverage stream processing technologies like Kafka Streams, KSQL, and Apache Flink.