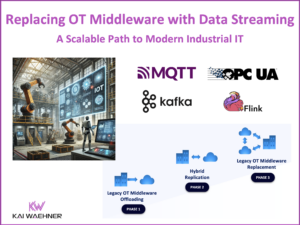
Data Streaming as the Technical Foundation for a B2B Marketplace
A B2B data marketplace empowers businesses to exchange, monetize, and leverage real-time data through self-service platforms featuring subscription management, usage-based billing, and secure data sharing. Built on data streaming technologies like Apache Kafka and Flink, these marketplaces deliver scalable, event-driven architectures for seamless integration, real-time processing, and compliance. By exploring successful implementations like AppDirect, this post highlights how organizations can unlock new revenue streams and foster innovation with modern data marketplace solutions.