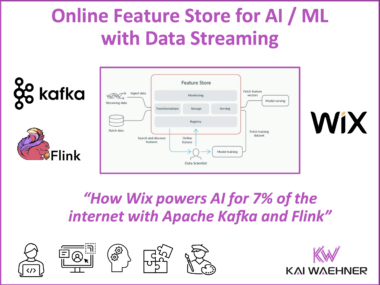
Online Feature Store for AI and Machine Learning with Apache Kafka and Flink
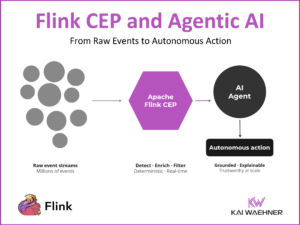
Real-time personalization requires more than just smart models. It demands fresh data, fast processing, and scalable infrastructure. This blog post explores how Wix.com rebuilt its online feature store using Apache Kafka and Flink, turning their AI architecture into a real-time powerhouse that supports personalized experiences for millions of users.