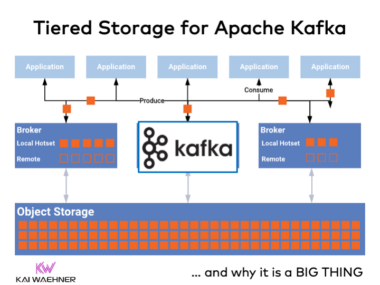
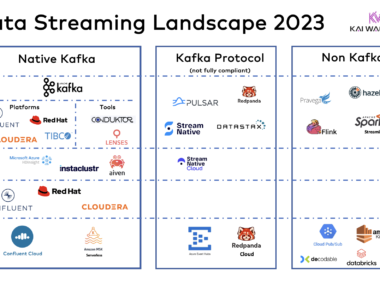
JavaScript, Node.js and Apache Kafka for Full-Stack Data Streaming
JavaScript is a pivotal technology for web applications. With the emergence of Node.js, JavaScript became relevant for both client-side and server-side development, enabling a full-stack development approach with a single programming language. Both Node.js and Apache Kafka are built around event-driven architectures, making them naturally compatible for real-time data streaming. This blog post explores open-source JavaScript Clients for Apache Kafka and discusses the trade-offs and limitations of JavaScript Kafka producers and consumers compared to stream processing technologies such as Kafka Streams or Apache Flink.