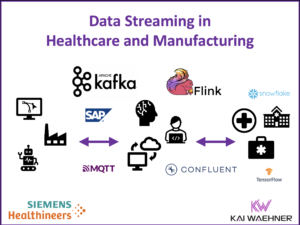
Comparison of Open Source IoT Integration Frameworks
Comparison of Open Source IoT Integration Frameworks such as Eclipse Kura (+ Apache Camel), Node-RED, Flogo, Apache Nifi, StreamSets, and others… (slide and video recording)
Browsing Tag