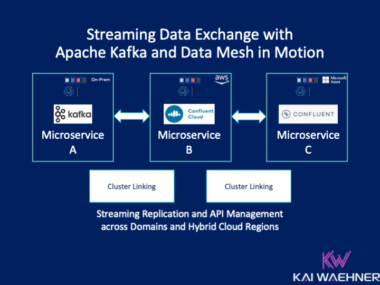
Best Practices for Building a Cloud-Native Data Warehouse or Data Lake
The concepts and architectures of a data warehouse, a data lake, and data streaming are complementary to solving business problems. Unfortunately, the underlying technologies are often misunderstood, overused for monolithic and inflexible architectures, and pitched for wrong use cases by vendors. Let’s explore this dilemma in a blog series. This is part 5: Best Practices for Building a Cloud-Native Data Warehouse or Data Lake.