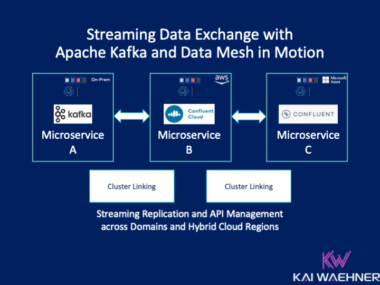
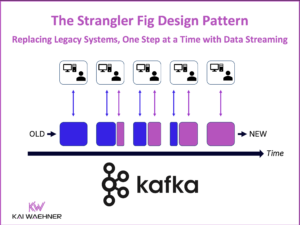
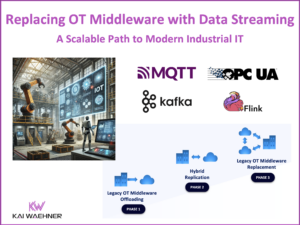
When NOT to use Apache Kafka?
Apache Kafka is the de facto standard for event streaming to process data in motion. This blog post explores when NOT to use Apache Kafka. What use cases are not a good fit for Kafka? What limitations does Kafka have? How to qualify Kafka out as it is not the right tool for the job?