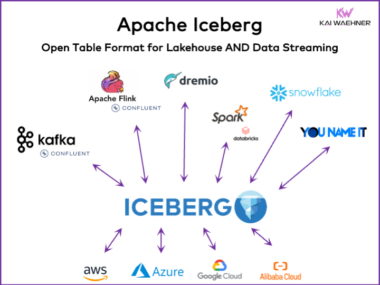
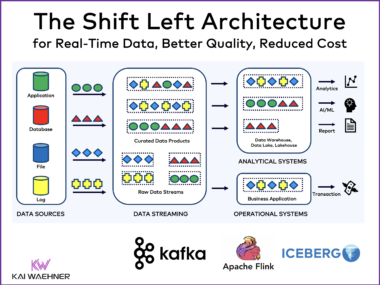
Apache Flink: Overkill for Simple, Stateless Stream Processing and ETL?
Discover when Apache Flink is the right tool for your stream processing needs. Explore its role in stateful and stateless processing, the advantages of serverless Flink SaaS solutions like Confluent Cloud, and how it supports advanced analytics and real-time data integration together with Apache Kafka. Dive into the trade-offs, deployment options, and strategies for leveraging Flink effectively across cloud, on-premise, and edge environments, and when to use Kafka Streams or Single Message Transforms (SMT) within Kafka Connect for ETL instead of Flink.