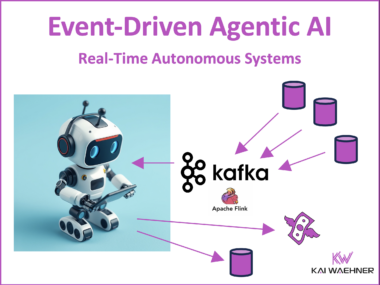
How Apache Kafka and Flink Power Event-Driven Agentic AI in Real Time
Agentic AI marks a major evolution in artificial intelligence—shifting from passive analytics to autonomous, goal-driven systems capable of planning and executing complex tasks in real time. To function effectively, these intelligent agents require immediate access to consistent, trustworthy data. Traditional batch processing architectures fall short of this need, introducing delays, data staleness, and rigid workflows. This blog post explores why event-driven architecture (EDA)—powered by Apache Kafka and Apache Flink—is essential for building scalable, reliable, and adaptive AI systems. It introduces key concepts such as Model Context Protocol (MCP) and Google’s Agent-to-Agent (A2A) protocol, which are redefining interoperability and context management in multi-agent environments. Real-world use cases from finance, healthcare, manufacturing, and more illustrate how Kafka and Flink provide the real-time backbone needed for production-grade Agentic AI. The post also highlights why popular frameworks like LangChain and LlamaIndex must be complemented by robust streaming infrastructure to support stateful, event-driven AI at scale.