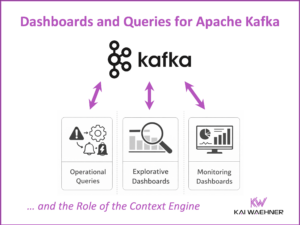
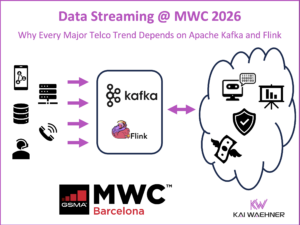
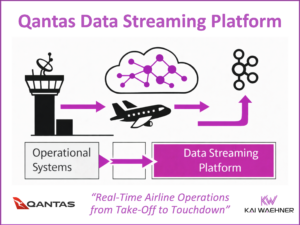
Real-Time GenAI with RAG using Apache Kafka and Flink to Prevent Hallucinations
How do you prevent hallucinations from large language models (LLMs) in GenAI applications? LLMs need real-time, contextualized, and trustworthy data to generate the most reliable outputs. This blog post explains how RAG and a data streaming platform with Apache Kafka and Flink make that possible. A lightboard video shows how to build a context-specific real-time RAG architecture. Also, learn how the travel agency Expedia leverages data streaming with Generative AI using conversational chatbots to improve the customer experience and reduce the cost of service agents.