Modernizing OT Middleware: The Shift to Open Industrial IoT Architectures with Data Streaming
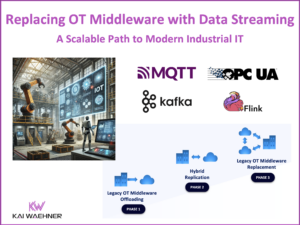
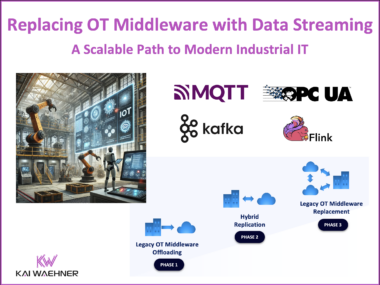
Legacy OT middleware is struggling to keep up with real-time, scalable, and cloud-native demands. As industries shift toward event-driven architectures, companies are replacing vendor-locked, polling-based systems with Apache Kafka, MQTT, and OPC-UA for seamless OT-IT integration. Kafka serves as the central event backbone, MQTT enables lightweight device communication, and OPC-UA ensures secure industrial data exchange. This approach enhances real-time processing, predictive analytics, and AI-driven automation, reducing costs and unlocking scalable, future-proof architectures.