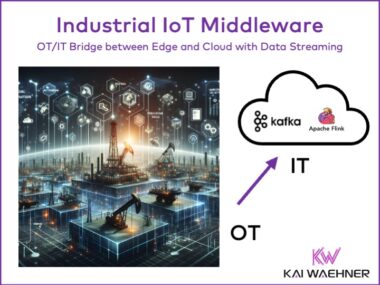
Industrial IoT Middleware for Edge and Cloud OT/IT Bridge powered by Apache Kafka and Flink
As industries continue to adopt digital transformation, the convergence of Operational Technology (OT) and Information Technology (IT) has become essential. The OT/IT Bridge is a key concept in industrial automation to connect real-time operational processes with business-oriented IT systems ensuring seamless data flow and coordination. By leveraging Industrial IoT middleware and data streaming technologies like Apache Kafka and Flink, businesses can achieve a unified approach to managing both production processes and higher-level business operations to drive greater efficiency, predictive maintenance, and streamlined decision-making.