
5G
The energy industry is changing from system-centric to smaller-scale and distributed smart grids and microgrids. These smart grids require a flexible, scalable, elastic, and reliable

The energy industry is changing from system-centric to smaller-scale and distributed smart grids and microgrids. These smart grids require a flexible, scalable, elastic, and reliable

The Fourth Industrial Revolution (also known as Industry 4.0) is the ongoing automation of traditional manufacturing and industrial practices, using modern smart technology. Event Streaming
Real-Time Locating System (RTLS) enables identifying and tracking the location of assets or people in real-time. This blog post explores the use cases for RTLS,
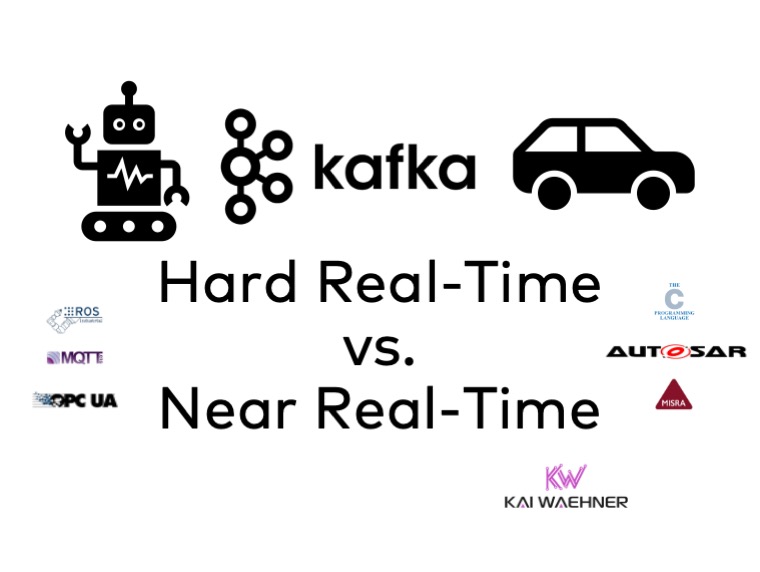
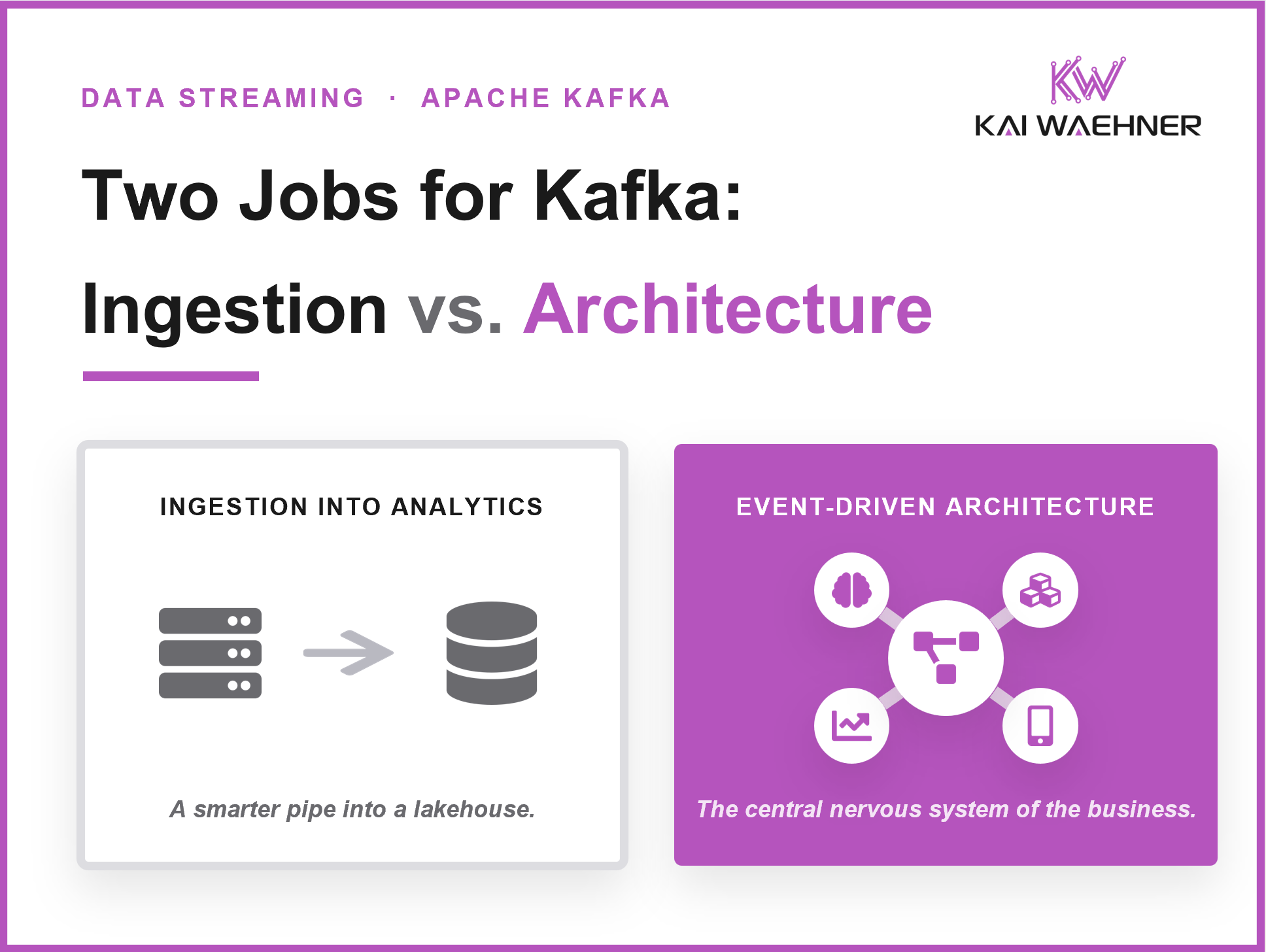
Apache Kafka is NOT hard real-time in Industrial IoT or vehicles (such as autonomous cars) but integrates the OT/IT world for near real-time data correlation

TOP 5 Event Streaming Architectures and Use Cases for 2021: Edge deployments, hybrid and multi-cloud architectures, service mesh-based microservices, streaming machine learning, and cybersecurity.

Supply Chain optimization leveraging Event Streaming with Apache Kafka. See real-world use cases and architectures from Walmart, BMW, Porsche, and other enterprises to improve the

Postmodern ERP represents the next generation of ERP architectures. It is real-time, scalable, and open by using a combination of open source technologies and proprietary
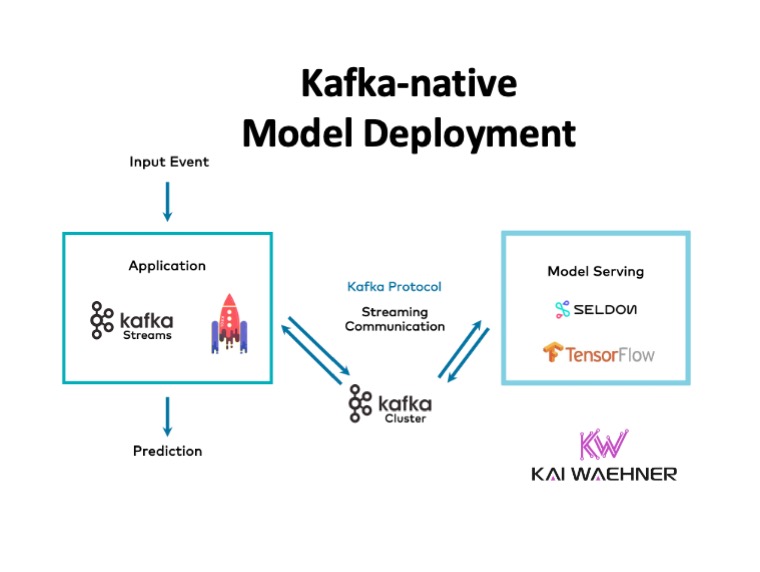
Apache Kafka became the de facto standard for event streaming across the globe and industries. Machine Learning (ML) includes model training on historical data and

Event Streaming is happening all over the world. This blog post explores real-life examples across industries for use cases and architectures leveraging Apache Kafka. Learn
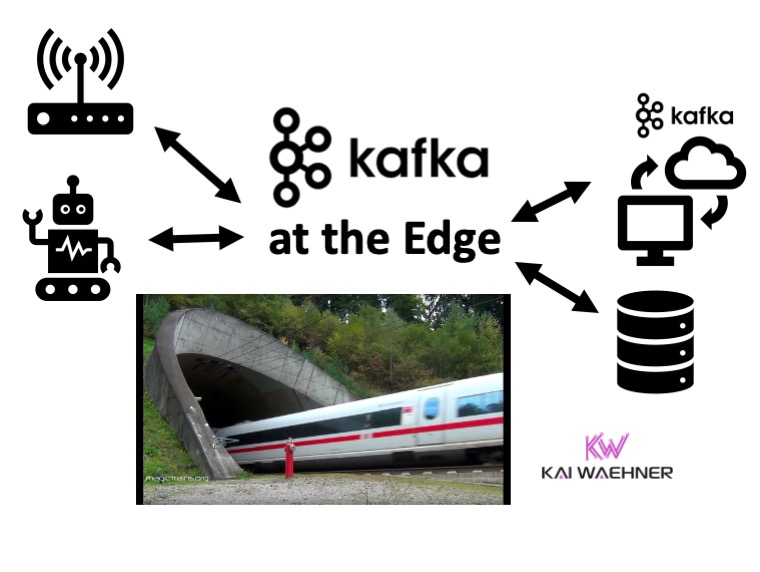
Use cases and architectures for Kafka deployments at the edge, including retail stores, cell towers, trains, small factories, restaurants… Hardware and software components to realize




You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information