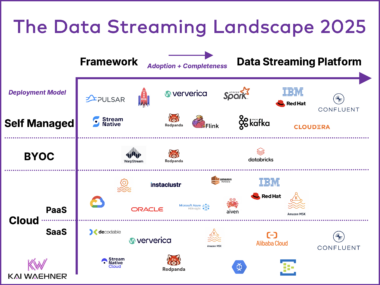
Fully Managed (SaaS) vs. Partially Managed (PaaS) Cloud Services for Data Streaming with Kafka and Flink
The cloud revolution has reshaped how businesses deploy and manage data streaming with solutions like Apache Kafka and Flink. Distinctions between SaaS and PaaS models significantly impact scalability, cost, and operational complexity. Bring Your Own Cloud (BYOC) expands the options, giving businesses greater flexibility in cloud deployment. Misconceptions around terms like “serverless” highlight the need for deeper analysis to avoid marketing pitfalls. This blog explores deployment options, enabling informed decisions tailored to your data streaming needs.