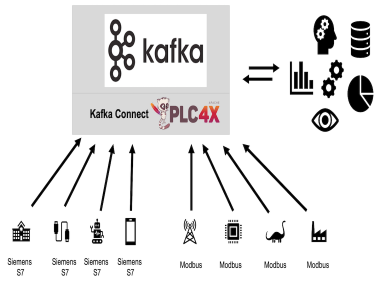
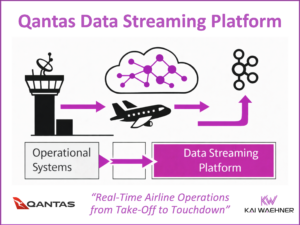
The State of Data Streaming for Gaming
This blog post explores the state of data streaming for the gaming industry, including customer stories from Kakao Games, Mobile Premier League (MLP), Demonware / Blizzard, and more. A complete slide deck and on-demand video recording are included.