How Siemens Healthineers Leverages Data Streaming with Apache Kafka and Flink in Manufacturing and Healthcare
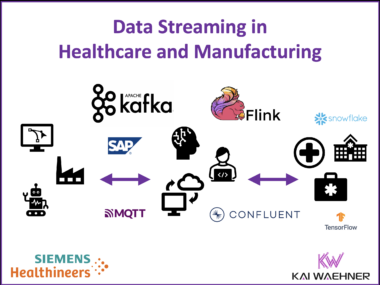
Siemens Healthineers, a global leader in medical technology, delivers solutions that improve patient outcomes and empower healthcare professionals. A significant aspect of their technological prowess lies in their use of data streaming to unlock real-time insights and optimize processes. This blog post explores how Siemens Healthineers uses data streaming with Apache Kafka and Flink, their cloud-focused technology stack, and the use cases that drive tangible business value, such as real-time logistics, robotics, SAP ERP integration, AI/ML, and more.