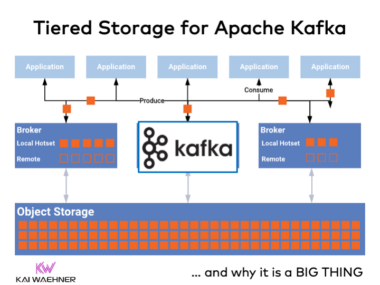
Virta’s Electric Vehicle (EV) Charging Platform with Real-Time Data Streaming: Scalability for Large Charging Businesses
The rise of Electric Vehicles (EVs) demands a scalable, efficient charging network—but challenges like fluctuating demand, complex billing, and real-time availability updates must be addressed. Virta, a global leader in smart EV charging, is tackling these issues with real-time data streaming. By leveraging Apache Kafka and Confluent Cloud, Virta enhances energy distribution, enables predictive maintenance, and supports dynamic pricing. This approach optimizes operations, improves user experience, and drives sustainability. Discover how real-time data streaming is shaping the future of EV charging and enabling intelligent, scalable infrastructure.