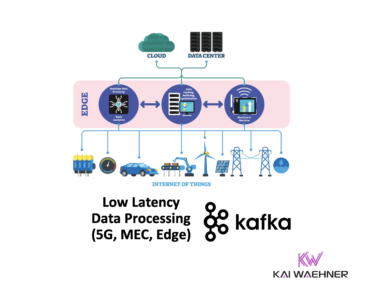
Real-World Deployments of Kafka in the Automotive Industry
Apache Kafka became the central nervous system of many applications in various different areas related to the automotive industry. This blog post explores various real-world deployments across several fields including connected vehicles, smart manufacturing, and innovative mobility services. Examples include car makers such as Audi, BMW, Porsche, and Tesla, plus a few mobility services such as Uber, Lyft, and Here Technologies.